
Abstract
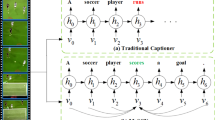
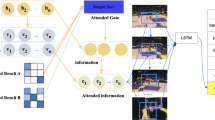
In the field of computer vision, it is a challenging task to generate natural language captions from videos as input. To deal with this task, videos are usually regarded as feature sequences and input into Long-Short Term Memory (LSTM) to generate natural language. To get richer and more detailed video content representation, a Multimodal Interaction Video Captioning Network based on Semantic Association Graph (MIVCN) is developed towards this task. This network consists of two modules: Semantic association Graph Module (SAGM) and Multimodal Attention Constraint Module (MACM). Firstly, owing to lack of the semantic interdependence, existing methods often produce illogical sentence structures. Therefore, we propose a SAGM based on information association, which enables network to strengthen the connection between logically related languages and alienate the relations between logically unrelated languages. Secondly, features of each modality need to pay attention to different information among them, and the captured multimodal features are great informative and redundant. Based on the discovery, we propose a MACM based on LSTM, which can capture complementary visual features and filter redundant visual features. The MACM is applied to integrate multimodal features into LSTM, and make network to screen and focus on informative features. Through the association of semantic attributes and the interaction of multimodal features, the semantically contextual interdependent and visually complementary information can be captured by this network, and the informative representation in videos also can be better used for generating captioning. The proposed MIVCN realizes the best caption generation performance on MSVD: 56.8%, 36.4%, and 79.1% on BLEU@4, METEOR, and ROUGE-L evaluation metrics, respectively. Superior results are also reported on MSR-VTT about BLEU@4, METEOR, and ROUGE-L compared to state-of-the-art methods.







Similar content being viewed by others

References
Viola P, Jones M (2001) Rapid object detection using a boosted cascade of simple features. In: 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR, Kauai, HI, USA (Vol. 1, pp. I-I)
Lowe DG (1999) Object recognition from local scale-invariant features. In: 1999 IEEE International Conference on Computer Vision. Kerkyra, Greece, pp 1150–1157 vol.2
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), San Diego, CA, USA, pp 886-893 vol. 1
Langkilde-geary I, Knight K (2002) Halogen statistical sentence generator. In: Proceedings of the ACL-02 Demonstrations Session. Philadelphia. pp 102-103
Pollard CJ, Sag IA (1994) Head-driven phrase structure grammar. University of Chicago Press
Ehud R, Robert D (2006) Building natural language generation systems (studies in natural language processing). Cambridge University Press
Das P, Xu C, Doell RF, Corso JJ (2013) A thousand frames in just a few words: lingual description of videos through latent topics and sparse object stitching. In:2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, pp 2634-2641
Pan Y, Yao T, Li T, Mei T (2017) Video captioning with transferred semantic attributes. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition. CVPR, Honolulu, HI, pp. 984–992
Hemalatha M, Sekhar CC (2020) Domain-specific semantics guided approach to video captioning. In:2020 IEEE Winter Conference on Applications of Computer Vision. WACV, Snowmass Village, CO, USA, pp 1576-1585
Ryu H, et al. (2021) Semantic grouping network for video captioning. In: proceedings of the AAAI Conference on Artificial Intelligence. Columbia, Canada. arXiv preprint arXiv:2102.00831
Yang B, et al. (2021) Non-autoregressive coarse-to-fine video captioning. In: Proceedings of the AAAI Conference on Artificial Intelligence. Columbia, Canada. arXiv preprint arXiv:1911.12018
