
Abstract
This paper studies a generalized cumulative shock model with a cluster shock structure. The system considered is subject to two types of shocks, called primary shocks and secondary shocks, where each primary shock causes a series of secondary shocks. The lifetime behavior of such a system becomes more complicated than that of a classical model with only one class of shocks. Under a non-homogeneous Poisson process of primary shocks, we analyze the lifetime behavior of the system with light-tailed and heavy-tailed distributed secondary shocks. We show some important characteristics of lifetime of this type of system. Our model, as an extension of the classical shock models, has wide applications in maintenance engineering, operations management, and insurance risk assessment.




Similar content being viewed by others


Notes
On page 174 of their book, Daley and Vere-Jones said: cluster processes form one of the most important and widely used models in point process studies, whether applied or theoretical, they are natural models for the locations of objects in the plane or in three-dimensional space.
References
Agrafiotis, G. K., & Tsoukalas, M. Z. (1995). On excess-time correlated cumulative processes. Journal of the Operational Research Society, 46, 1269–1280.
Albrecherab, H., & Asmussen, S. (2006). Ruin probabilities and aggregate claims distributions for shot noise Cox processes. Scandinavian Actuarial Journal, 2, 86–110.
Bai, J. M., Li, Z. H., & Kong, X. B. (2006). Generalized shock models based on a cluster point process. IEEE Transactions on Reliability, 55, 542–550.
Bai, J. M., & Xiao, H. M. (2008). A class of new cumulative shock models and its application in insurance risk. Journal of Lanzhou University (Natural Sciences), 44, 132–136.
Daley, D. J., & Vere-Jones, D. (2003). An introduction to the theory of point processes, Vol. I (2nd ed.). New York: Springer.
von Elart, C. (1999). Control of production processes subject to random shocks. Annals of Operations Research, 91, 289–304.
Finkelstein, M. S., & Zarudnij, V. I. (2001). A shock process with a non-cumulative damage. Reliability Engineering & Systems Safety, 71, 103–107.
Goldie, C. M., & Klüppelberg, C. (1998). Subexponential distributions (a practical guide to heavy tails: statistical techniques for analyzing heavy tailed distributions) (pp. 435–459). Boston: Birkhäuser.
Gut, A. (1990). Cumulative shock models. Advances in Applied Probability, 22, 504–507.
Gut, A. (2001). Mixed shock models. Bernoulli, 7, 541–555.
Hohn, N., Veitch, D., & Abry, P. (2003). Cluster processes: a natural language for network traffic. IEEE Transactions on Signal Processing, 51, 2229–2244.
Igaki, N., Sumita, U., & Kowada, M. (1995). Analysis of Markov renewal shock models. Journal of Applied Probability, 32, 821–831.
Jeffrey, P. K., Steven, M. C., & Mark, E. O. (2011). Reliability of manufacturing equipment in complex environments. Annals of Operations Research. doi:10.1007/s10479-011-0839-x.
Lewis, P. A. W. (1964). A branching Poisson process model for the analysis of computer failure patterns. Journal of the Royal Statistical Society. Series B, 26, 398–456.
Li, Z. H., & Kong, X. B. (2007). A new risk model based on policy entrance process and its weak convergence properties. Applied Stochastic Models in Business and Industry, 23, 235–246.
Mallor, F., & Omey, E. (2001). Shocks, runs and random sums. Journal of Applied Probability, 38, 438–448.
Mallor, F., & Omey, E. (2002). Shocks, runs and random sums: asymptotic behaviour of the tail of the distribution function. Mathematical Sciences, 111, 3449–3565.
Mikosch, T. (1999). Regular variation, subexponentiality and their applications in probability theory. Eurandom report, 1999-013.
Nader, A., Georgios, K. D. S., Hamid, D., Hooman, M., & Seyed, A. Y. (2012). Strategies for protecting supply chain networks against facility and transportation disruptions: an improved Benders decomposition approach. Annals of Operations Research. doi:10.1007/s10479-012-1146-x.
Ramirez-Perez, F., & Serfling, R. (2001). Shot noise on cluster processes with cluster marks, and studies of long range dependence. Advances in Applied Probability, 33, 631–651.
Ramirez-Perez, F., & Serfling, R. (2003). Asymptotic normality of shot noise on Poisson cluster processes with cluster marks. Journal of Probability and Statistical Science, 1, 157–172.
Rolski, T., Schmidli, H., Schmidt, V., & Teugels, J. (1999). Stochastic processes for insurance and finance. Chichester: Wiley.
Sara, L., & de Jacques, M. (2011). Maintenance for reliability: a case study. Annals of Operations Research. doi:10.1007/s10479-011-0873-8.
Sheu, S. H., Chang, C. C., & Chien, Y. H. (2011). Optimal age-replacement time with minimal repair based on cumulative repair-cost limit for a system subject to shocks. Annals of Operations Research, 186, 317–329.
Skoulakis, G. (2000). A general shock model for a reliability system. Journal of Applied Probability, 37, 925–935.
Sumita, U., & Shanthikumar, J. G. (1985). A class of correlated cumulative shock models. Advances in Applied Probability, 17, 347–366.
Xiao, H. M., Li, Z. H., & Liu, W. W. (2008). The limit behavior of a risk model based on entrance processes. Computers & Mathematics With Applications, 56, 1434–1440.
Acknowledgements
This work is supported by the Natural Science Foundation of China 71171103 and 10871086 and the NSERC grant RGPIN197319 of Canada. The authors would like to thank the editor and the anonymous referees for their valuable comments and suggestions and also are grateful to Dr. Zhi Liu and Dr. Yanjun Shi for their help in creating the illustrations.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
The proofs of Theorems 1–4 are based on some preliminaries. Using the definitions of the cumulative shock process {X(t)} and the ultimate failure probability ψ,

