
Abstract
This paper introduces a shape-based similarity measure, called the angular metric for shape similarity (AMSS), for time series data. Unlike most similarity or dissimilarity measures, AMSS is based not on individual data points of a time series but on vectors equivalently representing it. AMSS treats a time series as a vector sequence to focus on the shape of the data and compares data shapes by employing a variant of cosine similarity. AMSS is, by design, expected to be robust to time and amplitude shifting and scaling, but sensitive to short-term oscillations. To deal with the potential drawback, ensemble learning is adopted, which integrates data smoothing when AMSS is used for classification. Evaluative experiments reveal distinct properties of AMSS and its effectiveness when applied in the ensemble framework as compared to existing measures.













Similar content being viewed by others


Notes
To be precise, C and C vec are not exactly the same because the latter does not retain the position of the first element c 1.
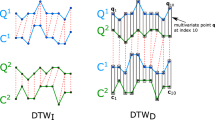
Another shape-based similarity measure, DDTW, uses Euclidean distance. However, the distance is measured between the slopes of two vectors, which is similar to (inversed) cosine similarity in concept.
This situation can arise when assessing AMSS(Q N−2, C M−1) or AMSS(Q N−1, C M−2).
EDR was chosen because it is reported to be the most accurate measure among the edit-distance family, including LCSS and ERP [9].
DDTW(Q, Q) always becomes 0, whereas AMSS(Q, Q) linearly increases with the length of Q because AMSS is defined as a sum of similarities between matched subsequences.
Note that these results are different from Table 1 due to the different treatment of the training data.
References
Aßfalg J, Kriegel H-P, Kröger P, Kunath P, Pryakhin A, and Renz M (2006) Similarity search on time series based on threshold queries. In: Proceedings of the 10th international conference on extending database technology, pp 276–294
Berndt DJ, Clifford J (1996) Finding patterns in time series: a dynamic programming approach. In: Fayyad UM, Piatetsky-Shapiro G, Smyth P, Uthurusamy R (eds) Advances in knowledge discovery and data mining. AAAI, Menlo Park, pp 229–248
Chan K-P, Fu AW-C (1999) Efficient time series matching by wavelets. In: Proceedings of the 15th international conference on data engineering, pp 126–133
Chen L, Ng R (2004) On the marriage of lp-norms and edit distance. In: Proceedings of the 30th international conference on very large data bases, pp 792–803
Chen L, Øzsu MT, Oria V (2005) Robust and fast similarity search for moving object trajectories. In: Proceedings of the 2005 ACM SIGMOD international conference on management of data, pp 491–502
Chen Y, Nascimento MA, Ooi BC, Tung AKH (2007) Spade: on shape-based pattern detection in streaming time series. In: Proceedings of the IEEE 23rd international conference on data engineering, pp 786–795
Das G, Gunopulos D, Mannila H (1997) Finding similar time series. In: Proceedings of the first european symposium on principles of data mining and knowledge discovery, pp 88–100
Dietterich TG (2000) Ensemble methods in machine learning. In: Proceedings of the 1st international workshop on multiple classifier systems, pp 1–15
Ding H, Trajcevski G, Scheuermann P, Wang X, and Keogh E (2008) Querying and mining of time series data: experimental comparison of representations and distance measure. Proc VLDB Endowment 1:1542–1552
Faloutsos C, Ranganathan M, Manolopoulos Y (1994) Fast subsequence matching in time-series databases. In: Proceedings of the 1994 ACM SIGMOD international conference on management of data, pp 419–429
Frentzos E, Gratsias K, Theodoridis Y (2007) Index-based most similar trajectory search. In: Proceedings of the IEEE 23rd international conference on data engineering, pp 816–825
Freund Y, Schapire RE (1995) A decision-theoretic generalization of on-line learning and an application to boosting. In: Proceedings of the second european conference on computational learning theory, pp 23–37
Freund Y, and Schapire RE (1997) A decision theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci 55(1):119–139
Geurts P, Wehenkel L (2005) Segment and combine approach for non-parametric time-series classification. In: Proceedings of the 9th European conference on principles and practice of knowledge discovery in databases, pp 478–485
