
Abstract
In this paper, we propose a page clipping search engine based on page discussion topics. Compared to other search engines, our search engine uses the page discussion topic instead of the search engine results page as the main result. After the user selects the topic of interest, our search engine will clip the relevant pages according to the selected topic and produce an integrated page result. The advantage of this topic-based integration page result is that the user can reduce the time it takes to decide whether the page content is relevant. Our results consist of two parts: the query-related discussion topics and the clipping results for relevant pages. We first use an adjusted N-gram language model and a hash method to produce discussion topics. At the same time, we use the idea of binary coding and mathematical set to organize related topics into a hierarchical topic tree with parent–child relationship. Next, we use a cost-effective genetic algorithm to produce the relevant page clipping results. This study has the following three advantages. The first is that we can find multiple clustering relationships, that is, a child topic can appear simultaneously in multiple parent topics. The second is that we propose a good topic generation method, that is, we cannot only produce better quality topics, but also produce the topic tree in a linear time. The third is that we propose a good clipping generation method, that is, we cannot only produce better quality clippings, but also produce a cost-effective solution.






Similar content being viewed by others
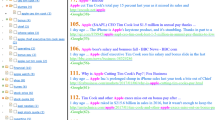


Notes
References
Abu Arqub O, Abo-Hammour Z, Momani S (2014) Application of continuous genetic algorithm for nonlinear system of second-order boundary value problems. Appl Math Inf Sci 8(1):235–248
Al Jadaan O, Rajamani L, Rao C (2008) Improved selection operator for GA. J Theor Appl Inf Technol 4(4):269–277
Banu WA, Kader PSA (2010) A hybrid context based approach for web information retrieval. Int J Comput Appl 10(7):25–28
Bhunia AK, Sahoo L, Roy D (2010) Reliability stochastic optimization for a series system with interval component reliability via genetic algorithm. Appl Math Comput 216(3):929–939
Carpineto C, Osinski S, Romano G, Weiss D (2009) A survey of web clustering engines. ACM Comput Surv 41(3):17:11–17:38
Chen L-C (2011) Building a web-snippet clustering system based on a mixed clustering method. Online Inf Rev 35(4):611–635
Chen L-C, Luh C-J (2005) Web page prediction from metasearch results. Internet Res 15(4):421–446
Chen L-C, Luh C-J, Jou C (2005) Generating page clippings from web search results using a dynamically terminated genetic algorithm. Inf Syst 30(4):299–316
Cilibrasi RL, Vitanyi PMB (2007) The google similarity distance. IEEE Trans Knowl Data Eng 19(3):370–383
Croft B, Lafferty J (2013) Language modeling for information retrieval. Springer, New York
Croft B, Metzler D, Strohman T (2009) Search engines: information retrieval in practice. Pearson Press, Pearson
Ferragina P, Guli A (2008) A personalized search engine based on web-snippet hierarchical clustering. Softw Pract Exp 38(2):189–225
Fox C (1989) A stop list for general text. ACM SIGIR Forum 24(1–2):19–35
Hammache A, Boughanem M, Ahmed-Ouamer R (2014) Combining compound and single terms under language model framework. Knowl Inf Syst 39(2):329–349
Hinow M, Mevissen M (2011) Substation maintenance strategy adaptation for life-cycle cost reduction using genetic algorithm. IEEE Trans Power Deliv 26(1):197–204
Ho W, Ho GT, Ji P, Lau HC (2008) A hybrid genetic algorithm for the multi-depot vehicle routing problem. Eng Appl Artif Intell 21(4):548–557
Huang C-L, Wang C-J (2006) A GA-based feature selection and parameters optimization for support vector machines. Expert Syst Appl 31(2):231–240
Indira SU, Ramesh AC (2011) Image segmentation using artificial neural network and genetic algorithm: a comparative analysis. In: Proceedings of the 2011 international conference on process automation, control and computing, pp 1–6
Ivanov V, Palyukh B, Sotnikov A (2016) Efficiency of genetic algorithm for subject search queries. Lobachevskii J Math 37(3):244–254
Jinarat S, Haruechaiyasak C, Rungsawang A (2015) Graph-based concept clustering for web search results. Int J Electr Comput Eng 5(6):1536–1544
