
Abstract
Spatially explicit harvest scheduling models optimize the layout of harvest treatments to best meet management objectives such as revenue maximization subject to a variety of economic and environmental constraints. A few exceptions aside, the mixed-integer programming core of every exact model in the literature requires one decision variable for every applicable prescription for a management unit. The only alternative to this “brute-force” method has been a network approach that tracks the management pathways of each unit over time via four sets of binary variables. Named after their linear programming-based aspatial predecessors, Models I and II, along with Model III, which has no spatial implementation, each of these models rely on static volume and revenue coefficients that must be calculated pre-optimization. We propose a fundamentally different approach that defines stand volumes and revenues as variables and uses difference equations and Boolean algebra to transition forest units from one planning period to the next. We show via three sets of computational experiments that the new model is a computationally promising alternative to Models I and II.





Similar content being viewed by others

References
Bare, B. B., & Norman, E. (1969). An evaluation of integer programming in forest production scheduling problems (Research Bulletin No. 847). Purdue University Agricultural Experiment Station, 7 pp.
Berck, P. (1976). Natural resources in a competitive economy. Ph.D. Thesis, Department of Economics, Massachusetts Institute of Technology.
Caro, F., Constantino, M., Martins, I., & Weintraub, A. (2003). A 2-opt tabu search procedure for the multiperiod forest harvesting problem with adjacency, greenup, old growth, and even flow constraints. Forest Science, 49(5), 738–751.
Charnes, A., & Cooper, W. W. (1961). Management models and industrial applications of linear programming. New York: Wiley.
Constantino, M., Martins, I., & Borges, J. (2008). A new mixed-integer programming model for harvest scheduling subject to maximum area restrictions. Operations Research, 56(3), 542–551.
Curtis, F. (1962). Linear programming: the management of a forest property. Journal of Forestry, 60(9), 611–616.
Franklin, J., & Forman, R. (1987). Creating landscape patterns by forest cutting: ecological consequences and principles. Landscape Ecology, 1(1), 5–18.
FMOS—Forest Management Optimization Site (2012). University of New Brunswick, Canada. http://ifmlab.for.unb.ca/fmos/datasets/. Retrieved: 6/1/2012.
Garcia, O. P. (1979). Modelling stand development with stochastic differential equations. In D. E. Elliott (Ed.), Forest research institute symposium: Vol. 20. Mensuration systems for forest management planning (pp. 315–334). New Zealand: New Zealand Forest Service.
Goycoolea, M., Murray, A., Barahona, F., Epstein, R., & Weintraub, A. (2005). Harvest scheduling subject to maximum area restrictions: exploring exact approaches. Operations Research, 53(3), 490–500.
Goycoolea, M., Murray, A., Vielma, J. P., & Weintraub, A. (2009). Evaluating approaches for solving the area restriction model in harvest scheduling. Forest Science, 55(2), 149–165.
Gunn, E. A., & Rai, A. K. (1987). Modelling and decomposition for planning long-term forest harvesting in an integrated industry structure. Canadian Journal of Forest Research, 17(12), 1507–1518.
Gunn, E. A., & Richards, E. W. (2005). Solving the adjacency problem with stand-centred constraints. Canadian Journal of Forest Research, 35(4), 832–842.
Hof, J., Bevers, M., & Kent, B. (1997). An optimization approach to area-based forest pest management over time and space. Forest Science, 43(1), 121–128.
Johansson, P. O., & Löfgren, K. G. (1985). The economics of forestry and natural resources. Oxford: Basil Blackwell.
Johnson, K. N., & Scheurman, H. L. (1977). Techniques for prescribing optimal timber harvest and investment under different objectives—discussion and synthesis. Forest Science Monograph, 18.
Kidd, W. Jr., Thompson, E., & Hoepner, P. (1966). Forest regulation by linear programming—a case study. Journal of Forestry, 64(9), 611–613.
Kirby, M. W., Wong, P., Hager, W. A., & Huddleston, M. E. (1980). Guide to the integrated resource planning model. U.S. Department of Agriculture, Management Sciences Staff., Berkeley, CA, 212 pp.
Lockwood, C., & Moore, T. (1993). Harvest scheduling with spatial constraints: a simulated annealing approach. Canadian Journal of Forest Research, 23, 468–478.
