
Abstract
Multi-modal retrieval is emerging as a new search paradigm that enables seamless information retrieval from various types of media. For example, users can simply snap a movie poster to search for relevant reviews and trailers. The mainstream solution to the problem is to learn a set of mapping functions that project data from different modalities into a common metric space in which conventional indexing schemes for high-dimensional space can be applied. Since the effectiveness of the mapping functions plays an essential role in improving search quality, in this paper, we exploit deep learning techniques to learn effective mapping functions. In particular, we first propose a general learning objective that effectively captures both intramodal and intermodal semantic relationships of data from heterogeneous sources. Given the general objective, we propose two learning algorithms to realize it: (1) an unsupervised approach that uses stacked auto-encoders and requires minimum prior knowledge on the training data and (2) a supervised approach using deep convolutional neural network and neural language model. Our training algorithms are memory efficient with respect to the data volume. Given a large training dataset, we split it into mini-batches and adjust the mapping functions continuously for each batch. Experimental results on three real datasets demonstrate that our proposed methods achieve significant improvement in search accuracy over the state-of-the-art solutions.


















Similar content being viewed by others


Notes
The binary value for each dimension indicates whether the corresponding tag appears or not.
We tried both the Sigmoid function and ReLU activation function for s(). ReLU offers better performance.
In our experiment, we use the parameters trained by Caffe [18] to initialize the AlexNet to accelerate the training. We use Gensim (http://radimrehurek.com/gensim/) to train the skip-gram model with the dimension of word vectors being 100.
The code and parameter configurations for CVH and CMSSH are available online at http://www.cse.ust.hk/~dyyeung/code/mlbe.zip. The code for LCMH is provided by the authors. Parameters are set according to the suggestions provided in the paper.
The last layer with two units is for visualization purpose, such that the latent features could be showed in a 2D space.
Here, recall \(r = \frac{1}{\# all~relevant~results}\approx 0\).
References
Bengio, Y.: Practical recommendations for gradient-based training of deep architectures. CoRR arXiv:1206.5533 (2012)
Bengio, Y., Ducharme, R., Vincent, P., Janvin, C.: A neural probabilistic language model. J. Mach. Learn. Res. 3, 1137–1155 (2003)
Bengio, Y., Courville, A.C., Vincent, P.: Representation learning: a review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 35(8), 1798–1828 (2013)
Bronstein, M.M., Bronstein, A.M., Michel, F., Paragios, N.: Data fusion through cross-modality metric learning using similarity- sensitive hashing. In: The Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, pp. 3594–3601. IEEE Computer Society (2010)
Chua, T.S., Tang, J., Hong, R., Li, H., Luo, Z., Zheng, Y.T.: Nus-wide: a real-world web image database from national university of singapore. In: Proceedings of ACM Conference on Image and Video Retrieval (CIVR’09), Santorini, Greece (2009)
Ciresan, D.C., Meier, U., Gambardella, L.M., Schmidhuber, J.: Deep Big Multilayer Perceptrons for Digit Recognition, vol. 7700. Springer, Berlin (2012)
Dean, J., Corrado, G., Monga, R., Chen, K., Devin, M., Le, Q.V., Mao, M.Z., Ranzato, M., Senior, A.W., Tucker, P.A., Yang, K., Ng, A.Y.: Large scale distributed deep networks. In: Bartlett, P.L., Pereira, F.C.N., Burges, C.J.C., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, Nevada, United States, pp. 1232–1240 (2012)
Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N., Tzeng, E., Darrell, T.: Decaf: a deep convolutional activation feature for generic visual recognition. arXivpreprint arXiv:1310.1531 (2013)