Yao L et al (2015) Describing videos by exploiting temporal structure. In: 2015 IEEE international conference on computer vision. ICCV, Santiago, pp 4507–4515
Venugopalan S, et al. (2014) Translating videos to natural language using deep recurrent neural networks. In: Human Language Technologies: The 2015 Annual Conference of the North American Chapter of the ACL. Denver, Colorado, arXiv preprint arXiv:1412.4729
Venugopalan S, Rohrbach M, Donahue J, Mooney R, Darrell T, Saenko K (2015) Sequence to Sequence -- Video to Text. In: 2015 IEEE international conference on computer vision. ICCV, Santiago, pp 4534–4542
Yu H, Wang J, Huang Z, Yang Y, Xu W (2016) Video paragraph captioning using hierarchical recurrent neural networks. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition. CVPR, Las Vegas, NV, pp. 4584–4593
Liang Y, He F, Zeng X. (2020) 3D mesh simplification with feature preservation based on whale optimization algorithm and differential evolution[J]. Integrated computer-aided engineering, (preprint): 1-19
Chen Y, He F, Li H, Zhang D, Wu Y (2020) A full migration BBO algorithm with enhanced population quality bounds for multimodal biomedical image registration[J]. Appl Soft Comput 93:106335
Quan Q, He F, Li H (2021) A multi-phase blending method with incremental intensity for training detection networks[J]. Vis Comput 37(2):245–259
Wang B, Ma L, Zhang W, Liu W (2018) Reconstruction Network for Video Captioning. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. CVPR, Salt Lake City, UT, pp. 7622–7631
Wang B et al (2019) Controllable video captioning with pos sequence guidance based on gated fusion network. In: 2019 IEEE/CVF International Conference on Computer Vision. Seoul, South Korea, pp 2641–2650
Aafaq N, Akhtar N, Liu W, Gilani SZ, Mian A (2019) Spatio-temporal dynamics and semantic attribute enriched visual encoding for video captioning. In:2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. CVPR, Long Beach, CA, USA, pp 12479-12488
Pan B, et al. (2020) Spatio-temporal graph for video captioning with knowledge distillation. In:2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. CVPR, Seattle, WA, USA, pp 10867-10876
Gan Z, et al. (2017) Semantic compositional networks for visual captioning. In:2017 IEEE Conference on Computer Vision and Pattern Recognition. CVPR, Honolulu, HI, pp 1141-1150
Gao L, Guo Z, Zhang H, Xu X, Shen HT (2017) Video captioning with attention-based LSTM and semantic consistency. IEEE Transactions on Multimedia 19(9):2045–2055
Gao L, Wang X, Song J, Liu Y (2020) Fused GRU with semantic-temporal attention for video captioning. Neurocomputing 395:222–228
Liu S, Ren Z, Yuan J (2019) SibNet: sibling convolutional encoder for video captioning. IEEE Transactions on Pattern Analysis and Machine Intelligence pp:1–1
Yao L, Mao CS, Lo Y (2019) Graph convolutional networks for text classification. In: Proceedings of the AAAI conference on artificial intelligence. AAAI, Honolulu, Hawaii, pp 7370–7377
Li H, He F, Chen Y, Pan Y (2021) MLFS-CCDE: multi-objective large-scale feature selection by cooperative coevolutionary differential evolution[J]. Memetic Computing 13(1):1–18
You Q, Jin H, Wang Z, Fang C, Luo J (2016) Image captioning with semantic attention. In: 2016 IEEE conference on computer vision and pattern recognition. CVPR, Las Vegas, NV, pp. 4651–4659
Kiros R, Salakhutdinov R, Zemel RS (2014) Unifying visual-semantic embeddings with multimodal neural language models. In: NIPS 2014 deep learning workshop. Montreal, Canada. arXiv preprint arXiv:1411.2539
Karpathy A, Fei-Fei L (2017) Deep visual-semantic alignments for generating image descriptions. IEEE Trans Pattern Anal Mach Intell 39(4):664–676
Mikolov T, et al. (2013) Efficient estimation of word representations in vector space. Computer science. arXiv preprint arXiv:1301.3781
Xie S, Girshick R, Dollár P, Tu Z, He K (2017) Aggregated Residual Transformations for Deep Neural Networks. In: 2017 IEEE conference on computer vision and pattern recognition. CVPR, Honolulu, HI, pp. 5987–5995
