
Abstract
The positive impact of emotions in decision-making has long been established in both natural and artificial agents. In the perspective of appraisal theories, emotions complement perceptual information, coloring our sensations and guiding our decision-making. However, when designing autonomous agents, is emotional appraisal the best complement to the perceptions? Mechanisms investigated in affective neuroscience provide support for this hypothesis in biological agents. In this paper, we look for similar support in artificial systems. We adopt the intrinsically motivated reinforcement learning framework to investigate different sources of information that can guide decision-making in learning agents, and an evolutionary approach based on genetic programming to identify a small set of such sources that have the largest impact on the performance of the agent in different tasks, as measured by an external evaluation signal. We then show that these sources of information: (i) are applicable in a wider range of environments than those where the agents evolved; (ii) exhibit interesting correspondences to emotional appraisal-like signals previously proposed in the literature, pointing towards our departing hypothesis that the appraisal process might indeed provide essential information to complement perceptual capabilities and thus guide decision-making.








Similar content being viewed by others



Notes
Perceptual information can be of an internal nature, e.g., about goals, needs or beliefs, or external, e.g., about objects or events from the environment.
We adopt a rather broad definition of signal. Specifically, we refer to an appraisal signal any emotional appraisal-based information received and processed, in this case, by the decision-making module.
In our approach, we use a fitness metric that directly measures the performance of the agent in the underlying task in different scenarios.
Typical RL scenarios assume that \({\mathcal {Z}}={\mathcal {S}}\) and \(\mathsf {O}(z\mid s,a)=\delta (z,s)\), where \(\delta \) denotes the Kronecker delta [42]. When this is the case, parameters \({\mathcal {Z}}\) and \(\mathsf {O}\) can be safely discarded and the simplified model thus obtained, represented as a tuple \({\mathcal {M}}=({\mathcal {S}},{\mathcal {A}},\mathsf {P},r,\gamma )\), is referred to as a Markov decision process (MDP).
Our RL agents all follow the prioritized sweeping algorithm and use the exploration policy detailed in Sect. 3.
We note that our choice in measuring the fitness as the cumulative external evaluation signal is only one among many other possible metrics. In the context of our study, we believe this to be a good metric as it allows us to directly measure the agent’s fitness from its performance in the underlying task in the environment.
More details on GP can be found in [15].
Recall that \(r^{\mathcal {F}}(s,a)\) rewards the agent in accordance with the increase/decrease of fitness caused by executing each \(a\) in each state \(s\).
The first generation, corresponding to the population \({\mathcal {R}}_1\), is randomly generated.
Fig. 5 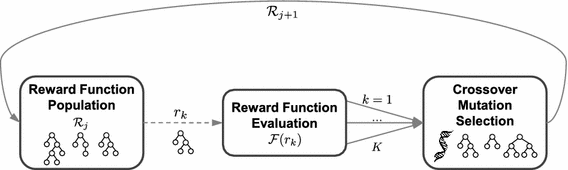
The GP approach to the ORP, as proposed in [25]. In each generation \(j\), a population \({\mathcal {R}}_{j}\) contains a set of candidate reward functions \(r_k,k=1,\ldots ,K\). All are evaluated according to a fitness function \({\mathcal {F}}(r_{k)}\) and evolve according to crossover, mutation and selection
We resorted to a simple unpaired \(t\) test to determine this statistical significance.
The set \({\mathcal {E}}\) is scenario-specific. For example, in the Hungry–Thirsty scenario, \({\mathcal {E}}\) includes all possible configurations of food and water.
The fence is only an obstacle when the agent is moving upward from position (1:2).
Denoting by \(n_t(\mathrm{fence})\) the number of times that the agent crossed the fence upwards up to time-step \(t\), \(N_t\) is given by \(N_t=\min \lbrace n_t(\mathrm{fence})+1;30\rbrace \).
We again emphasize that our identification procedure is not guided by appraisal theories, the objective for now is precisely to identify useful signals, regardless of their connection with emotional appraisal.
In our distillation process we are focused on extracting a minimal set domain-independent informative signals. As will become clearer in the next section, apart from additive constants (which have minimum impact on the policy and can therefore be safely discarded), it will be possible to reconstruct the reward functions (and attain comparable degrees of fitness) in Table 1 as a linear combination of these signals.
Further experimental verification would be required to back up this claim, however this is not within the scope of this paper.
We note that this section is more concerned with the computational applicability of the emerged signals. As such, we leave the analysis of their relation with emotional appraisal mechanisms for the discussion in Sect. 5.
The keeper ghost, when present, makes it difficult for Pac-Man to reach the central cell, essential for the completion of most scenarios.
Illustrative videos of the observed behaviors in different stages of the learning process in all the Pac-Man scenarios have been provided along with the submission (and are also available at http://gaips.inesc-id.pt/~psequeira/emot-emerg/).
Recall that in the seasons environments the value of preys depends on the current season, but this still is an external factor that the agent cannot act upon and change.
