
Abstract
Detecting dense subgraphs such as cliques or quasi-cliques is an important graph mining problem. While this task is established for simple graphs, today’s applications demand the analysis of more complex graphs: In this work, we consider a frequently observed type of graph where edges represent different types of relations. These multiple edge types can also be viewed as different “layers” of a graph, which is denoted as a “multi-layer graph”. Additionally, each edge might be annotated by a label characterizing the given relation in more detail. By simultaneously exploiting all this information, the detection of more interesting subgraphs can be supported. We introduce the multi-layer coherent subgraph model, which defines clusters of vertices that are densely connected by edges with similar labels in a subset of the graph layers. We avoid redundancy in the result by selecting only the most interesting, non-redundant subgraphs for the output. Based on this model, we introduce the best-first search algorithm MiMAG. In thorough experiments, we demonstrate the strengths of MiMAG in comparison with related approaches on synthetic as well as real-world data sets.












Similar content being viewed by others


Notes
In the following, we use the terms “layers” and “dimensions” interchangeably.
The contents of this paper are also included in the first author’s Ph.D. thesis [5]
To avoid confusion, we use the term “vertex” for a vertex in the original graph and the term “node” for the nodes of the set enumeration tree, which represent sets of vertices.
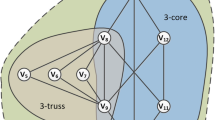
Note that for each layer we get a different set enumeration tree (cf. Fig. 4, top) as different subtrees might be pruned in each layer.
If one is interested in generating all patterns, an arbitrary traversal strategy can be used. We, however, want to determine only a subset of the patterns (the non-redundant, high-quality ones).
Due to our redundancy definition, it is possible that clusters of equal quality are redundant w.r.t. each other. As in this case, there is no indication that one of the clusters is “better” than the other(s), we simply keep the cluster in the result that was detected first.
Please note that the pruning strategies in line 15 and 19 do not discard any valid clusters, but only vertices and dimensions that do not contribute to clusters (see Sect. 4.3).
Assume there would exist an admissible algorithm expanding fewer subtrees. Then, after termination of this algorithm, there exists at least one subtree that has not been investigated by this algorithm but whose estimated quality is higher than the quality of the clusters in the result. Based on the information the algorithm has, however, it cannot rule out the possibility that this subtree contains a valid cluster of this quality. Thus, the algorithm cannot be admissible.
Note: This property does not hold for the cluster model itself (neither for the set of vertices nor for the relevant dimensions). It is possible that O does not form a quasi-clique in dimension i, but \(O^{\prime } \supset O\) does.
References
Aggarwal C, Wang H (2010) Managing and mining graph data. Springer, New York
Araujo M, Günnemann S, Papadimitriou S, Faloutsos C, Basu P, Swami A, Papalexakis EE, Koutra D (2016) Discovery of “comet” communities in temporal and labeled graphs com\(^{\wedge 2}\). Knowl Inf Syst 46(3):657–677. doi:10.1007/s10115-015-0847-2
Berlingerio M, Coscia M, Giannotti F (2011) Finding and characterizing communities in multidimensional networks. In: ASONAM, pp 490–494. doi:10.1109/ASONAM.2011.104
Beyer KS, Goldstein J, Ramakrishnan R, Shaft U (1999) When is “nearest neighbor” meaningful? In: ICDT, pp 217–235
Boden B (2014) Combined clustering of graph and attribute data. PhD thesis, RWTH Aachen University
Boden B, Günnemann S, Hoffmann H, Seidl T (2012) Mining coherent subgraphs in multi-layer graphs with edge labels. In: SIGKDD
Boden B, Günnemann S, Hoffmann H, Seidl T (2013) RMiCS: a robust approach for mining coherent subgraphs in edge-labeled multi-layer graphs. In: SSDBM, p 23
Cai D, Shao Z, He X, Yan X, Han J (2005) Community mining from multi-relational networks. PKDD 3721:445–452
Cerf L, Besson J, Robardet C, Boulicaut JF (2008) Data-peeler: constraint-based closed pattern mining in n-ary relations. SDM 8:37–48
Cerf L, Besson J, Robardet C, Boulicaut JF (2009a) Closed patterns meet n-ary relations. TKDD 3(1):1–3
Cerf L, Nguyen TBN, Boulicaut JF (2009b) Discovering relevant cross-graph cliques in dynamic networks. In: ISMIS, pp 513–522
Cheng Y, Zhao R (2009) Multiview spectral clustering via ensemble. In: GRC, IEEE, pp 101–106