Kaur M, Kaur P, Singh M (2015) Rank aggregation using multi objective genetic algorithm. In: Proceedings of the 2015 1st international conference on next generation computing technologies (NGCT), pp 836–840
Lau JH, Cook P, Baldwin T (2013) Topic modelling-based word sense induction for web snippet clustering. In: Proceedings of the 7th international workshop on semantic evaluation, pp 217–221
Lindsey R, Veksler VD, Grintsvayg A, Gray WD (2007) Be wary of what your computer reads: the effects of corpus selection on measuring semantic relatedness. In: Proceedings of the 8th international conference on cognitive modeling. Taylor & Francis Press, Ann Arbor, Michigan, pp 279–284
Martín P, Sierra A (2016) Improving power system static security margins by means of a real coded genetic algorithm. IEEE Trans Power Syst 31(3):1915–1924
Meng W, Wang W, Sun H, Yu C (2002) Concept hierarchy-based text database categorization. Knowl Inf Syst 4(2):132–150
Nirkhi S, Hande K (2008) A survey on clustering algorithms for web applications. In: Proceedings of the 2008 international conference on semantic web and web services. CSREA Press, Las Vegas, Nevada, July 14–17, 2008
Özel SA (2011) A web page classification system based on a genetic algorithm using tagged-terms as features. Expert Syst Appl 38(4):3407–3415
Prakash BR, Hanumanthappa M (2012) Web snippet clustering and labeling using lingo algorithm. Int J Adv Res Comput Sci 3(2):262–265
Prakash S, Vidyarthi D (2011) Load balancing in computational grid using genetic algorithm. Adv Comput 1(1):8–17
Quan X, Liu G, Lu Z, Ni X, Wenyin L (2010) Short text similarity based on probabilistic topics. Knowl Inf Syst 25(3):473–491
Recchia G, Jones MN (2009) More data trumps smarter algorithms: comparing pointwise mutual information with latent semantic analysis. Behav Res Methods 41(3):647–656
Sadaf K, Alam M (2012) Web search result clustering—a review. Int J Comput Sci Eng Surv 3(4):85–92
Scaiella U, Ferragina P, Marino A, Ciaramita M (2012) Topical clustering of search results. In: Proceedings of the 5th ACM international conference on web search and data mining, pp 223–232
Spink A, Wolfram D, Jansen MBJ, Saracevic T (2001) Searching the web: the public and their queries. J Am Soc Inform Sci Technol 52(3):226–234
Sun X, Gong D, Jin Y, Chen S (2013) A new surrogate-assisted interactive genetic algorithm with weighted semisupervised learning. IEEE Trans Cybern 43(2):685–698
Tomašev N, Mladenić D (2014) Hubness-aware shared neighbor distances for high-dimensional K-nearest neighbor classification. Knowl Inf Syst 39(1):89–122
Uğuz H (2011) A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm. Knowl Based Syst 24(7):1024–1032
Voorhees EM (1999) The TREC-8 question answering track report. In: Proceedings of the 8th text retrieval conference, pp 77–82
Wang Q, Qian Y, Song R, Dou Z, Zhang F, Sakai T, Zheng Q (2013) Mining subtopics from text fragments for a web query. Inf Retr 16(4):484–503
Wang Y, Chen W, Tellambura C (2012) Genetic algorithm based nearly optimal peak reduction tone set selection for adaptive amplitude clipping PAPR reduction. IEEE Trans Broadcast 58(3):462–471
Zamir O, Etzioni O (1999) Grouper: a dynamic clustering interface to web search results. Comput Netw 31(11–16):1361–1374
Zhao H, Qi Z (2010) Hierarchical agglomerative clustering with ordering constraints. In: Proceedings of the 2010 3rd international conference on knowledge discovery and data mining, Phuket, 9–10 January 2010, pp 195–199
Zhou F, Liu X (2005) An improved genetic algorithm of suited web-based negotiation support system. Comput Eng 23:061
Zhu X, Lu P (2009) A two-phase scheduling strategy for real-time applications with security requirements on heterogeneous clusters. Comput Electr Eng 35(6):980–993
Acknowledgements
We would like to thank the anonymous reviewers of the paper for their constructive comments, which have helped us to improve this paper in several ways. This work was supported in part by the Ministry of Science and Technology, Taiwan under Grant Most 106-2410-H-259-011 and 105-2221-E-259-030.
Author information
Authors and Affiliations
Corresponding author
Additional information
The URL of the experimental system for this study is http://hlcs.sytes.net/gap.
Rights and permissions
About this article

Cite this article
Chen, LC. A novel page clipping search engine based on page discussion topics. Knowl Inf Syst 58, 525–550 (2019). https://doi.org/10.1007/s10115-018-1173-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-018-1173-2