
Abstract
A range of explanation engines assist data analysts by performing feature selection over increasingly high-volume and high-dimensional data, grouping and highlighting commonalities among data points. While useful in diverse tasks such as user behavior analytics, operational event processing, and root-cause analysis, today’s explanation engines are designed as stand-alone data processing tools that do not interoperate with traditional, SQL-based analytics workflows; this limits the applicability and extensibility of these engines. In response, we propose the DIFF operator, a relational aggregation operator that unifies the core functionality of these engines with declarative relational query processing. We implement both single-node and distributed versions of the DIFF operator in MB SQL, an extension of MacroBase, and demonstrate how DIFF can provide the same semantics as existing explanation engines while capturing a broad set of production use cases in industry, including at Microsoft and Facebook. Additionally, we illustrate how this declarative approach to data explanation enables new logical and physical query optimizations. We evaluate these optimizations on several real-world production applications and find that DIFF in MB SQL can outperform state-of-the-art engines by up to an order of magnitude.
















Similar content being viewed by others



Notes
To keep ANTI DIFF consistent with
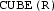 -
-  , we also prune all explanations with no support in R.
, we also prune all explanations with no support in R.Our implementation is open source and available at https://github.com/stanford-futuredata/macrobase.
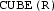 -
-  , we also prune all explanations with no support in R.
, we also prune all explanations with no support in R.References
Abiteboul, S., Hull, R., Vianu, V.: Foundations of Databases: The Logical Level. Addison-Wesley Longman Publishing Co. Inc, Boston (1995)
Agarwal, R., Srikant, R., et al.: Fast algorithms for mining association rules. In: VLDB, pp. 487–499 (1994)
Antonakakis, M., April, T., Bailey, M., Bernhard, M., Bursztein, E., Cochran, J., Durumeric, Z., Halderman, J.A., Invernizzi, L., Kallitsis, M., Kumar, D., Lever, C., Ma, Z., Mason, J., Menscher, D., Seaman, C., Sullivan, N., Thomas, K., Zhou, Y.: Understanding the mirai botnet. In: USENIX Security (2017). https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/antonakakis
Armbrust, M., et al.: Spark sql: relational data processing in spark. In: SIGMOD, pp. 1383–1394. ACM (2015)
Avnur, R., Hellerstein, J.M.: Eddies: continuously adaptive query processing. In: SIGMOD, vol. 29, pp. 261–272. ACM (2000)
Ayres, J., et al.: Sequential pattern mining using a bitmap representation. In: KDD, pp. 429–435. ACM (2002)
Babu, S., Bizarro, P., DeWitt, D.: Proactive re-optimization. In: SIGMOD, pp. 107–118. ACM (2005)
Bailis, P., Gan, E., Madden, S., Narayanan, D., Rong, K., Suri, S.: Macrobase: prioritizing attention in fast data. In: SIGMOD, pp. 541–556. ACM (2017)
Bailis, P., et al.: Prioritizing attention in fast data: principles and promise. In: CIDR. Google Scholar (2017)
Baralis, E., Cerquitelli, T., Chiusano, S.: Index support for frequent itemset mining in a relational dbms. In: ICDE, pp. 754–765. IEEE (2005)
Baralis, E., Cerquitelli, T., Chiusano, S.: Imine: index support for item set mining. IEEE Trans. Knowl. Data Eng. 21(4), 493–506 (2009)
Baraniuk, R.G.: Compressive sensing [lecture notes]. IEEE Signal Process. Mag. 24(4), 118–121 (2007)
Benjamini, Y., Yekutieli, D.: The control of the false discovery rate in multiple testing under dependency. Ann. Stat. 29, 1165–1188 (2001)
Bittorf, M., et al.: Impala: a modern, open-source SQL engine for hadoop. In: CIDR (2015)
Burdick, D., Calimlim, M., Gehrke, J.: Mafia: a maximal frequent itemset algorithm for transactional databases. In: ICDE, pp. 443–452. IEEE (2001)