Dong X, Frossard P, Vandergheynst P, Nefedov N (2012) Clustering with multi-layer graphs: a spectral perspective. Signal Process 60(11):5820–5831. doi:10.1109/TSP.2012.2212886
Fortunato S (2010) Community detection in graphs. Phys Rep 486(3–5):75–174
Günnemann S, Färber I, Boden B, Seidl T (2010) Subspace clustering meets dense subgraph mining: a synthesis of two paradigms. In: ICDM, pp 845–850
Günnemann S, Boden B, Seidl T (2011) DB-CSC: a density-based approach for subspace clustering in graphs with feature vectors. In: PKDD, pp 565–580
Günnemann S, Färber I, Müller E, Assent I, Seidl T (2011) External evaluation measures for subspace clustering. In: CIKM
Günnemann S, Boden B, Seidl T (2012) Finding density-based subspace clusters in graphs with feature vectors. Data Min Knowl Discov 25(2):243–269
Günnemann S, Färber I, Raubach S, Seidl T (2013) Spectral subspace clustering for graphs with feature vectors. In: ICDM, pp 231–240
Günnemann S, Färber I, Boden B, Seidl T (2014) Gamer: a synthesis of subspace clustering and dense subgraph mining. Knowl Inf Syst 40(2):243–278
Hanisch D, Zien A, Zimmer R, Lengauer T (2002) Co-clustering of biological networks and gene expression data. Bioinformatics 18:145–154
Harary F, Norman R (1960) Some properties of line digraphs. Rendiconti del Circolo Matematico di Palermo 9(2):161–168
Hart P, Nilsson N, Raphael B (1968) A formal basis for the heuristic determination of minimum cost paths. Syst Sci Cybern 4(2):100–107. doi:10.1109/TSSC.1968.300136
Kriegel HP, Kröger P, Zimek A (2009) Clustering high-dimensional data: a survey on subspace clustering, pattern-based clustering, and correlation clustering. TKDD 3(1):1–58. doi:10.1145/1497577.1497578
Li M, Fan Y, Chen J, Gao L, Di Z, Wu J (2005) Weighted networks of scientific communication: the measurement and topological role of weight. Physica A: Stat Mech Appl 350(2):643–656
Liu G, Wong L (2008) Effective pruning techniques for mining quasi-cliques. In: ECML/PKDD (2), pp 33–49
Moser F, Colak R, Rafiey A, Ester M (2009) Mining cohesive patterns from graphs with feature vectors. In: SDM, pp 593–604
Müller E, Assent I, Günnemann S, Krieger R, Seidl T (2009) Relevant subspace clustering: mining the most interesting non-redundant concepts in high dimensional data. In: ICDM, pp 377–386
Müller E, Günnemann S, Assent I, Seidl T (2009) Evaluating clustering in subspace projections of high dimensional data. In: VLDB, pp 1270–1281
Neville J, Adler M, Jensen D (2004) Spectral clustering with links and attributes. University of Massachusetts Amherst, Technical Report, Department of Computer Science
Pearl J (1984) Heuristics: intelligent search strategies for computer problem solving. Addison-Wesley Pub. Co., Inc, Reading
Pei J, Jiang D, Zhang A (2005) On mining cross-graph quasi-cliques. In: SIGKDD, pp 228–238
Qi G, Aggarwal C, Huang T (2012) Community detection with edge content in social media networks. In: ICDE, pp 534–545
Rymon R (1992) Search through systematic set enumeration. In: KR, pp 539–550
Shiga M, Takigawa I, Mamitsuka H (2007) A spectral clustering approach to optimally combining numerical vectors with a modular network. In: SIGKDD, pp 647–656
Spielmat D, Teng S (1996) Spectral partitioning works: planar graphs and finite element meshes. In: FOCS, pp 96–105
Spyropoulou E, De Bie T (2011) Interesting multi-relational patterns. In: ICDM, pp 675–684
Tang L, Wang X, Liu H (2009a) Uncovering groups via heterogeneous interaction analysis. In: ICDM, pp 503–512
Tang W, Lu Z, Dhillon IS (2009b) Clustering with multiple graphs. In: Ninth IEEE international conference on data mining, ICDM’09, pp 1016–1021
Tang L, Wang X, Liu H (2012) Community detection via heterogeneous interaction analysis. DMKD 25(1):1–33
Wang J, Zeng Z, Zhou L (2006) Clan: an algorithm for mining closed cliques from large dense graph databases. In: ICDE, p 73. doi:10.1109/ICDE.2006.34
Wu Z, Yin W, Cao J, Xu G, Cuzzocrea A (2013) Community detection in multi-relational social networks. In: Web Information Systems Engineering-WISE 2013. Springer, pp 43–56
Zeng Z, Wang J, Zhou L, Karypis G (2006) Coherent closed quasi-clique discovery from large dense graph databases. In: SIGKDD, pp 797–802
Zhou W, Jin H, Liu Y (2012) Community discovery and profiling with social messages. In: SIGKDD, pp 388–396
Zhou Y, Cheng H, Yu JX (2009) Graph clustering based on structural/attribute similarities. PVLDB 2(1):718–729
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Boden, B., Günnemann, S., Hoffmann, H. et al. MiMAG: mining coherent subgraphs in multi-layer graphs with edge labels. Knowl Inf Syst 50, 417–446 (2017). https://doi.org/10.1007/s10115-016-0949-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-016-0949-5