we define a new process {X′(t)}, the variant version of {X(t)}, as
where r=−1, 0 or 1. On the relation between {X(t)} and {X′(t)}, we have the following result.
Lemma A.1
For each t>0, X′(t)≥X(t).
Lemma A.1 says that {X′(t)} is “larger” than {X(t)}. However, we can show, for an arbitrary δ>0, that

where Λ(t) is the cumulative intensity function of the primary shock process {N(t)}, and the symbol “\(\xrightarrow{\mathrm{p}}\)” stands for convergence in probability. It means that the difference in probability between {X(t)} and {X′(t)} becomes negligible after a long period of time.
Also, we define a discrete process {Z n } as

Then Z n is the embedded process of {X′(t)} and records the state of {X′(t)} at time instant S n , while the nth primary shock occurs and {X′(t)} has a downward jump. It is clear that, for n=0,1,… ,

where \(\xi_{i}=rX_{i}+\sum_{j=1}^{M_{i}(C_{i})}Y_{ij}\), i=1,2,… , are i.i.d. random variables by Assumptions (ii)–(iv).
Now we prove Theorems 1–4.
Proof of Theorem 1
When r=1 or 0, {Z n } is a renewal process with the renewal interval

For a given z>0, define the “lifetimes” τ′ and N for the processes {X′(t)} and {Z n }, respectively,


It is clear that τ′=S N , where S N is the Nth shock arrival instant of the primary process {N(t)}, and N is an almost surely finite stopping-time of {Z n } with the discrete distribution

where F ξ is the common distribution function of ξ i and the symbol “∗” represents convolution operation.
It follows from Lemma A.1, (A.5) and (A.6) that the system lifetime τ satisfies

then
Now we can estimate the lower bound of E[τ] by computing E[S N ]. Since {N(t)} is a non-homogeneous Poisson, for s>0, we have

Hence,

Using (A.8), we have
where p n =Pr{N=n} is given by (A.7). □
Proof of Theorem 2
If {N(t)} is a homogeneous Poisson with intensity λ>0, let B n =S n −S n−1, n=1,2,… , be the inter-arrival time, then E[B n ]=1/λ. Hence,
To find E[N], based on renewal process {Z n } and using Wald Identity, we have

Secondly, because of exponentially distributed Y ij with parameter μ>0, for an arbitrary x≥z, we obtain

Thus the density function of Z N is \(f_{{ Z_{N}}}(x)=\mu e^{-\mu(x-z)}\), and

Then the expected stopping-time is
Using (A.8), (A.10) and (A.11), we have

where r=1 or 0. □
Proof of Theorem 3
In the case of r=−1, we have

where \(\xi_{i}=\sum_{j=1}^{M_{i}(C_{i})}Y_{ij}-X_{i}\), i=1,2,… are i.i.d. random variables. Thus {Z n } is a random walk starting from the origin. Also, by Assumption (v), {Z n } is transient and has an average downward drift. Let

be the probability that {Z n } eventually exceeds level z. Since {Z n } is the embedded process of {X′(t)}, they have a same limiting probability. Then, it follows from Lemma A1 that the probabilities of {X(t)} and {Z n } eventually exceeding z satisfy
Thus we can evaluate the upper-bound of ψ by estimating p Z . The next lemma gives an exponential-type estimation of p Z .
Lemma A.2
Under Assumptions (ii)–(v), if \(E[e^{sY_{ij}}]\) exists, then

where θ>0 is determined by the equation

Proof
For some y>0 and n=0,1,… , define

where θ is a positive number satisfying (A.13). Then κ is obviously a stopping time with respect to the natural filtration of {Z n }:

and {M
n
} is a martingale with respect to  . Therefore, we have
. Therefore, we have