Loucks, D. (1964). The development of an optimal program for sustained-yield management. Journal of Forestry, 62(7), 485–490.
McArdle, R. E., Meyer, W. H., & Bruce, D. (1961). The yield of Douglas-fir in the Pacific Northwest (Technical Bulletin No. 201). USDA Forest Service, Washington, DC, 72 pp. (rev.).
McDill, M. (1989). Timber supply in dynamic general equilibrium. Ph.D. Thesis, Department of Forestry, Pennsylvania State University.
McDill, M., Rebain, S., & Braze, J. (2002). Harvest scheduling with area-based adjacency constraints. Forest Science, 48(4), 631–642.
Murray, A. T., Goycoolea, M., & Weintraub, A. (2004). Incorporating average and maximum area restrictions in harvest scheduling models. Canadian Journal of Forest Resources, 34(2), 456–464.
Murray, A. T. (1999). Spatial restrictions in harvest scheduling. Forest Science, 45(1), 45–52.
Nautiyal, J. C., & Pearse, P. H. (1967). Optimizing the conversion to sustained yield—a programming solution. Forest Science, 13(2), 131–139.
O’Hara, A. J., Faaland, B. H., & Bare, B. B. (1989). Spatially constrained timber harvest scheduling. Canadian Journal of Forest Research, 19, 715–724.
Pienaar, L. V., & Turnbull, K. J. (1973). The Chapman-Richards generalization of Von Bertalanffy’s growth model for basal area growth and yield in even-aged stands. Forest Science, 19(1), 2–22.
Richards, E. W., & Gunn, E. A. (2003). Tabu search design for difficult forest management optimization problems. Canadian Journal of Forest Research, 33, 1126–1133.
Snyder, S., & ReVelle, C. (1996). Temporal and spatial harvesting of irregular systems of parcels. Canadian Journal of Forest Research, 26(6), 1079–1088.
Snyder, S., & ReVelle, C. (1997). Dynamic selection of harvests with adjacency restrictions: the SHARe model. Forest Science, 43(2), 213–222.
Timber Mart-South (2008). Warnell School of Forest Resources. University of Georgia, Athens, GA. http://www.timbermart-south.com/. Last accessed: 10/4/2011.
Tóth, S. F., McDill, M. E., Könnyű, N., & George, S. (2013). Testing the use of lazy constraints in solving area-based adjacency formulations in harvest scheduling models. Forest Science. doi:10.5849/forsci.11-040.
Tóth, S. F., McDill, M. E., Könnyű, N., & George, S. (2012). A strengthening procedure for the path formulation of the area-based adjacency problem in harvest scheduling models. Mathematical and Computational Forestry and Natural Resources Sciences, 4(1), 16–38.
United States Congress (1976). National Forest Management Act of 1976. 16 U.S.C. 1600.
Williams, H. P. (1999). Model building in mathematical programming (4th ed.). New York: Wiley, 354 pp.
Acknowledgements
This work was funded by the University of Washington’s Precision Forestry Cooperative and the USDA National Institute of Food and Agriculture (NIFA) under grant number WNZ-1398. The New Zealand data were kindly made available by Geoff Thorp of the Lake Taupo Forest Trust, and Chas Hutton, John Hura and Colin Lawrence of the New Zealand Forest Managers Ltd. We also thank Dr. Pete Bettinger of the University of Georgia’s Warnell School of Forest Resources for providing us with the spatial and the growth and yield data for the Loblolly pine experiment. Lastly, thanks to Drs Bruce Bare, University of Washington, Seattle and Thomas Lynch, Oklahoma State University for their valuable pre-submission reviews.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Benchmark models
We present Model I, the first benchmark model, differently from existing literature in that we use a prescription-based rather than harvest timing-based formulation. The decision variables denote the choice whether a sequence of actions (e.g., harvests) should be applied to a management unit or not. Traditionally, integer versions of Model I have been presented with variables that represented “cut or not cut” decisions for each unit. The more general, prescription-based formulation was needed in our experiments because both Models II and IV allow any number of harvests to be applied to a given stand over a particular planning horizon. Among other things, one consequence of this generalization of Model I is that the prescription variables need to be mapped to harvest timing-based cluster variables for the Cluster Packing formulation to work (see Constraints (A.8)–(A.9)). Finally, our presentation of Model II is also new in that here, an ARM-based extension is used. Snyder and ReVelle’s (1996, 1997) Model II construct was URM-based.
