
Abstract
In the last decade, the hierarchical matrix technique was introduced to deal with dense matrices in an efficient way. It provides a data-sparse format and allows an approximate matrix algebra of nearly optimal complexity. This paper is concerned with utilizing multiple processors to gain further speedup for the \({\mathcal {H}}\)-matrix algebra, namely matrix truncation, matrix–vector multiplication, matrix–matrix multiplication, and inversion. One of the most cost-effective solution for large-scale computation is distributed computing. Distribute-memory architectures provide an inexpensive way for an organization to obtain parallel capabilities as they are increasingly popular. In this paper, we introduce a new distribution scheme for \({\mathcal {H}}\)-matrices based on the corresponding index set. Numerical experiments applied to a BEM model will complement our complexity analysis.








Similar content being viewed by others
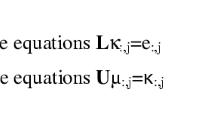


References
Bebendorf, M., Kriemann, R.: Fast parallel solution of boundary integral equations and related problems. Comput. Vis. Sci. 8(3–4), 121–135 (2005)
Blackford, L.S., Choi, J., Cleary, A., D’azevedo, E., Demmel, J., Dhillon, I., Dongarra, J., Hammarling, S., Henry, G., Petitet, A., Stanley, K., Walker, D., Whalet, R.C.: ScaLAPACK Users’ Guide. Society for Industrial and Applied Mathematics, Philadelphia, PA (1997)
Börm, S., Grasedyck, L., Hackbusch, W.: Hierarchical Matrices. Technical Report. Lecture Note 21, MPI Leipzig (2003)
Demmel, J., Grigori, L., Hoemmen, M.F., Langou, J.: Communication-optimal parallel and sequential QR and LU factorizations. SIAM J. Sci. Comput. 34(1), 206–239 (2011)
Grama, A., Gupta, A., Karypis, G., Kumar, V.: Introduction to Parallel Computing, 2nd edn. Addison-Wesley, Reading, MA (2003)
Grasedyck, L., Hackbusch, W.: Construction and arithmetics of \({\cal H}\)-matrices. Computing 70(4), 295–334 (2003)
Gene H. Golub and Charles F. Van Loan: Matrix Computations, 3rd edn. Johns Hopkins Studies in Mathematical Sciences (1996)
Hackbusch, W.: A sparse matrix arithmetic based on \({\cal H}\)-matrices I: introduction to \({\cal H}\)-matrices. Computing 62(2), 89–108 (1999)
Izadi, M.: Hierarchical Matrix Techniques on Massively Parallel Computers, PhD thesis. Universität Leipzig (2012)
Kriemann, R.: Parallele Algorithmen für \({\cal H}\)-Matrizen, PhD thesis. Universität Kiel (2004)
Kriemann, R.: Parallel \({\cal H}\)-matrix arithmetics on shared memory systems. Computing 74(3), 273–297 (2005)
Acknowledgments
The author would like to thank Dr. Ronald Kriemann for several fruitful discussions on this paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Wolfgang Hackbusch.
Rights and permissions
About this article
Cite this article
Izadi, M. Parallel \({\mathcal {H}}\)-matrix arithmetic on distributed-memory systems. Comput. Visual Sci. 15, 87–97 (2012). https://doi.org/10.1007/s00791-013-0198-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00791-013-0198-z