Chambi, S., et al.: Better bitmap performance with roaring bitmaps. Softw. Pract. Exp. 46(5), 709–719 (2016)
Chambi, S., et al.: Optimizing druid with roaring bitmaps. In: IDEAS, pp. 77–86. ACM (2016)
Chaudhuri, S.: An overview of query optimization in relational systems. In: PODS, pp. 34–43. ACM (1998)
Chen, L., et al.: Towards linear algebra over normalized data. PVLDB 10(11), 1214–1225 (2017)
Dean, J., Barroso, L.A.: The tail at scale. Commun. ACM 56, 74–80 (2013)
Deshpande, A., et al.: Adaptive query processing. Found. Trends Databases 1(1), 1–140 (2007)
Durumeric, Z., et al.: The matter of heartbleed. In: IMC, pp. 475–488. ACM (2014)
Durumeric, Z., et al.: A search engine backed by Internet-wide scanning. In: SIGSAC, pp. 542–553. ACM (2015)
Fagin, R., et al.: Efficient implementation of large-scale multi-structural databases. In: VLDB, pp. 958–969. VLDB Endowment (2005)
Fagin, R., et al.: Multi-structural databases. In: PODS, pp. 184–195. ACM (2005)
Fang, W., et al.: Frequent itemset mining on graphics processors. In: DaMoN, pp. 34–42. ACM (2009)
Fournier-Viger, P., et al.: The SPMF open-source data mining library version 2. In: Joint European conference on machine learning and knowledge discovery in databases, pp. 36–40. Springer (2016)
Graefe, G., McKenna, W.J.: The volcano optimizer generator: extensibility and efficient search. In: ICDE, pp. 209–218. IEEE (1993)
Gray, J., et al.: Data cube: a relational aggregation operator generalizing group-by, cross-tab, and sub-totals. Data Min. Knowl. Discov. 1(1), 29–53 (1997)
Greenberg, A., et al.: The cost of a cloud: research problems in data center networks. ACM SIGCOMM Comput. Commun. Rev. 39(1), 68–73 (2008)
Guyon, I., Elisseeff, A.: An introduction to variable and feature selection. J. Mach. Learn. Res. 3(Mar), 1157–1182 (2003)
Hall, M.A.: Correlation-based feature selection of discrete and numeric class machine learning. Working Paper Series (2000)
Hellerstein, J.M., Stonebraker, M.: Readings in database systems. MIT press (2005)
Hellerstein, J.M., et al.: Architecture of a database system. Found. Trends® Databases 1(2), 141–259 (2007)
Hoi, S.C., et al.: Online feature selection for mining big data. In: BigMine, pp. 93–100. ACM (2012)
Ilyas, I.F., et al.: Cords: automatic discovery of correlations and soft functional dependencies. In: SIGMOD, pp. 647–658. ACM (2004)
Ioannidis, Y.E., Christodoulakis, S.: On the Propagation of Errors in the Size of Join Results, vol. 20. ACM, New York (1991)
Khoussainova, N., Balazinska, M., Suciu, D.: Perfxplain: debugging mapreduce job performance. PVLDB 5(7), 598–609 (2012)
Kimball, R., Ross, M.: The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling. Wiley, Hoboken (2011)
Konda, P., et al.: Feature selection in enterprise analytics: a demonstration using an r-based data analytics system. PVLDB 6(12), 1306–1309 (2013)
Kumar, A.: Learning over joins. Ph.D. thesis, The University of Wisconsin-Madison (2016)
Kumar, A., Naughton, J., Patel, J.M.: Learning generalized linear models over normalized data. In: Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, pp. 1969–1984. ACM (2015)
Kumar, A., et al.: To join or not to join?: thinking twice about joins before feature selection. In: SIGMOD, pp. 19–34. ACM (2016)
Lamb, A., et al.: The vertica analytic database: C-store 7 years later. VLDB 5(12), 1790–1801 (2012)
Leskovec, J., et al.: Mining of Massive Datasets. Cambridge University Press, Cambridge (2014)
Li, H., et al.: Pfp: parallel fp-growth for query recommendation. In: RecSys, pp. 107–114. ACM (2008)
Li, J., et al.: Feature selection: a data perspective. ACM Comput. Surv. (CSUR) 50(6), 94 (2017)
Meliou, A., Roy, S., Suciu, D.: Causality and explanations in databases. PVLDB 7(13), 1715–1716 (2014)
Melnik, S., et al.: Dremel: interactive analysis of web-scale datasets. PVLDB 3(1–2), 330–339 (2010)
Meng, X., et al.: Mllib: machine learning in apache spark. J. Mach. Learn. Res. 17(1), 1235–1241 (2016)