1.1 A.1 Model I
To define the integer version of Johnson and Scheurman’s (1977) Model I, we let S denote the set of management units, t=1,2,…,T the time periods in the planning horizon, and k the minimum rotation age. We note that based on the assumption that harvests can occur only in the midpoints of the planning periods, the number of times a unit can potentially be harvested over the planning horizon is T/k. Model I requires the definition of the set of all possible prescriptions that can be assigned to a management unit: P={(0,…,0),(1,0,…,0),…}, where every prescription p∈P is a vector of length T. The elements of vector p represent the binary decisions of whether the management unit should be harvested in a particular planning period or not. The first element of the vector corresponds to period 1, the second to period 2, and so on. A value of one indicates that a harvest is to occur in the corresponding period, whereas zero indicates that no harvest should occur. Let 0–1 variable x sp represent the decision whether unit s should follow prescription p. If it should, x sp =1, 0 otherwise. Decision variables are created only for those prescriptions that would not lead to premature harvests. In other words, all prescription variables with first harvests that occur before the unit reaches its minimum rotation age are excluded from the model during pre-processing.
Further, for management unit s∈S, we let a s denote the area, e s the regeneration cost, and \(v_{\mathit{sp}}^{t}\) the volume per unit area in period t given prescription p. We use h t as an accounting variable for the volume harvested from the entire forest in period t, we use c for unit volume timber price, i for the real interest rate, and r sp for the revenues associated with harvesting unit s according to prescription p. Finally, bounds f min and f max denote the allowable percent decrease and increase in harvest volume in consecutive planning periods. Such bounds are often used by practitioners to promote some level of operational sustainability. Then,






defines the spatial version of Model I. The objective function (A.1) maximizes the net discounted timber revenues associated with the entire forest across the planning horizon of T periods with the revenue coefficients being
Constraint (A.2) ensures that each unit is assigned exactly one prescription. Constraint (A.3) calculates the harvest volume in each time period and Constraints (A.4) and (A.5) ensure that the harvest volume in adjacent planning periods does not fluctuate by more than a lower and an upper bound, f min and f max, respectively. Finally, Constraint (A.6) defines the decision variables as binary.
Model I can easily incorporate spatial constraints such as maximum or average harvest opening size restrictions. All of the three existing ARMs, McDill et al.’s (2002) Path, Goycoolea et al.’s (2005) Cluster Packing and Constantino et al.’s (2008) Bucket formulation, were introduced in the literature based on the Model I construct. Goycoolea et al.’s (2005) Cluster Packing is the only ARM, however, that can handle maximum average clear-cut size restrictions (Murray et al. 2004), which are often present in forest regulations. Cluster Packing requires an a priori enumeration of all contiguous clusters of management units whose combined area does not exceed the maximum allowable clear-cut size. Formally, a set of management units s∈θ that forms a connected sub-graph of graph G(S,E), where E denotes the edges representing the adjacency among the units (S), and for which inequality ∑ s∈θ a s ≤A max (A max = the maximum harvest opening size) holds, is called a feasible cluster. Let Θ denote the set of all feasible clusters that arise from a given problem instance. To incorporate Goycoolea et al.’s (2005) Cluster Packing approach in Model I, the management unit-based prescription variables x sp ∈{0,1} must be mapped to cluster variables to account for the feasible clusters. Let u θt ∈{0,1} denote the decision whether all management units in cluster θ should be cut in period t:
where P θt is the set of all prescriptions applicable to cluster θ that involve a harvest in period t and A θ is the set of management units that are adjacent to cluster θ. Constraint (A.8) allows, while Constraint (A.9) forces cluster θ to be “declared” cut in period t if all the units in the cluster, but none adjacent to it, are assigned prescriptions that involve a harvest in period t. To avoid double-counting the harvested areas, and to ensure that the maximum harvest opening size is never exceeded in any of the solutions, one constraint needs to written for each maximal clique of management units in each planning period. A set of mutually adjacent management units forms a maximal clique if no other unit exists that is adjacent to every member of the clique. Let K denote the set of all maximal cliques that arise from a problem with κ being one such clique. To prevent maximum harvest opening size violations, it is necessary that
where Θ κ is the set of feasible clusters that contain at least one management unit that is also a member of maximal clique κ. Constraint (A.10) requires that only one feasible cluster containing one or more units in clique κ is assigned to be clear-cut in period t. This precludes harvest arrangements where adjacent units are cut as parts of two or more feasible clusters of units whose combined area exceeds the maximum harvest opening size. Constraint (A.10), which is the multi-harvest version of the original Cluster Packing adjacency Constraint (Goycoolea et al. 2005), also prevents a unit from being part of multiple clusters in a given period. Finally, to enforce that the average harvest opening size over the entire planning horizon does not exceed \(\bar{A}_{\max }\), we add the following forest-wide inequality (Murray et al. 2004):
In Constraint (A.11), a θ is the area of cluster θ and \(\bar{A}_{\max }\) is the maximum allowable average clear-cut size.
