
Abstract
Policy iteration algorithms for partially observable Markov decision processes (POMDPs) offer the benefits of quicker convergence compared to value iteration and the ability to operate directly on the solution, which usually takes the form of a finite state automaton. However, the finite state controller tends to grow quickly in size across iterations due to which its evaluation and improvement become computationally costly. Bounded policy iteration provides a way of keeping the controller size fixed while improving it monotonically until convergence, although it is susceptible to getting trapped in local optima. Despite these limitations, policy iteration algorithms are viable alternatives to value iteration, and allow POMDPs to scale. In this article, we generalize the bounded policy iteration technique to problems involving multiple agents. Specifically, we show how we may perform bounded policy iteration with anytime behavior in settings formalized by the interactive POMDP framework, which generalizes POMDPs to non-stationary contexts shared with multiple other agents. Although policy iteration has been extended to decentralized POMDPs, the context there is strictly cooperative. Its novel generalization in this article makes it useful in non-cooperative settings as well. As interactive POMDPs involve modeling other agents sharing the environment, we ascribe controllers to predict others’ actions, with the benefit that the controllers compactly represent the model space. We show how we may exploit the agent’s initial belief, often available, toward further improving the controller, particularly in large domains, though at the expense of increased computations, which we compensate. We extensively evaluate the approach on multiple problem domains with some that are significantly large in their dimensions, and in contexts with uncertainty about the other agent’s frames and those involving multiple other agents, and demonstrate its properties and scalability.











Similar content being viewed by others


Notes
Note that the definition of a belief rests on first defining the underlying state space. The state space is not explicitly stated in the intentional model for brevity.
One way of obtaining a POMDP at level 0 is to use a fixed distribution over the other agent’s actions and fold it into \(T_j, O_j\) and \(R_j\) as noise.
Precluding considerations of computability, if the prior belief over \(IS_{i,l}\) is a probability density function, then \(\sum _{is_{i,l}|\hat{\theta }_j=\hat{\theta }_j'}\) is replaced by an integral over the continuous space. In this case, \(Pr(b'_{j,l-1}| b_{j,l-1}, a_j, o_j)\) is replaced with a Dirac-delta function, \(\delta _D(SE_{\theta _{j,l-1}(b_{j,l-1},a_j,o_j)} - b'_{j,l-1})\), where \(SE_{\theta _{j,l-1}}(\cdot )\) denotes state estimation involving the belief update of agent \(j\). These substitutions also apply elsewhere as appropriate.
A node in the controller mapped to an action distribution may be split into multiple nodes. Each node is deterministically mapped to a single action and incoming edges to the original node now connect to the split nodes with the action distribution.
Fig. 1 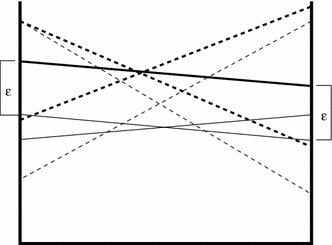
The dashed vectors constitute the optimal, backed up value function. Value vector (solid line in bold), representing a node in the improved controller, is a convex combination of the two dashed backed-up vectors in bold. It point-wise dominates a vector that constitutes the value function of the previous controller, by \(\epsilon \). Notice that none of the dashed vectors fully dominate the previous vectors by themselves
Because probability measures are countably additive, Eq. (6) remains mathematically well-defined although the subset of intentional models that map to some \(f_{j,l-1}\) could be countably infinite. Of course, in practice we consider a finite set of intentional models for the other agent.
Example problems such as the multiagent tiger problem or user-specified problems may be solved using an implementation of I-BPI in our new online problem-solving environment using POMDP-based frameworks at http://lhotse.cs.uga.edu/pomdp.
Policy iteration [19] may result in near-optimal controllers and provides an upper bound for BPI. An implementation of policy iteration for solving these controllers did not converge even for the smaller multiagent tiger problem due to the large number of nodes added at each iteration. In particular, it failed to extend beyond two steps of improvement.
Fig. 8 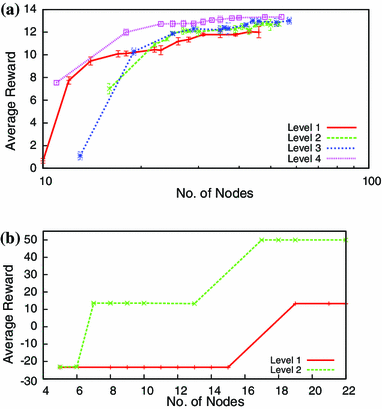
Average rewards for the (a) multiagent tiger problem on I-POMDP\(_{i,l}\) with \(l\) ranging from 1 to 4, and (b) AUAV reconnaissance on a \(3 \times 3\) grid with I-POMDP\(_{i,l}\) ranging from \(l=1\) to 2. The rewards generally improve and stabilize as we allocate more nodes to controllers to facilitate escaping local optima, in I-BPI. As we may expect, higher-level controllers generated for more strategic agents eventually lead to better rewards. Vertical bars indicate the standard deviation over trials, and is small