We refer to [34] where the reward functions included information about whether the agent was being considerate about other agents of the same population in the context of resource sharing scenarios.
Also, many theorists distinguish between primary appraisal, providing a rather crude evaluation but a fast, almost automatic response to events, and secondary appraisal, allowing a more deep and cognitive analysis of the situation and leading to more complex patterns of response throughout time by means of associative learning processes [6, 7, 16, 26]. In that matter, the IMRL framework itself supports this dual aspect of appraisal: on one hand, RL provides a fast evaluation of the perceived stimuli (the state) and provides responses (the actions) based on a single signal—the learned \(Q\)-value function; on the other hand, as time progresses during the agent’s lifetime, the intrinsic rewards will reflect more what was learned in the previous interactions thus providing a more accurate evaluation over the environment. We note however that this aspect is related with properties of the RL framework itself and not of our approach in particular.
We note that in the classical approach to RL, different problems will usually require distinct reward functions so that the agent is able to learn the intended task [42].

References
Ahn, H., & Picard, R. (2006). Affective cognitive learning and decision making: The role of emotions. Proceedings of the 18th European Meeting on Cybernetics and Systems Research, pp. 1–6.
Baird, L. (1993). Advantage updating. Technical Report WL-TR-93-1146, Wright Laboratory, Wright-Patterson Air Force Base.
Bechara, A., Damasio, H., & Damasio, A. (2000). Emotion, decision making and the orbitofrontal cortex. Cerebral Cortex, 10(3), 295–307.
Bratman, J., Singh, S., Lewis, R., & Sorg, J. (2012). Strong mitigation: Nesting search for good policies within search for good reward. Proceedings of the 11th International Joint Conference Autonomous Agents and Multiagent Systems.
Broekens, D., Kosters, W., & Verbeek, F. (2007). On affect and self-adaptation: Potential benefits of valence-controlled action-selection. Bio-inspired Modeling of Cognitive Tasks: Proceedings of the 2nd International Conference Interplay Between Natural and Artificial Computation, pp. 357–366.
Cardinal, R., Parkinson, J., Hall, J., & Everitt, B. (2002). Emotion and motivation: the role of the amygdala, ventral striatum, and prefrontal cortex. Neuroscience and Biobehavioral Reviews, 26(3), 321–352.
Damasio, A. (1994). Descartes’ error: Emotion, reason, and the human brain. New York: Putnam Publishing.
Dawkins, M. (2000). Animal minds and animal emotions. American Zoologist, 40(6), 883–888.
Ellsworth, P., & Scherer, K. (2003). Appraisal processes in emotion. In R. Davidson, K. Scherer, & H. Goldsmith (Eds.), Handbook of the affective sciences. New York: Oxford University Press.
Frijda, N., & Mesquita, B. (1998). The analysis of emotions: dimensions of variation. In M. Mascolo & S. Griffin (Eds.), What develops in emotional development? (Emotions, personality, and psychotherapy). New York: Springer.
Gadanho, S., & Hallam, J. (2001). Robot learning driven by emotions. Adaptive Behavior, 9(1), 42–64.
Hester, T., Stone, P. (2012). Intrinsically motivated model learning for a developing curious agent. Procssdings of the IEEE International Conference on Development and Learning and Epigenetic Robotics, pp. 1–6. ICDL 2013.
Kaelbling, L., Littman, M., & Moore, A. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
Kaelbling, L., Littman, M., & Cassandra, A. (1998). Planning and acting in partially observable stochastic domains. Artificial Intelligence, 101, 99–134.
Koza, J. (1992). Genetic programming: On the programming of computers by means of natural selection. Cambridge: MIT Press.
Lazarus, R. (2001). Relational meaning and discrete emotions. In K. Scherer, A. Schorr, & T. Johnstone (Eds.), Appraisal processes in emotion: Theory, methods, research. New York: Oxford University Press.
LeDoux, J. (2000). Emotion circuits in the brain. Annual Review of Neuroscience, 23(1), 155–184.
Leventhal, H., & Scherer, K. (1987). The relationship of emotion to cognition: A functional approach to a semantic controversy. Cognition and Emotion, 1(1), 3–28.
Littman, M. (1994). Memoryless policies: Theoretical limitations and practical results. Proceedings of the 3rd International Conference Simulation of Adaptive Behavior-From Animals to Animats 3.
Lopes, M., Lang, T., Toussaint, M., & Oudeyer, P.-Y. (2012). Exploration in model-based reinforcement learning by empirically estimating learning progress. Advances in Neural Information Processing Systems 25, pp. 206–214.
Marinier, R. (2008). A computational unification of cognitive control, emotion, and learning. Phd thesis, University of Michigan, Ann Arbor, MI.
Marsella, S., & Gratch, J. (2009). Ema: A process model of appraisal dynamics. Cognitive Systems Research, 10(1), 70–90.