If only maximum harvest opening size restrictions are present, McDill et al.’s (2002) Path Formulation can also be used by replacing (A.8)–(A.11) with the following set of adjacency constraints:
where P st is the set of all prescriptions applicable to unit s that involve a harvest in period t. In the computational experiments, (A.1)–(A.7) were used for the Radiata problem, (A.1)–(A.11) for the Loblolly, and (A.1)–(A.7) and (A.12) for El Dorado.
1.2 A.2 Model II
To give a formal definition of Model II, we let variable sets b st ,ℓ st ∈{0,1} ∀s,t denote the decision whether unit s should be cut in period t the first time and whether it should be cut in period t the last time, respectively. If unit s is to be cut the first time in period t, then b st =1, 0 otherwise. If unit s is to be cut the last time in period t, then ℓ st =1, 0 otherwise. Further, we let variable set g s,t′,t ∈{0,1} ∀s,t denote the decision whether unit s should be harvested in period t after it had last been cut in period t′. If it is, then g s,t′,t =1, 0 otherwise. Lastly, we let n s ∈{0,1} ∀s,t represent the “do-nothing” scenario. If unit s is not to be cut during the planning horizon, then n s =1, 0 otherwise. Strictly speaking, variable set n s ∈{0,1} is not needed for Model II except for the convenience of keeping track of uncut forest tracts.
As in Model I, we seek to maximize net timber revenues over the planning horizon subject to logical constraints that allow exactly one first harvest or no harvest of a unit, and harvest volume flow Constraints (A.16)–(A.18) that are analogous to inequalities (A.3)–(A.5) in Model I. We calculate the revenue coefficient associated with the first harvest of unit s in period t using relation \(r_{\mathit{st}}^{b} = ( c \cdot a_{s} \cdot v_{\mathit{st}}^{b} - e_{s} ) \cdot( 1 + i )^{ - t}\), where \(v_{\mathit{st}}^{b}\) is the harvest volume of unit s in period t given that this is the first time unit s is cut. Similarly, we use formula \(r_{s,t',t}^{g} = ( c \cdot a_{s} \cdot v_{s,t',t}^{g} - e_{s} ) \cdot( 1 + i )^{ - t}\) to calculate the revenues associated with cutting unit s in period t after having cut it already in period t′. Parameter \(v_{s,t',t}^{g}\) represents the unit area volume associated with the harvest of unit s in period t given that the previous harvest occurred in period t′. Then, the following function and set of inequalities define Model II:









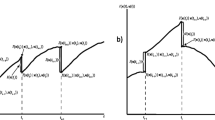
where Identity (A.15) is a “network flow” constraint that ensures whenever a management unit is cut in a particular period, whether it is the first, second or an intermediate harvest, there must be another variable that either declares this harvest to be the last for that unit or it forces it to be cut again during the planning horizon. In other words, this constraint forces each management unit to have a sound prescription plan with no discrepancies. Along with the logical Constraints (A.14), the flow constraints create a network representation of the harvest scheduling problem with nodes representing the starting (source), the ending (sink) and the intermediate states of the units (Fig. 1). Whatever harvest decision takes the unit to a given harvest-period state, there has to be another decision that moves it along to another state. This decision is either a declaration that this harvest was the unit’s last, or the unit could be cut again in a subsequent period. Finally, Constraints (A.19)–(A.21) define the four sets of decision variables as binary.
