
Abstract
Borrowing from concepts in expander graphs, we study the expansion properties of real-world, complex networks (e.g., social networks, unstructured peer-to-peer, or P2P networks) and the extent to which these properties can be exploited to understand and address the problem of decentralized search. We first produce samples that concisely capture the overall expansion properties of an entire network, which we collectively refer to as the expansion signature. Using these signatures, we find a correspondence between the magnitude of maximum expansion and the extent to which a network can be efficiently searched. We further find evidence that standard graph-theoretic measures, such as average path length, fail to fully explain the level of “searchability” or ease of information diffusion and dissemination in a network. Finally, we demonstrate that this high expansion can be leveraged to facilitate decentralized search in networks and show that an expansion-based search strategy outperforms typical search methods.





Similar content being viewed by others


Notes
There is a large body of work studying expansion in theoretic computer science and graph theory. However, much of this work focuses on (1) synthetic graphs that do not normally arise in the real-world such as \(d\)-regular graphs and (2) the minimum (not maximum) expansion in these graphs [16].
We employ the concept of vertex expansion here. The vertex expansion of an entire graph is typically taken to mean \(\min _{S \subset V}\frac{|N(S)|}{|S|}\) [16].
For directed networks that are very weakly connected, a sample with high maximum expansion (based on out-degree) may exist, but the nodes in the sample itself may not be reachable from substantial portions of the network. Samples such as this may shed little light on searchability. Possible approaches to addressing these scenarios include computing expansion signatures using the expected maximum expansion of connected samples or examining both in-degree and out-degree expansion. In the present work, however, links are treated as undirected (or bidirectional).
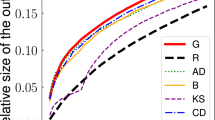
As mentioned, one may compute expansion signatures using either the expansion quality or the discovery quotient, as both are essentially normalized representations of the expansion. For the present work, we plot the expansion quality of samples, which is \(\mathcal X _Q(S) = \frac{|N(S)|}{|V-S|}\).
Alternatively, the approximation guarantee for Maximum Expansion can be shown through formulation as an optimization problem with a submodular objective function and the well-known result by Nemhauser et al. [33] regarding such submodular functions. Maximum Expansion can also simply be mapped to a Maximum Coverage instance via a reduction.
In the context of P2P, we assume each node knows the identity of its neighbors’ neighbors, but not necessarily the files stored by its neighbors’ neighbors.
The normalized cumulative nodes discovered (\(\frac{|N(S) \cup S|}{|V|}\)) is simply the discovery quotient, as defined in Sect. 3.1.
See [20] for more information on conductance and its relation to the concept of expansion.
For the purposes of this experiment, in order to ensure every node in \(V\) is traversed, we disallowed all node revisits. That is, for all search strategies, if all neighbors of the current node have been visited, the next step is selected uniformly at random from among the nodes in \(N(S)\).
References
Adamic LA, Lukose RM, Puniyani AR, Huberman BA (2001) Search in power-law networks. Phys Rev E 64(4):046135+
Barabasi A-L, Albert R (1999) Emergence of scaling in random networks. Science 286(5439):509–512
Barret CL, Eubank SG, Smith JP (2007) Fighting infectious diseases (Scientific American). Rosen Publishing Group, New York
Boguna M, Krioukov D, Claffy KC (2008) Navigability of complex networks. Nat Phys 5(1):74–80
Chierichetti F, Kumar R, Tomkins A (2010) Max-cover in map-reduce. In: Proceedings of the 19th international conference on world wide web, WWW ’10. New York, NY, USA. ACM, pp 231–240
Chierichetti F, Lattanzi S, Panconesi A (2010) Rumour spreading and graph conductance. In: SODA 2010
Daly EM, Haahr M (2007) Social network analysis for routing in disconnected delay-tolerant MANETs. In: Proceedings of the 8th ACM international symposium on mobile ad hoc networking and computing, MobiHoc ’07. New York, NY, USA. ACM, pp 32–40
Erdös P, Rényi A (1959) On random graphs, I. Publicationes Mathematicae (Debrecen) 6:290–297
Feige U (1998) A threshold of ln n for approximating set cover. J ACM 45(4):634–652
Garey MR, Johnson DS (1979) Computers and intractability: a guide to the theory of NP-completeness (series of books in the mathematical sciences), 1st edn. W. H. Freeman & Co Ltd, San Francisco, CA
Gehrke J, Ginsparg P, Kleinberg J (2003) Overview of the 2003 KDD Cup. SIGKDD Explor Newsl 5(2):149–151
Girvan M, Newman MEJ (2002) Community structure in social and biological networks. Proc Natl Acad Sci 99(12):7821–7826
Guha S, Khuller S (1998) Approximation algorithms for connected dominating sets. Algorithmica 20(4):374–387