Frome, A., Corrado, G.S., Shlens, J., Bengio, S., Dean, J., Ranzato, M.,Mikolov,T.: Devise: a deep visual-semantic embedding model. In: Burges, C.J.C., Bottou, L., Ghahramani, Z., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems 26: 27th AnnualConference on Neural Information Processing Systems 2013, Lake Tahoe, Nevada, United States, pp. 2121–2129 (2013)
Girshick, R.B., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR 2014, Columbus, OH, USA, pp. 580–587 (2014)
Gong, Y., Jia, Y., Leung, T., Toshev, A., Ioffe, S.: Deep convolutional ranking for multilabel image annotation. CoRR arXiv:1312.4894 (2013a)
Gong, Y., Lazebnik, S., Gordo, A., Perronnin, F.: Iterative quantization: a procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 35(12), 2916–2929 (2013b)
Goroshin, R., LeCun, Y.: Saturating auto-encoder. CoRR arXiv:1301.3577 (2013)
Hinton, G.: A Practical Guide to Training Restricted Boltzmann Machines. In: Montavon, G., Müller, K-R. (eds.) Neural Networks: Tricks of the Trade-Second Edition, Lecture Notes in Computer Science, vol 7700, pp. 599–619. Springer (2012)
Hinton, G., Salakhutdinov, R.: Reducing the dimensionality of data with neural networks. Science 313(5786), 504–507 (2006)
Hjaltason, G.R., Samet, H.: Index-driven similarity search in metric spaces. ACM Trans. Database Syst. 28(4), 517–580 (2003)
Huiskes, M.J., Lew, M.S.: The mir flickr retrieval evaluation. In: Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, MIR ’08, Vancouver, British Columbia, Canada, pp. 39–43. ACM, New York, USA (2008)
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R.B., Guadarrama, S., Darrell, T.: Caffe: Convolutional architecture for fast feature embedding. In: Hua, K.A., Rui, Y., Steinmetz, R., Hanjalic, A., Natsev, A., Zhu, W. (eds.) Proceedings of the ACM International Conference on Multimedia, MM ’14, Orlando, FL, USA, pp. 675–678. ACM (2014)
Krizhevsky, A.: Learning Multiple Layers of Features from Tiny Images. Tech. rep (2009)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25, 1106–1114 (2012)
Kumar, S., Udupa, R.: Learning hash functions for cross-viewsimilarity search. In: Walsh, T. (ed.) Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, pp. 1360–1365. IJCAI/AAAI (2011)
LeCun, Y., Bottou, L., Orr, G., Müller, K.: Efficient backProp. In: Orr, G., Müller, K.R. (eds.) Neural Networks: Tricks of the Trade, Lecture Notes in Computer Science, chap 2, vol. 1524, pp. 9–50. Springer, Berlin (1998)
Liu, D., Hua, X., Yang, L., Wang, M., Zhang, H.: Tag ranking. In: Proceedings of the 18th International Conference on World Wide Web, WWW 2009, Madrid, Spain, pp. 351–360, (2009). doi:10.1145/1526709.1526757
Liu, W., Wang, J., Kumar, S., Chang, S.F.: Hashing with graphs. In: Getoor, L., Scheffer, T. (eds.) Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, pp. 1–8. Omnipress (2011)
Lu, X., Wu, F., Tang, S., Zhang, Z., He, X., Zhuang, Y.: A low rank structural large margin method for cross-modal ranking. In: SIGIR, pp. 433–442 (2013)
van der Maaten, L.: Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 15, 3221–3245 (2014)
Manning, C.D., Raghavan, P., Schütze, H.: Introduction to Information Retrieval. Cambridge University Press, Cambridge (2008)
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., Ng, A.Y.: Multimodal deep learning. In: Getoor, L., Scheffer, T. (eds.) Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, pp. 689–696. Omnipress (2011)
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., Ng, A.Y.: Multimodal deep learning. In: Getoor, L., Scheffer, T. (eds.) Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, pp. 689–696. Omnipress (2011)
Rasiwasia, N., Pereira, J.C., Coviello, E., Doyle, G., Lanckriet, G.R.G., Levy, R., Vasconcelos, N.: A new approach to cross-modal multimedia retrieval. In: ACM Multimedia, pp. 251–260 (2010)
Rifai, S., Vincent, P., Muller, X., Glorot, X., Bengio, Y.: Contractive auto-encoders: explicit invariance during feature extraction. In: ICML, pp. 833–840 (2011)
Salakhutdinov, R., Hinton, G.E.: Semantic hashing. Int. J. Approx. Reason. 50(7), 969–978 (2009)
Socher, R., Manning, C.D.: Deep learning for NLP (without magic). In: Human Language Technologies: Conference of the North American Chapter of the Association of Computational Linguistics, Proceedings, pp. 1–3. Westin Peachtree Plaza Hotel, Atlanta, Georgia, USA (2013)