References
Amato, C., Bernstein, D. S., & Zilberstein, S. (2010). Optimizing fixed-size stochastic controllers for POMDPs and decentralized POMDPs. Journal of Autonomous Agents and Multi-Agent Systems, 21(3), 293–320.
Amato, C., Bonet, B. & Zilberstein, S. (2010). Finite-state controllers based on Mealy machines for centralized and decentralized POMDPs. In Twenty Fourth AAAI Conference on Artificial Intelligence (AAAI), pp. 1052–1058.
Aumann, R. J. (1999). Interactive epistemology II: Probability. International Journal of Game Theory, 28, 301–314.
Bernstein, D. S., Amato, C., Hansen, E., & Zilberstein, S. (2009). Policy iteration for decentralized control of Markov decision processes. Journal of Artificial Intelligence Research, 34, 89–132.
Bernstein, D. S., Givan, R., Immerman, N., & Zilberstein, S. (2002). The complexity of decentralized control of Markov decision processes. Mathematics of Operations Research, 27(4), 819–840.
Brandenburger, A., & Dekel, E. (1993). Hierarchies of beliefs and common knowledge. Journal of Economic Theory, 59, 189–198.
Cassandra, A. R., Littman, M. L., & Zhang, N. L. (1997). Incremental pruning: A simple, fast, exact method for partially observable Markov decision processes. In Proceedings of the Thirteenth Conference on Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers.
Dennett, D. (1986). Intentional systems. Brainstorms. Cambridge, MA: MIT Press.
Dongarra, J., Lumsdaine, A., Pozo, R. & Remington, K. (1992). A sparse matrix library in c++ for high performance architectures. In Second Object Oriented Numerics Conference, pp. 214–218.
Doshi, P. (2012). Decision making in complex multiagent settings: A tale of two frameworks. AI Magazine, 33(4), 82–95.
Doshi, P., & Gmytrasiewicz, P. J. (2009). Monte Carlo sampling methods for approximating interactive POMDPs. Journal of Artificial Intelligence Research, 34, 297–337.
Doshi, P. & Perez, D. (2008). Generalized point based value iteration for interactive POMDPs. In Twenty third conference on artificial intelligence (AAAI) (pp. 63–68).
Doshi, P., Qu, X., Goodie, A. & Young, D. (2010). Modeling recursive reasoning in humans using empirically informed interactive POMDPs. In International autonomous agents and multiagent systems conference (AAMAS) (pp. 1223–1230).
Fudenberg, D., & Levine, D. K. (1998). The theory of learning in games. Cambridge, MA: MIT Press.
Giudice, A. D. & Gmytrasiewicz, P. (2007). Towards strategic Kriegspiel play with opponent modeling. In Game theoretic and decision-theoretic agents, AAAI spring symposium (pp. 17–22).
Giudice, A. D. & Gmytrasiewicz, P. (2009). Towards strategic Kriegspiel play with opponent modeling (extended abstract). In Autonomous agents and multiagent systems conference (AAMAS) (pp. 1265–1266)
Gmytrasiewicz, P. J., & Doshi, P. (2005). A framework for sequential planning in multiagent settings. Journal of Artificial Intelligence Research, 24, 49–79.
Guo, Q., & Gmytrasiewicz, P. J. (2011). Modeling bounded rationality of agents during interactions (extended abstract). In International joint conference on autonomous agents and multi agent systems (AAMAS) (pp. 1285–1286).
Hansen, E. (1998). Solving POMDPs by searching in policy space. In Uncertainty in artificial intelligence (UAI) (pp. 211–219).
Hansen, E. (2008). Sparse stochastic finite-state controllers for POMDPs. In Proceedings of the 24th Conference on Uncertainty in Artificial Intelligence (UAI) (pp. 256–263). AUAI Press.
Harsanyi, J. C. (1967). Games with incomplete information played by Bayesian players. Management Science, 14(3), 159–182.
Hoey, J., & Poupart, P. (2005). Solving POMDPs with continuous or large discrete observation spaces. In International joint conference on AI (IJCAI) (pp. 1332–1338).
Hopcroft, J., & Ullman, J. (1979). Introduction to automata theory, languages, and computation. Reading, MA: Addison-wesley.
Kaelbling, L., Littman, M., & Cassandra, A. (1998). Planning and acting in partially observable stochastic domains. Artificial Intelligence, 101, 99–134.
Klee, V., & Minty, G. J. (1972). How good is the simplex algorithm? In O. Shisha (Ed.), Inequalities (Vol. III, pp. 159–175). New York: Academic Press.
Kurniawati, H., Hsu, D., & Lee, W. S. (2008). SARSOP: Efficient point-based POMDP planning by approximating optimally reachable belief spaces. In Robotics: Science and Systems (pp. 65–72).
Meissner, C. (2011). A complex game of cat and mouse. Lawrence Livermore National Laboratory Science and Technology Review (pp. 18–21).
Mertens, J., & Zamir, S. (1985). Formulation of Bayesian analysis for games with incomplete information. International Journal of Game Theory, 14, 1–29.
