
Abstract
Keyword search over structured data offers an alternative method to explore and query databases for users that are not familiar with the structure of the data and/or a query language. Structured data are usually modeled as graphs. In this context, an answer is a substructure of the graph that contains all or some of the query keywords. In most of the previous works, a minimal tree that covers all the query keywords are found as the answer. Some recent works offer to find subgraphs rather than minimal trees and show that subgraphs might be more informative for the users. However, current methods suffer from the following problems. Although some of the content nodes (i.e., nodes that contain input keywords) are close to each other in an answer, others might be far from each other. While searching for the best answer, current methods explore the whole graph rather than only the content nodes. This might increase the run time and leads to poor performance. To address these problems, we propose to find top-\(k\, r\)-cliques as the answers to the graph keyword search problem. An \(r\)-clique is a set of content nodes that cover all the input keywords, and the distance between each pair of nodes is less than or equal to \(r\). We propose a new weight function that is the sum of distances between each pair of content nodes. We prove that minimizing the new weight function is NP-hard and propose an approximation algorithm that produces \(r\)-cliques with 2-approximation ratio in polynomial delay. We further improve the run time of the approximation algorithm with the cost of increasing the approximation ratio. Extensive performance studies using three large real datasets confirm the efficiency and accuracy of finding \(r\)-cliques in graphs.


















Similar content being viewed by others

Notes
A content node is a node in the input graph that contains at least one of the input keywords.
The shortest distance between two nodes in a graph is the sum of the weights of a path between the two nodes such that the sum of the weights of its constituent edges is minimized.
The weight of the edges depend on the application’s dataset.
A complete survey on keyword search in databases and graphs can be found in [25].
For directed graphs, the shortest distance between two nodes in an \(r\)-clique should be no larger than \(r\) in both directions.
3-satisfiability (3-SAT) is the problem of determining whether there exists an interpretation that satisfies a given boolean formula in a conjunctive normal form where each clause is limited to at most three literals. See [24] for more details.
There are other ways to prove this theorem, such as by reducing the problem to the multiple-choice cover problem. See [2] for the definition of the multiple-choice cover problem.
It should be noted that the same approach is used in [2] for proving the NP-hardness of multiple-choice cover problem.
The reason to choose this value will become clear later in the proof.
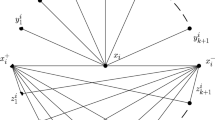
Note that since the distance between \(u_i\) and \(\overline{u}_i\) is set to \(2\times w+\epsilon \) (where \(\epsilon >0\)) which is larger than \(r\) (set to \(2\times w\)), \(u_i\) and \(\overline{u}_i\) cannot be part of the same answer.
Since the distance between other variables is set to \(\frac{w}{\small \big (\begin{array}{c}n+m\\ 2\end{array}\big )}\), and we want to choose \(n+m\) keywords, if a feasible solution exists, its weight is less than \(w\).
Our approach to dividing a search space is similar to the idea used in [23].
As we formally describe later, our approximation algorithms find an approximation of an \(r\)-clique. Therefore, in the rest of the paper, an approximation of an \(r\)-clique is called approx-\(r\)-clique.
This is also valid for approx-\(r\)-cliques.
Note that the systems’s architecture is previously discussed in our demo paper published in [13]. It is briefly described here due to the completeness of this paper.
In our implementation, we used quick sort.
We choose 8 users because it is mentioned in [21] that “For really low-overhead projects, it’s often optimal to test as little as 2 users per study. For some other projects, 8 users—or sometimes even more—might be better.”
References
Anagnostopoulos A, Becchetti L, Castillo C, Gionis A, Leonardi S (2012) Online team formation in social networks. In: Proceedings of the WWW’12, pp 839–848
Arkin EM, Hassin R (2000) Minimum-diameter covering problems. Networks 36(3):147–155
Baeza-Yates R, Ribeiro-Neto B (1999) Modern information retrieval. Addison Wesley, Reading, MA
Bhalotia G, Nakhe C, Hulgeri A, Chakrabarti S, Sudarshan S (2002) Keyword searching and browsing in databases using banks. In: Proceedings of ICDE’02, pp 431–440
Dalvi B, Kshirsagar M, Sudarshan S (2008) Keyword search on external memory data graphs. In: Proceedings of VLDB’08, pp 1189–1204
Datta S, Majumder A, Naidu K (2012) Capacitated team formation problem on social networks. In: Proceedings of KDD’12, pp 1005–1013
Ding B, Yu J, Wang S, Qin L, Zhang X, Lin X (2007) Finding top-k min-cost connected trees in databases. In: Proceedings of ICDE’07, pp 836–845
Fan W, Li J, Ma S, Tang N, Wu Y, Wu Y (2010) Graph pattern matching: from intractable to polynomial time. In: Proceedings of VLDB’10, pp 264–275
Golenberg K, Kimelfeld B, Sagiv Y (2008) Keyword proximity search in complex data graphs. In: Proceedings of SIGMOD’08, pp 927–940
He H, Wang H, Yang J, Yu P (2007) Blinks: ranked keyword searches on graphs. In: Proceedings of SIGMOD’07, pp 305–316
Kacholia V, Pandit S, Chakrabarti S, Sudarshan S, Desai R, Karambelkar H (2005) Bidirectional expansion for keyword search on graph databases. In: Proceedings of VLDB’05, pp 505–516
Kargar M, An A (2011) Keyword search in graphs: Finding \(r\)-cliques. In: Proceedings of VLDB’11, pp 681–692
Kargar M, An A (2012) Efficient top-k keyword search in graphs with polynomial delay. In: Proceedings of ICDE’12, pp 1269–1272
Karp RM (1972) Reducibility among combinatorial problems. In: Miller RE, Thatcher JW (eds) Complexity of computer computations. Plenum, NY, pp 85–103
Karypis G, Kumar V (1995) Analysis of multilevel graph partitioning: supercomputing’95. In: Proceedings of the 1995 ACM/IEEE conference on supercomputing
Koren Y, North SC, Volinsky C (2006) Measuring and extracting proximity in networks. In: Proceedings of KDD’06, pp 245–255
Kou L, Markowsky G, Berman L (1981) A fast algorithm for Steiner trees. Acta Inform 15(2):141–145
Lappas T, Liu K, Terzi E (2009) Finding a team of experts in social networks. In: Proceedings of KDD’09, pp 467–475
Lawler E (1972) A procedure for computing the k best solutions to discrete optimization problems and its application to the shortest path problem. Manag Sci 18(7):401–405
Li G, Ooi BC, Feng J, Wang J, Zhou L (2008) Ease: Efficient and adaptive keyword search on unstructured, semi-structured and structured data. In: Proceedings of SIGMOD’08, pp 903–914
Nielsen J (2012) How many test users in a usability study? http://www.nngroup.com/articles/how-many-test-users/
Park J, Lee S (2011) Keyword search in relational databases. Knowl Inf Syst 26:175–193
Qin L, Yu J, Chang L, Tao Y (2009) Querying communities in relational databases. In: Proceedings of ICDE’09, pp 724–735
Vazirani V (2001) Approximation algorithms. Springer, Berlin
Yu J, Qin L, Chang L (eds) (2010) Keyword search in databases. Morgan and Claypool Publisher, NY
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Kargar, M., An, A. Finding top-\(k\, r\)-cliques for keyword search from graphs in polynomial delay. Knowl Inf Syst 43, 249–280 (2015). https://doi.org/10.1007/s10115-014-0736-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-014-0736-0