Gunopulos D, Das G (2000) Time series similarity measures. In: Tutorial notes of the sixth ACM SIGKDD international conference on knowledge discovery and data mining, pp 243–307
Itakura F (1975) Minimum prediction residual principle applied to speech recognition. IEEE Trans Acoust Speech Signal Process 23(1):67–72
Keogh E (2002) Exact indexing of dynamic time warping. In: Proceedings of the 28th international conference on very large data bases, pp 406–417
Keogh E, Xi X, Wei L, Ratanamahatana CA (2006) The UCR time series classification/clustering homepage. http://www.cs.ucr.edu/˜eamonn/time_series_data/
Keogh EJ, Pazzani MJ (2001) Derivative dynamic time warping. In: Proceedings of the 1st SIAM international conference on data mining, pp 1–11
Lin J, Keogh E, Lonardi S, Chiu B (2003) A symbolic representation of time series, with implications for streaming algorithms. In: Proceedings of the 8th ACM SIGMOD workshop on research issues in data mining and knowledge discovery, pp 2–11
Liu Y, Yao X (1999) Ensemble learning via negative correlation. Neural Netw 12(10):1399–1404
Morse MD, Patel JM (2007) An efficient and accurate method for evaluating time series similarity. In: Proceedings of the 2007 ACM SIGMOD international conference on management of data, pp 569–580
Nomiya H, Uehara K (2007) Multistrategical approach in visual learning. In: Proceedings of the 8th Asian conference on computer vision, pp 502–511
Pavlidis T, Horowitz SL (1974) Segmentation of plane curves. IEEE Trans Comput 23:860–870
Rafiei D, Mendelzon A (1997) Similarity-based queries for time series data. In: Proceedings of the 1997 ACM SIGMOD international conference on management of data, pp 13–25
Rodríguez JJ, Kuncheva LI (2007) Time series classification: Decision forests and SVM on interval and DTW features. In: Proceedings of the workshop and challenge on time series classification
Sakoe H, Chiba S (1978) Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans Acoust Speech Signal Process 26(1):46–49
Acknowledgments
The authors would like to thank Takashi Okamura for his help with implementations and experiments.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
AMSS was compared with other (dis)similarity measures: Euclidean distance, DTW, DDTW, EDR, and SpADe as shown in Table 1. However, there is more comprehensive comparison reported by Ding et al. [9], who used k-fold cross validation for parameter tuning and evaluation for 13 different (dis)similarity measures. The value of k was individually set for each UCR data set (or class).
This paper did not take Ding et al.’s results for the comparison in Table 1 because of the significant amount of computation needed for the ensemble experiments with the way they tuned parameters through cross validation. For completeness, however, AMSS (without the ensemble framework) is compared with those reported by Ding et al. with their evaluation scheme. The results are summarized in Table 4, where boldface indicates the best performance (lowest error rates) across different measures.Footnote 7 “DTW (w)” and “LCSS (w)” indicate DTW and LCSS with warping constraint, respectively. All the results but DDTW were taken from Ding et al.’s paper [9], and DDTW’s results are based on our own implementation with no warping window. For this experiments, the same number of splits k as Ding et al. was used so that all the results are directly comparable to theirs. Among the 20 data sets, AMSS performed the best for 10 data sets including one tie.
In terms of the number of data sets for which error rates are lowest, AMSS was found to be the best (dis)similarity measure in this particular setting. As discussed in Sect. 5.2, however, no single measure works for every type of data. For example, simple Euclidean distance performed better than all the other measures, including AMSS, for the “Beef” data set. More work is needed to understand the interaction between the properties of similarity measures and the characteristics of the target data types.
Rights and permissions
About this article
Cite this article
Nakamura, T., Taki, K., Nomiya, H. et al. A shape-based similarity measure for time series data with ensemble learning. Pattern Anal Applic 16, 535–548 (2013). https://doi.org/10.1007/s10044-011-0262-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-011-0262-6