Socher, R., Pennington, J., Huang, E.H., Ng, A.Y., Manning, C.D.: Semi-supervised recursive autoencoders for predicting sentimentdistributions. In: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, John McIntyre Conference Centre, Edinburgh, UK, A meeting of SIGDAT, a Special Interest Group of the ACL, pp. 151–161. ACL (2011)
Song, J., Yang, Y., Huang, Z., Shen, H.T., Hong, R.: Multiple feature hashing for real-time large scale near-duplicate video retrieval. In: MM, ACM, pp . 423–432 (2011)
Song, J., Yang, Y., Yang, Y., Huang, Z., Shen, H.T.: Inter-media hashing for large-scale retrieval from heterogeneous data sources. In: SIGMOD Conference, pp. 785–796 (2013)
Srivastava, N., Salakhutdinov, R.: Multimodal learning with deep boltzmann machines. In: NIPS, pp. 2231–2239 (2012)
Vincent, P., Larochelle, H., Bengio, Y., Manzagol, P.A.: Extracting and composing robust features with denoising autoencoders. In: ICML, pp. 1096–1103 (2008)
Wang, W., Ooi, B.C., Yang, X., Zhang, D., Zhuang, Y.: Effective multi-modal retrieval based on stacked auto-encoders. PVLDB 7(8), 649–660 (2014)
Weber, R., Schek, H.J., Blott, S.: A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces. In: Gupta, A., Shmueli, O., Widom, J. (eds.) Proceedings of24rd International Conference on Very Large Data Bases, New York, USA, pp. 194–205. Morgan Kaufmann (1998) (1998)
Weiss, Y., Torralba, A., Fergus, R.: Spectral hashing. In: Koller, D., Schuurmans, D., Bengio, Y., Bottou, L. (eds.) Advances in Neural Information Processing Systems 21, Proceedings of the Twenty-Second Annual Conference on Neural Information Processing Systems,Vancouver, British Columbia, Canada, pp. 1753–1760. Curran Associates, Inc., (2008)
Zhang, D., Agrawal, D., Chen, G., Tung, A.K.H.: Hashfile: an efficient index structure for multimedia data. In: ICDE, pp. 1103–1114. IEEE Computer Society, Hannover, Germany (2011)
Zhen, Y., Yeung, D.Y.: A probabilistic model for multimodal hashfunction learning. In: Yang, Q., Agarwal, D., Pei, J. (eds.) The 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’12, Beijing, China, pp. 940–948. ACM (2012)
Zhu, X., Huang, Z., Shen, H.T., Zhao, X.: Linear cross-modal hashing for efficient multimedia search. In: ACM Multimedia Conference, MM’ 13, Barcelona, Spain, pp. 143–152 (2013)
Zhuang, Y., Yang, Y., Wu, F.: Mining semantic correlation of heterogeneous multimedia data for cross-media retrieval. IEEE Trans. Multimed. 10(2), 221–229 (2008)
Acknowledgments
This work is supported by A*STAR Project 1321202073. Xiaoyan Yang is supported by Human-Centered Cyber-physical Systems (HCCS) programme by A*STAR in Singapore.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix


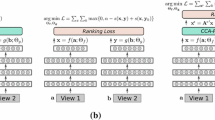
In this section, we present the mini-batch stochastic gradient descent (mini-batch SGD) algorithm and the back-propagation (BP) algorithm [22], which are used throughout this paper to train MSAE and MDNN.
Mini-batch SGD minimizes the objective loss (e.g., \(\mathcal {L}, \mathcal {L}_I,\mathcal {L}_T\)) by updating the parameters involved in the mapping function(s) based on the gradients of the objective w.r.t the parameters. Specifically, it iterates the whole dataset to extract mini-batches (Line 4). For each mini-batch, it averages the gradients computed from BP (Line 5) and updates the parameters (Line 6).
BP calculates the gradients of the objective loss (e.g., \(\mathcal {L}\), \(\mathcal {L}_I\), \(\mathcal {L}_T\)) w.r.t. the parameters involved in the mapping function (e.g., \(f_I, f_T\)) using a chain rule (Eqs. 19, 20). It forwards the input feature vector through all layers of the mapping function (Line 2). Then it backwards the gradients according to the chain rule (Line 4-6). \(\theta _i\) denotes parameters involved in the i-th layer. Gradients are returned at Line 7.
Rights and permissions
About this article

Cite this article
Wang, W., Yang, X., Ooi, B.C. et al. Effective deep learning-based multi-modal retrieval. The VLDB Journal 25, 79–101 (2016). https://doi.org/10.1007/s00778-015-0391-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-015-0391-4