By applying the martingale stopping theorem to {M n } and κ, we have

Conditioning on Z κ in \(E[M_{\kappa}]=E[e^{\theta Z_{\kappa}}]\), we obtain
where q denotes the probability that the random walk {Z n } exceeds z before it reaches −y.
Let y→∞, the second term on the left hand side of (A.14) tends to 0, then

Note that, when y goes to positive infinity, the limiting probability of {Z n } exceeding z before reaching −y is just the probability of exceeding z, so lim y→∞ q=p Z (u). Using the Jensen’s Inequality, we have

This means p Z ≤e −θz with θ>0 satisfying (A.13).
Using (A.12) and Lemma A.2, we complete the proof of Theorem 3. □
Proof of Theorem 4
According to the proof of Theorem 3, we need to show

where θ>0. For this, we take y→∞ in (A.14) and get

First, for the exponential distribution, we can calculate the conditional expectation of the denominator in (A.16). For some x≥0, we have

where \(\sum_{n}=\sum_{n=0}^{\infty}\), p n =Pr{κ=n}, \(p_{\Delta}=\prod_{i=1}^{n}\Pr\{M_{i}(C_{i})=m_{i}\}\), \(\sum_{\Delta}=\sum_{m_{1}}\sum_{m_{2}}\cdots\allowbreak \sum_{m_{n}}\), \(\Delta^{\prime}=\Delta_{i=1}^{\prime n}(\sum_{j=1}^{m_{i}}Y_{ij}-X_{i})-Y_{nm_{n}}\), and F Δ′ denotes the distribution function of Δ′. Thus we have the conditional density

and the conditional expectation

Therefore, (A.15) is obtained by putting this result in (A.16).
Next, to determine the parameter θ, we use \(E[e^{\theta Y_{11}}]=\frac{\beta}{\beta-\theta}\) and get

where q k =Pr{M 1(C 1)=k}. Since {M n } is a martingale, \(E[e^{\theta\xi_{1}}]=E[M_{1}]\) =E[M 0]=1, then

That is, θ satisfies Eq. (11). □
Proof of Theorem 5
We prove Theorem 5 in several steps and start with a representation of the primary shock process,

where K i (t)=M i ((t−S i )∧C i ) and

Also, we rewrite ψ(t), the failure probability of the system within finite horizon (0,t] defined in (5), as

To complete the proof, we need the following two lemmas.
Lemma A.3
Given t<∞, the probability ψ(t) satisfies
-
(i)
for r=1,0,
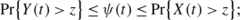
-
(ii)
for r=−1,
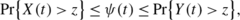
where Y(t) is given by (A.17).
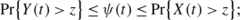
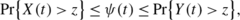
Proof
Obviously. □
Lemma A.4
Under Assumption (vii), if the magnitudes \(Y_{11}^{I}\) and \(Y_{11}^{\mathit{II}}\) of the two classes of adjunctive shocks have the regular-tailed distributions \(F_{\alpha}^{I}(y)\) and \(F_{\alpha}^{\mathit{II}}(y)\), respectively, with a common index α>0, then, for given t<∞,

Proof
The proof is based on the classification and the main technique is using the closure properties of regular-tailed distribution family. By Assumption (vii), we know that Class I and Class II of shocks are mutually independent. This implies that the primary shock process {N(t)} is formed by two independent shock processes {N I(t)} and {N II(t)} relating to the two classes, which are also non-homogeneous Poisson and satisfy N I(t)+N II(t)=N(t) for each t>0. The relation between the adjunct shock processes \(\{M_{i}^{I}(t)\}\) and \(\{M_{i}^{\mathit{II}}(t)\}\) is similar.
First, we calculate the probability Pr{X(t)>z}. For given t<∞,

where \(K^{I}_{i}(t)=M^{I}_{i}((t-S^{I}_{i})\wedge C^{I}_{i})\), \(K^{\mathit{II}}_{i}(t)=M^{\mathit{II}}_{i}((t-S^{\mathit{II}}_{i})\wedge C^{\mathit{II}}_{i})\). Conditioning on N I(t) and N II(t), denoting p n =Pr{N I(t)=n}, p m =Pr{N II(t)=m}, and \(\sum_{s}=\sum_{s=0}^{\infty}\), the above computation continues as