Marsella, S., Gratch, J., & Petta, P. (2010). Computational models of emotion. In K. Scherer, T. Bänziger, & E. Roesch (Eds.), Blueprint for affective computing. New York: Oxford University Press.
Moore, A., & Atkeson, C. (1993). Prioritized sweeping: Reinforcement learning with less data and less real time. Machine Learning, 13, 103–130.
Niekum, Scott, Barto, Andrew G., & Spector, Lee. (2010). Genetic programming for reward function search. IEEE Transactions on Autonomous Mental Development, 2(2), 83–90.
Oatley, K., & Jenkins, J. (2006). Understanding emotions. Oxford: Wiley-Blackwell.
Phelps, E., & LeDoux, J. (2005). Contributions of the amygdala to emotion processing: From animal models to human behavior. Neuron, 48(2), 175–187.
Roseman, I., & Smith, C. (2001). Appraisal theory: Overview, assumptions, varieties, controversies, research. In K. Scherer, A. Schorr, & T. Johnstone (Eds.), Appraisal processes in emotion: Theory, methods. Oxford: Oxford University Press.
Rumbell, T., Barnden, J., Denham, S., & Wennekers, T. (2011). Emotions in autonomous agents: Comparative analysis of mechanisms and functions. Autonomous Agents and Multiagent Systems, 25(1), 1–45.
Salichs, M., Malfaz, M. (2006). Using emotions on autonomous agents: The role of happiness, sadness and fear. In Proceedings of the Annual Conference on Ambient Intelligence and Simulated Behavior, pp. 157–164.
Salichs, M., & Malfaz, M. (2012). A new approach to modeling emotions and their use on a decision-making system for artificial agents. IEEE Transactions on Affective Computing, 3(1), 56–68.
Scherer, K. (2001). Appraisal considered as a process of multilevel sequential checking, research. In K. Scherer, A. Schorr, & T. Johnstone (Eds.), Appraisal processes in emotion: Theory, methods. Oxford: Oxford University Press.
Sequeira, P., Melo, F.S., & Paiva, A. (2011a). Emotion-based intrinsic motivation for reinforcement learning agents. Proceedings of the 4th International Conference Affective Computing and Intelligent Interaction, pp. 326–336.
Sequeira, P., Melo, F.S., Prada, R., & Paiva, A. (2011b). Emerging social awareness: Exploring intrinsic motivation in multiagent learning. Proceedings of the 1st IEEE International Joint Conference Development and Learning and Epigenetic Robotics, vol 2, pp. 1–6.
Sequeira, P., Melo, F.S., & Paiva, A. (2012). Learning by appraising: An emotion-based approach for intrinsic reward design. Technical, Report GAIPS-TR-001-12, INESC-ID.
Si, M., Marsella, S., & Pynadath, D. (2010). Modeling appraisal in theory of mind reasoning. Autonomous Agents and Multi-Agent Systems, 20(1), 14–31.
Singh, S., Jaakkola, T., & Jordan, M. (1994). Learning without state estimation in partially observable Markovian decision processes. Proceedings of the 11th International Conference Machine Learning, pp. 284–292.
Singh, S., Lewis, R., & Barto, A. (2009). Where do rewards come from? Proceedings of the Annual Conference Cognitive Science Society, pp. 2601–2606.
Singh, S., Lewis, R., Barto, A., & Sorg, J. (2010). Intrinsically motivated reinforcement learning: An evolutionary perspective. IEEE Transactions on Autonomous Mental Development, 2(2), 70–82.
Sorg, J., Singh, S., & Lewis, R. (2010a). Internal rewards mitigate agent boundedness. Proceedings of the 27th International Conference Machine Learning, pp. 1007–1014.
Sorg, J., Singh, S., & Lewis, R. (2010b). Reward design via online gradient ascent. Advances in Neural Information Processing Systems, 23, 1–9.
Sutton, R., & Barto, A. (1998). Reinforcement learning: An introduction. Cambridge: The MIT Press.
Syswerda, G. (1989). Uniform crossover in genetic algorithms. Proceedings of the 3rd International Conference Genetic Algorithms, pp. 2–9). CA, USA: San Francisco.
Acknowledgments
This work was partially supported by the Portuguese Fundação para a Ciência e a Tecnologia (FCT) under project PEst-OE/EEI/LA0021/2013 and the EU project SEMIRA through the grant ERA-Compl /0002/2009. The first author acknowledges Grant SFRH/BD/38681/2007 from the FCT.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary material 1 (mp4 10873 KB)
Supplementary material 2 (mp4 10955 KB)
Supplementary material 3 (mp4 11009 KB)
Supplementary material 4 (mp4 10951 KB)
Rights and permissions
About this article

Cite this article
Sequeira, P., Melo, F.S. & Paiva, A. Emergence of emotional appraisal signals in reinforcement learning agents. Auton Agent Multi-Agent Syst 29, 537–568 (2015). https://doi.org/10.1007/s10458-014-9262-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10458-014-9262-4