Model II is also compatible with all the three exact ARMs: McDill et al.’s (2002) Path, Goycoolea et al.’s (2005) Cluster Packing and Constantino et al.’s (2008) Bucket Formulation. Path constraints can be added as:
Objective (A.13) and Constraints (A.14)–(A.22) were used to model the El Dorado problem with Model II in the computational experiment.
To incorporate Goycoolea et al.’s (2005) Cluster Packing Formulation, the decision variables in Model II are redefined to handle Cluster Packing. Variable sets b st , ℓ st , and g s,t′,t are replaced with b θt , ℓ θt , and g θ,t′,t to represent the decision whether cluster θ should be cut in period t first, whether it should be cut in period t last, and whether it should be cut in period t after it had already been cut in period t′, respectively. Variable b θt takes the value of one if cluster θ is to be cut for the first time in period t,0 otherwise. Variable ℓ θt takes the value of one if cluster θ is to be cut for the last time in period t, 0 otherwise. Lastly, g θ,t′,t =1 if cluster θ is to be cut in period t after it had been cut in period t′, 0 otherwise. To incorporate harvest opening size restrictions using Goycoolea et al.’s (2005) model, objective function (A.13) and Constraints (A.14)–(A.21) remain the same except that all decision variables are replaced with the cluster variables as described above. To account for the logical condition that a given management unit can only be assigned to at most one feasible cluster that is cut in a particular period for the first time, we replace the logical constraint set (A.14) with
Variable n s is added to the sum of cluster assignments to account for the option of not cutting unit s during the planning horizon. We also replace the network flow constraints to allow a unit to be assigned to different clusters in each period:
To prevent adjacent management units from being assigned to multiple clusters that are cut at the same time, we add inequality set
Constraints (A.25) are analogous to Constraints (A.10) in Model I; they ensure that maximum harvest opening size restrictions are never violated. Finally, to enforce the forest-wide maximum allowable average harvest opening size restriction (\(\overline{A}_{\max }\)), we require that:
Appendix B: Goal programming to fit Model IV
We let ω a denote the unit area volume of a management unit at age a (in periods) available from the original data, and we let \(\omega_{a}^{*}\) denote the volume at age a coming from the logistic curve (1). For simplicity, we assume that the growth of each management unit is the same: volumes ω a , accounting variables \(\omega_{a}^{*}\) and the five parameters that are optimized for best fit have no s sub- or superscripts. This, of course, does not mean that Function (1) cannot be fitted for each management unit individually.
The objective of the GP, Function (A.1), minimizes the sum of absolute deviations, δ a , between the fitted, \(\omega_{a}^{*}\), and the original data, ω a :













Constraints (B.2) and (B.3) calculate the absolute deviation, δ a between \(\omega_{a}^{*}\) and ω a with the help of objective function (B.1), which maximizes the sum of the deviations. Constraint (B.4) sets the value of the fitted \(\omega_{1}^{*}\) to be equal to ϕ min. Constraints (B.5) and (B.6) work together to determine if the fitted volume at a particular age is above or below the inflection point β. If the volume is strictly above the inflection point, then y a =1. Indicator y a is zero otherwise. Note that the goal program will not allow the inflection point to be equal to the volume in any particular period, unless using the difference equation for the taper (B.9)–(B.10) vs. the exponential segment of the curve (B.7)–(B.8) does not make any difference in the objective function value. Recall that in the goal program, both the inflection point and the fitted volumes are variables. Constraints (B.5) through (B.10) establish the relationship between the five function parameters (ϕ min, ϕ max, γ exp, γ taper and β) that are to be optimized and the fitted volumes: \(\omega_{a}^{*}\ \forall a \in A\). Along with inequalities (B.5)–(B.6), Constraints (B.7)–(B.10) capture Function (1). Lastly, Constraints, (B.11)–(B.13) define the domains of the variables.