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L (2015) Imagenet large scale visual recognition challenge. Int J Comput Vis 115:211–252
Zolfaghari M, Singh K, Brox T (2018) Eco: efficient convolutional network for online video understanding. Proceedings of the European conference on computer vision. ECCV, In, pp 695–712
Kay W, et al. (2017) The kinetics human action video dataset. In: computer vision and pattern recognition. Hawaii, USA. arXiv preprint arXiv:1705.06950
Ren S, He K, Girshick R, Sun J (2017) Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39(6):1137–1149
Kingma DA (2014) A method for stochastic optimization. Computer Science. arXiv preprint arXiv:1412.6980
Freitag M, Al-Onaizan Y (2017) Beam search strategies for neural machine translation. In: Proceedings of the First Workshop on Neural Machine Translation. arXiv preprint arXiv:1702.01806
Papineni K, Roukos R, Ward T, Zhu WJ (2002) BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the Annual Meeting on Association for Computational Linguistics. ACL, pp. 311–318
Crouse JR, Raichlen JS, Riley WA, Evans GW, Palmer MK, O’Leary DH, Grobbee DE, Bots ML, METEOR Study Group, et al. (2007) METEOR Study Group, et al. 2007. Effect of rosuvastatin on progression of carotid intima-media thickness in low-risk individuals with subclinical atherosclerosis: the METEOR trial. JAMA The Journal of the American Medical Association 297(12):1344–1353
Lin CY (2004) Rouge: a package for automatic evaluation of summaries. In: Association for Computational Linguistics. Barcelona, Spain, pp 74–81
Vedantam R, Zitnick CL, Parikh D (2015) CIDEr: Consensus-based image description evaluation. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition. CVPR, Boston, MA, pp. 4566–4575
Yao L, et al. (2015) Describing videos by exploiting temporal structure. In: 2015 IEEE International Conference on Computer Vision. ICCV, Santiago, pp. 4507–4515
Pan Y, Mei T, Yao T, Li H, Rui Y (2016) Jointly modeling embedding and translation to bridge video and language. In:2016 IEEE conference on computer vision and pattern recognition. CVPR, Las Vegas, NV, pp 4594-4602
Pan P, Xu Z, Yang Y, Wu F, Zhuang Y (2016) Hierarchical Recurrent Neural Encoder for Video Representation with Application to Captioning. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition. CVPR, Las Vegas, NV, pp. 1029–1038
Zhu L, Xu Z, Yang Y (2017) Bidirectional multirate reconstruction for temporal modeling in videos. In: 2017 IEEE conference on computer vision and pattern recognition. CVPR, Honolulu, HI, pp. 1339–1348
Venugopalan S , Xu H , Donahue J , et al. (2014) Translating videos to natural language using deep recurrent neural networks. North American chapter of the Association for Computational Linguistics (NAACL) Baltimore, Maryland, USA arXiv preprint arXiv:1412.4729
Sun L, Li B, Yuan C, Zha Z, Hu W (2019) Multimodal semantic attention network for video captioning. In: 2019 IEEE International Conference on Multimedia and Expo. ICME, Shanghai, China, pp 1300–1305
Acknowledgements
This work was supported in part by the Key-Area Research and Development Program of Guangdong Province under Grant 2018B010109007 and 2019B010153002, the National Natural Science Foundation of China under Grant 62002071 and 61903091, the Science and technology projects of Guangzhou under Grant 202007040006 and the Guangdong Provincial Key Laboratory of Cyber-Physical System under Grant 2020B1212060069 and Guangdong Basic and Applied Basic Research Foundation under Grant 2020A1515010801.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, Y., Huang, G., Yuming, L. et al. MIVCN: Multimodal interaction video captioning network based on semantic association graph. Appl Intell 52, 5241–5260 (2022). https://doi.org/10.1007/s10489-021-02612-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-021-02612-y