Neumann, T., Radke, B.: Adaptive optimization of very large join queries. In: SIGMOD, pp. 677–692. ACM (2018)
Ngo, H.Q., et al.: Worst-case optimal join algorithms. J. ACM: JACM 65(3), 16 (2018)
O’Neil, P., Quass, D.: Improved query performance with variant indexes. In: SIGMOD, vol. 26, pp. 38–49. ACM (1997)
Pagh, A., Pagh, R.: Scalable computation of acyclic joins. In: PODS, pp. 225–232. ACM (2006)
Rounds, E.: A combined nonparametric approach to feature selection and binary decision tree design. Pattern Recogn. 12(5), 313–317 (1980)
Roy, S., Suciu, D.: A formal approach to finding explanations for database queries. In: SIGMOD, pp. 1579–1590. ACM (2014)
Roy, S., et al.: Perfaugur: robust diagnostics for performance anomalies in cloud services. In: 2015 IEEE 31st International Conference on Data Engineering (ICDE), pp. 1167–1178. IEEE (2015)
Rupert Jr., G., et al.: Simultaneous Statistical Inference. Springer, Berlin (2012)
Saeys, Y., Inza, I., Larrañaga, P.: A review of feature selection techniques in bioinformatics. Bioinformatics 23(19), 2507–2517 (2007)
Schuh, S., Chen, X., Dittrich, J.: An experimental comparison of thirteen relational equi-joins in main memory. In: SIGMOD, pp. 1961–1976. ACM (2016)
Selinger, P.G., Astrahan, M.M., Chamberlin, D.D., Lorie, R.A., Price, T.G.: Access path selection in a relational database management system. In: Proceedings of the 1979 ACM SIGMOD International Conference on Management of Data, pp. 23–34 (1979)
Shang, X., Sattler, KU., Geist, I.: SQL based frequent pattern mining with FP-growth. In: Seipel, D., Hanus, M., Geske, U., Bartenstein, O. (eds.) Applications of Declarative Programming and Knowledge Management. INAP 2004, WLP 2004. Lecture Notes in Computer Science, vol. 3392. Springer, Berlin, Heidelberg (2005). https://doi.org/10.1007/11415763_3
Stonebraker, M., et al.: C-store: a column-oriented dbms. In: VLDB, pp. 553–564. VLDB Endowment (2005)
Wang, X., et al.: Data x-ray: a diagnostic tool for data errors. In: SIGMOD, pp. 1231–1245. ACM (2015)
Willard, D.E.: Applications of range query theory to relational data base join and selection operations. J. Comput. Syst. Sci. 52(1), 157–169 (1996)
Wu, E., Madden, S.: Scorpion: explaining away outliers in aggregate queries. PVLDB 6(8), 553–564 (2013)
Yang, F., et al.: Druid: A real-time analytical data store. In: SIGMOD, pp. 157–168. ACM (2014)
Yoon, D.Y., Niu, N., Mozafari, B.: Dbsherlock: a performance diagnostic tool for transactional databases. In: SIGMOD, pp. 1599–1614. ACM (2016)
Zaharia, M., et al.: Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. In: NSDI, pp. 2–2. USENIX Association (2012)
Zhang, F., Zhang, Y., Bakos, J.: Gpapriori: Gpu-accelerated frequent itemset mining. In: 2011 IEEE International Conference on Cluster Computing (CLUSTER), pp. 590–594. IEEE (2011)
Acknowledgements
We thank Kexin Rong, Hector Garcia-Molina, our colleagues in the Stanford DAWN Project, and the anonymous VLDB reviewers for their detailed feedback on earlier drafts of this work. This research was supported in part by affiliate members and other supporters of the Stanford DAWN project—Ant Financial, Facebook, Google, Intel, Microsoft, NEC, SAP, Teradata, and VMware—as well as Toyota Research Institute, Keysight Technologies, Hitachi, Northrop Grumman, Amazon Web Services, Juniper Networks, NetApp, and the NSF under CAREER grant CNS-1651570. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Translating DIFF to standard SQL
Translating DIFF to standard SQL
We present a sample DIFF query, borrowed from the Example Workflow in Sect. 2.1, and its translation into standard SQL.

This query is equivalent to the following Postgres-compatible SQL query:

Rights and permissions
About this article

Cite this article
Abuzaid, F., Kraft, P., Suri, S. et al. DIFF: a relational interface for large-scale data explanation. The VLDB Journal 30, 45–70 (2021). https://doi.org/10.1007/s00778-020-00633-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-020-00633-6