Hochbaum DS (ed) (1997) Approximation algorithms for NP-hard problems. PWS Publishing Co., Boston, MA
Hochbaum DS, Pathria A (1998) Analysis of the greedy approach in problems of maximum k-coverage. Nav Res Logist (NRL) 45(6):615–627
Hoory S, Linial N, Wigderson A (2006) Expander graphs and their applications. Bull Am Math Soc 43:439–561
Hui KYK, Lui JCS, Yau DKY (2006) Small-world overlay P2P networks: construction, management and handling of dynamic flash crowds. Comput Netw 50(15):2727–2746
Jiang S, Guo L, Zhang X, Wang H (2008) LightFlood: minimizing redundant messages and maximizing scope of peer-to-peer search. IEEE Trans Parallel Distrib Syst 19(5):601–614
Jin S, Jiang H (2007) Novel approaches to efficient flooding search in peer-to-peer networks. Comput Netw 51(10):2818–2832
Kannan R, Vempala S, Vetta A (2004) On clusterings: good, bad and spectral. J ACM 51(3):497–515
Kleinberg J (2000) The small-world phenomenon: an algorithmic perspective. In: Proceedings of the 32nd ACM symposium on theory of computing, May 2000
Kleinberg J (2006) Complex networks and decentralized search algorithms. In: International Congress of Mathematicians (ICM)
Kleinfeld J (2002) Could it be a big world after all? the ’six degrees of separation’ myth. Society, Apr 2002
Klimt B, Yang Y (2004) The enron corpus: a new dataset for email classification research. Mach Learn ECML 2004:217–226
Leskovec J, Kleinberg J, Faloutsos C (2005) Graphs over time: densification laws, shrinking diameters and possible explanations. In: KDD ’05: proceedings of the eleventh ACM SIGKDD international conference on knowledge discovery in data mining, pp 177–187
Leskovec J, Lang KJ, Dasgupta A, Mahoney MW (2008) Statistical properties of community structure in large social and information networks. In: Proceedings of the 17th international conference on world wide web, WWW ’08. New York, NY, USA. ACM, pp 695–704
Li X, Wu J (2006) Searching techniques in peer-to-peer networks. In: Wu J (ed) Handbook of theoretical and algorithmic aspects of ad hoc, sensor, and peer-to-peer networks. Auerbach, New York
Liben-Nowell D, Novak J, Kumar R, Raghavan P, Tomkins A (2005) Geographic routing in social networks. Proc Natl Acad Sci USA 102(33):11623–11628
Maiya AS, Berger-Wolf TY (2010) Sampling community structure. In: WWW ’10: proceedings of the 19th international conference on the world wide web, Apr 2010
Maiya AS, Berger-Wolf TY (2011) Benefits of bias: towards better characterization of network sampling. In: Proceedings of the 17th ACM SIGKDD international conference on knowledge discovery and data mining, KDD ’11. New York, NY, USA. ACM, pp 105–113
Milgram S (1967) The small world problem. Psychol Today 2:60–67
Mitra B (2009) Technological networks. In: Ganguly N, Deutsch A, Mukherjee A (eds) Dynamics on and of complex networks, chapter 15. Birkhäuser Boston, Boston, pp 253–274
Nemhauser GL, Wolsey LA, Fisher ML (1978) An analysis of approximations for maximizing submodular set functionsI. Math Program 14(1):265–294
Newman MEJ (2006) Finding community structure in networks using the eigenvectors of matrices. Phys Rev E (Statistical, Nonlinear, and Soft Matter Physics) 74(3):036104+
Raghavan UN, Albert R, Kumara S (2007) Near linear time algorithm to detect community structures in large-scale networks. Phys Rev E 76(3):036106+
Richardson M, Agrawal R, Domingos P (2003) Trust management for the semantic web. In: International semantic web conference, pp 351–368
Ripeanu M, Foster I, Iamnitchi A (2002) Mapping the gnutella network: properties of large-scale peer-to-peer systems and implications for system design. arXiv:cs/0209028v1 [cs.DC] Sept 2002
Schmid S, Wattenhofer R (2007) Structuring unstructured peer-to-peer networks. In: Aluru S, Parashar M, Badrinath R, Prasanna VK (eds) High performance computing HiPC 2007, vol 4873 of lecture notes in computer science, chapter 40. Springer, Berlin, pp 432–442
Tsoumakos D, Roussopoulos N (2006) Analysis and comparison of P2P search methods. In: InfoScale ’06: proceedings of the 1st international conference on scalable information systems, New York, NY, USA. ACM, pp 25+
Wasserman S, Faust K (2005) Models and methods in social network analysis (structural analysis in the social sciences). Cambridge University Press, Cambridge
Watts DJ, Strogatz SH (1998) Collective dynamics of ’small-world’ networks. Nature 393(6684):440–442
Wu J, Li H (1999) On calculating connected dominating set for efficient routing in ad hoc wireless networks. In: Proceedings of the 3rd international workshop on discrete algorithms and methods for mobile computing and communications, DIALM ’99, New York, NY, USA. ACM, pp 7–14
Yang B, Molina HG (2002) Improving search in peer-to-peer networks. In: ICDCS ’02: proceedings of the 22nd international conference on distributed computing systems (ICDCS’02), Washington, DC, USA, IEEE Computer Society, pp 5+
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Maiya, A.S., Berger-Wolf, T.Y. Expansion and decentralized search in complex networks. Knowl Inf Syst 38, 469–490 (2014). https://doi.org/10.1007/s10115-012-0596-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-012-0596-4