
Abstract
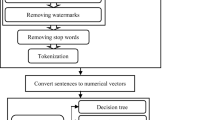
Big data and its related technologies have become active areas of research recently. There is a huge amount of data generated every minute and second that includes unstructured data which is the topic of interest for researchers now a days. A lot of research work is currently going on in the areas of text analytics and text preprocessing. In this paper, we have studied the impact of different preprocessing steps on the accuracy of three machine learning algorithms for sentiment analysis. We applied different text preprocessing techniques and studied their impact on accuracy for sentiment classification using three well-known machine learning classifiers including Naïve Bayes (NB), maximum entropy (MaxE), and support vector machines (SVM). We calculated accuracy of the three machine learning algorithms before and after applying the preprocessing steps. Results proved that the accuracy of NB algorithm was significantly improved after applying the preprocessing steps. Slight improvement in accuracy of SVM algorithm was seen after applying the preprocessing steps. Interestingly, in case of MaxE algorithm, no improvement in accuracy was seen. Our work is a comparative study, and our results proved that in case of NB algorithm, actuary was again significantly high than any other machine learning algorithm after applying the preprocessing steps; followed by MaxE and SVM algorithms. This research work proves that text preprocessing impacts the accuracy of machine learning algorithms. It further concludes that in case of NB algorithm, accuracy has significantly improved after applying text preprocessing steps.





Similar content being viewed by others

References
Asghar MZ, Khan A, Ahmad S, Qasim M, Khan A (2017a) Lexicon-enhanced sentiment analysis framework using rule-based classification scheme. PLoS ONE 12:1–23
Asghar MZ, Khan A, Bibi A, Kundi FM, Ahmad H (2017b) Sentence-level emotion detection framework using rule-based classification. Cogn Comput 9(6):868–894
Baradad VP, Mugabushaka A (2015) Corpus specific stop words to improve the textual analysis in scientometrics. In: International Conference on Science in Information, pp 999–1005
Bhavitha BK, Rodrigues AP, Chiplunkar NN (2017) Comparative study of machine learning techniques in sentimental analysis. In: Proceedings of International Conference Inventory Communication Computing Technology ICICCT 2017, No. Icicct, pp 216–221
Chen J, Huang H, Tian S, Qu Y (2009) Expert systems with applications feature selection for text classification with Naïve Bayes. Expert Syst Appl 36(3):5432–5435
Clark A (2003) Pre-processing very noisy text. In: Proceeding of Work Shallow Process Large Corpora, p 11
Das O, Balabantaray RC (2014) Sentiment analysis of movie reviews using POS tags and term frequencies. Int J Ldots 96(25):36–41
Go A, Bhayani R, Huang L (2009) Twitter sentiment classification using distant supervision. Processing 150(12):1–6
Khan A, Asghar MZ, Ahmad H, Kundi FM, Ismail S (2017) A rule-based sentiment classification framework for health reviews on mobile social media. J Med Imaging Health Inf 7(6):1445–1453
Lovins JB (1968) Development of a stemming algorithm. Mech Transl Comput Linguist 11:22–31
Manek AS, Shenoy PD, Mohan MC, Venugopal KR (2017) Aspect term extraction for sentiment analysis in large movie reviews using Gini Index feature selection method and SVM classifier. World Wide Web 20(2):135–154
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. Arxiv, pp 1–12
Minanovic A, Gabelica H, Krstic Z (2014) Big data and sentiment analysis using KNIME: online reviews vs. social media. In: 2014 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), pp 1464–1468
Mubarok MS, Adiwijaya, Aldhi MD (2017) Aspect-based sentiment analysis to review products using Naïve Bayes. In: AIP Conference Proceedings, vol. 020060, p 020060
Nigam K, Lafferty J, Mccallum A (1999) Using maximum entropy for text classification. In: IJCAI-99 workshop on machine learning for information filtering, pp 61–67
Pak A, Paroubek P (2010) Twitter as a corpus for sentiment analysis and opinion mining. In: Proceedings of the Seventh conference on International Language Resources and Evaluation, pp 1320–1326
Riloff E, Qadir A, Surve P, Silva LD, Gilbert N, Huang R (2013) Sarcasm as contrast between a positive sentiment and negative situation. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, No. Emnlp
Rong X (2014) word2vec parameter learning explained continuous bag-of-word model, pp 1–21
Tong S, Koller D (2001) Support vector machine active learning with applications to text classification. J Mach Learn Res 2:45–66
Xie X, Ge S, Hu F, Xie M, Jiang N (2017) An improved algorithm for sentiment analysis based on maximum entropy. Soft Comput. https://doi.org/10.1007/s00500-017-2904-0
Yadav MP, Pandya D (2017) SentiReview: sentiment analysis based on text and emoticons. In: International Conference Innovation Mechanical Industry Application ICIMIA 2017 SentiReview, no. Icimia, pp 467–472
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Alam, S., Yao, N. The impact of preprocessing steps on the accuracy of machine learning algorithms in sentiment analysis. Comput Math Organ Theory 25, 319–335 (2019). https://doi.org/10.1007/s10588-018-9266-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10588-018-9266-8