where \(K^{I}_{i}(U^{I}_{t})=M^{I}_{i}((t-U^{I}_{i})\wedge C^{I}_{i})\), \(K^{\mathit{II}}_{i}(U^{\mathit{II}}_{t})=M^{\mathit{II}}_{i}((t-U^{\mathit{II}}_{i})\wedge C^{\mathit{II}}_{i})\), \(U^{I}_{1},\dots,U^{I}_{n}\) are i.i.d. random variables defined in (0,t], and similarly \(U^{\mathit{II}}_{1},\dots,U^{\mathit{II}}_{m}\) are also i.i.d random variables. Next, conditioning on \(K^{I}_{i}(U^{I}_{t})\), \(K^{\mathit{II}}_{i}(U^{\mathit{II}}_{t})\) respectively, denoting \(q_{k_{i}}=\Pr\{K^{I}_{i}(U^{I}_{t})=k_{i}\}\) for i=1,2,…,n and \(q_{l_{i}}=\Pr\{K^{\mathit{II}}_{i}(U^{\mathit{II}}_{t})=l_{i}\}\) for i=1,2,…,m, the above computation continues as

Denoting \(\sum_{\Delta}=\sum_{k_{1}}\cdots\sum_{k_{n}}\sum_{l_{1}}\cdots\sum_{l_{m}}\), \(q_{\Delta}=q_{k_{1}}\cdots q_{k_{n}}q_{l_{1}}\cdots q_{l_{m}}\), and \(\Delta'=r\sum^{n}_{i=1}X^{I}_{i}+r\sum^{m}_{i=1}X^{\mathit{II}}_{i}\). Let k=k 1+⋯+k n , l=l 1+⋯+l m , we can write the above as

Since \(I=\sum^{k}_{j=1}Y^{I}_{1j}\) is a sum of finite number of independent random variables with a common regular-tailed distribution, it follows from the closure properties of regular-tailed distribution family that I is still identically regular-tailed distributed; and so are \(\mathit{II}=\sum^{l}_{j=1}Y^{\mathit{II}}_{1j}\). Furthermore, by the same property, the sum I+II also has the same regular-tailed distribution. However, the sum Δ′ is a random variable taking finite value. From the property of the regular-tailed distribution, (A.18) becomes the following as z→∞.

The above result can be written as follows:

Here \(\sum_{k_{1}}k_{1}q_{k_{1}}=E[K^{I}_{1}(U^{I}_{t})],\dots,\sum_{k_{n}}k_{n}q_{k_{n}}=E[K^{I}_{n}(U^{I}_{t})]\), and \(\sum_{l_{1}}l_{1}q_{l_{1}}=E[K^{\mathit{II}}_{1}(U^{\mathit{II}}_{t})],\allowbreak \dots,\sum_{l_{m}}l_{m}q_{l_{m}}=E[K^{\mathit{II}}_{m}(U^{\mathit{II}}_{t})]\).

Now, we can compute the probability Pr{Y(t)>z} in the same way and have

It follows from (A.19) and (A.20) that Lemma A.4 holds. □
Combining the results of Lemmas A.3 and A.4 with (A.19) and (A.20), we have, for a given t<∞,

This completes the proof of Theorem 5. □
Proof of Theorem 6
It is clear that Lemma A.3 is valid. Also, the result of (A.18) still holds under the conditions of Theorem 5. That is, for a given t,

as u→∞. Here the meanings of all symbols are the same as before.
However, using the current conditions, the sums \(I=\sum_{j=1}^{k}Y_{1j}^{I}\) and \(\mathit{II}=\sum_{j=1}^{l}Y_{1j}^{\mathit{II}}\) have regular-tailed distributions with the different indexes α and β, respectively. Since α<β, from the properties of regular-tailed distribution family, we know that I+II must be regular-tailed distributed and have the index α. Then, we repeat a procedure similar to the proof of Lemma A4 and have

and

Hence, the proof of Theorem 6 is completed by combining Lemma A.3, (A.21) and (A.22). □
Rights and permissions
About this article
Cite this article
Bai, JM., Zhang, Z.G. & Li, ZH. Lifetime properties of a cumulative shock model with a cluster structure. Ann Oper Res 212, 21–41 (2014). https://doi.org/10.1007/s10479-012-1255-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-012-1255-6