Nair, R., Tambe, M., Yokoo, M., Pynadath, D., & Marsella, S. (2003). Taming decentralized POMDPs: Towards efficient policy computation for multiagent settings. In: International joint conference on artificial intelligence (IJCAI) (pp. 705–711).
Ng, B., Meyers, C., Boakye, K., & Nitao, J. (2010). Towards applying interactive POMDPs to real-world adversary modeling. In Innovative applications in artificial intelligence (IAAI) (pp. 1814–1820).
Papadimitriou, C. H., & Tsitsiklis, J. N. (1987). The complexity of Markov decision processes. Mathematics of Operations Research, 12(3), 441–450.
Pineau, J., Gordon, G., & Thrun, S. (2006). Anytime point-based value iteration for large POMDPs. Journal of Artificial Intelligence Research, 27, 335–380.
Poupart, P., & Boutilier, C. (2003). Bounded finite state controllers. In Neural Information Processing Systems (NIPS) (pp. 823–830).
Poupart, P., & Boutilier, C. (2004). VDCBPI: An approximate algorithm scalable for large-scale POMDPs. In Neural Information Processing Systems (NIPS) (pp. 1081–1088).
Rathnasabapathy, B., Doshi, P., & Gmytrasiewicz, P.J. (2006). Exact solutions to interactive POMDPs using behavioral equivalence. In Autonomous agents and multi-agent systems conference (AAMAS) (pp. 1025–1032).
Seuken, S., & Zilberstein, S. (2008). Formal models and algorithms for decentralized decision making under uncertainty. Journal of Autonomous Agents and Multiagent Systems, 17(2), 190–250.
Seymour, R., & Peterson, G. L. (2009). Responding to sneaky agents in multi-agent domains. In Florida artificial intelligence research society conference (FLAIRS) (pp. 99–104).
Seymour, R., & Peterson, G. L. (2009). A trust-based multiagent system. In IEEE international conference on computational science and engineering (pp. 109–116).
Smallwood, R., & Sondik, E. (1973). The optimal control of partially observable Markov decision processes over a finite horizon. Operations Research, 21, 1071–1088.
Smith, T., & Simmons, R. (2004). Heuristic search value iteration for POMDPs. In Uncertainty in artificial intelligence (UAI) (pp. 520–527).
Sondik, E. J. (1978). The optimal control of partially observable Markov processes over the infinite horizon: Discounted cost. Operations Research, 26(2), 282–304.
Spielman, D. A., & Teng, S. H. (2004). Smoothed analysis of algorithms: Why the simplex algorithm usually takes polynomial time. Journal of the ACM, 51(3), 385–463.
Wang, F. (2013). An I-POMDP based multi-agent architecture for dialogue tutoring. In: International conference on advanced information and communication technology for education (ICAICTE) (pp. 486–489).
Woodward, M. P., & Wood, R. J. (2012). Learning from humans as an I-POMDP. CoRR abs/1204.0274.
Wunder, M., Kaisers, M., Yaros, J., & Littman, M. (2011). Using iterated reasoning to predict opponent strategies. In International conference on autonomous agents and multi-agent systems (AAMAS) (pp. 593–600).
Young, S., Gai, M., Keizer, S., Mairesse, F., Schatzmann, J., Thomson, B., et al. (2010). The hidden information state model: A practical framework for pomdp-based spoken dialogue management. Computer Speech and Language, 24(2), 150–174.
Zeng, Y., & Doshi, P. (2012). Exploiting model equivalences for solving interactive dynamic influence diagrams. Journal of Artificial Intelligence Research, 43, 211–255.
Acknowledgments
This research is supported in part by the NSF CAREER Grant, #IIS-0845036, and in part by an ONR Grant, #N000141310870. We thank Kofi Boakye and Brenda Ng at Lawrence Livermore National Laboratory for providing the domain files for the money laundering problem; Pascal Poupart at University of Waterloo for making his POMDP BPI implementation available to us, and the anonymous reviewers for their detailed and insightful comments.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
In settings involving multiple agents, \(1 \ldots K\), with the subject agent denoted as agent 1, and uncertainty over the other agents’ frames with each being ascribed multiple frames, the joint model space is the product of the model spaces of each other agent. Also, the transition, observation and reward functions of an agent depend on the joint actions of all agents. In such settings, Algorithms 1, 2 and 3 are adapted as follows.



Rights and permissions
About this article

Cite this article
Sonu, E., Doshi, P. Scalable solutions of interactive POMDPs using generalized and bounded policy iteration. Auton Agent Multi-Agent Syst 29, 455–494 (2015). https://doi.org/10.1007/s10458-014-9261-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10458-014-9261-5