While GP (B.1)–(B.13) is a quadratically constrained, non-convex,Footnote 1 and non-smoothFootnote 2 optimization problem, it is trivial to solve since it has only five decision variables (ϕ min, ϕ max, γ exp, γ taper and β) and only |A| accounting variables for the fitted volumes (\(\omega_{a}^{*}\)), the deviations (δ a ) and the indicators y a , each. Moreover, there is only one pair of goal constraints per data point, (B.2)–(B.3), and only a few extra constraints to account for the relationship between the volumes in consecutive age classes (B.4)–(B.10). GP (B.1)–(B.13) can be converted to a smooth optimization problem by optimizing for each binary combination of y a ’s and selecting the combination that leads to the smallest total deviation. In this study, we used MS Excel Solver to fit Function (1).
Appendix C: Modeling intermediate treatments with Model IV
In this appendix, we discuss how Model IV can incorporate intermediate treatment decisions that are hard to capture in Models I and II parsimoniously: Should a management unit be thinned in a particular planning period with a given intensity or not? Should fertilization be applied to increase site productivity or should the trees be pruned? Thinning reduces the volume of the unit at the time of treatment and puts it on a steeper growth trajectory for merchantable timber. Thinings are applied in an attempt to maximize revenues or to improve forest health, or both. In addition to stimulating growth, fertilization can also increase site productivity, and pruning can change the quality of timber products.
The potential timings of treatments introduce additional prescriptions that are applicable to a management unit leading to an explosion of 0–1 variables in Model I. While the explosion is less dramatic in Model II, it is still an exponential function of the number of periods where intermediate treatments can occur. This is because additional sets of “first-”, “last-” and “intermediate harvest” variables are needed to link harvest decisions to intermediate treatments in prior or subsequent periods. If, in addition to the timing, the intensity of the treatments is also variable, then the combinatorial explosion is even more significant.
In Model IV, the number of extra decision variables that are needed to capture intermediate treatments increases only linearly as a function of the number of planning periods. To illustrate how Model IV can keep model size small, we consider a binary thinning decision τ st in management unit s in period t with a preset thinning intensity of α∈[0,1]. Let variable τ st take the value of one if unit s is to be thinned in period t, 0 otherwise. We assume that the expected post-thinning growth rates of the unit are known: \(\gamma_{\exp '}^{s}\) in the exponential and \(\gamma_{\mathrm{taper}'}^{s}\) in the taper section with an inflection point of β s. First, Constraints (6)–(9) in Model IV are modified so that they would inactivate should thinning occur in period t:


If τ st =1, the value of v s,t+1 is unrestricted in inequalities (C.1)–(C.4) regardless of the value of indicator y st because \(v_{s,t + 1} \le\phi_{\max }^{s}\) and because \(0 \le\gamma_{\mathrm{taper}}^{s} \le 1\). If τ st =0, Constraints (C.1)–(C.4) work the same way as Constraints (6)–(9). To define the post-thinning growth of the units, we add:


These constraints are structurally similar to (6)–(9) or (C.1)–(C.4). The only difference is in the post-thinning growth rates. If τ st =1, it is the value of y st that determines whether the v s,t+1 is going to be equal to the right-hand side of inequality (C.5)–(C.6) or (C.7)–(C.8). Note that the volume in period t is adjusted based on the intensity of thinning in period t:α. If τ st =0, the value of v s,t+1 becomes unrestricted regardless of the value of y st . In this case, Constraints (C.1)–(C.4) become active and work the same way as the original Constraints (6)–(9).
The number of decision variables per unit that need to be introduced in Model IV to account for thinning decisions with set intensities is equal to the number of planning periods that are eligible for thinning. The number of extra constraints, Constraints (C.5)–(C.8), is four times the number of eligible periods. If the range of volumes that correspond to planning periods eligible for thinning falls exclusively below or above the inflection point, then either (C.5)–(C.6) or (C.7)–(C.8) may be dropped. Lastly, alternative thinning intensities, as well as fertilization and pruning decisions may be modeled the same way as thinning decisions. For fertilization and pruning, coefficient α will be one since no merchantable volume is removed from the unit. The post-treatment growth rates in volume (for fertilization) or revenues (for pruning) will drive the transition of the units from one period to the next in accordance with Constraints (C.5)–(C.8).
Rights and permissions
About this article
Cite this article
St. John, R., Tóth, S.F. Spatially explicit forest harvest scheduling with difference equations. Ann Oper Res 232, 235–257 (2015). https://doi.org/10.1007/s10479-012-1301-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-012-1301-4