
Abstract
Effective crisis management has long relied on both the formal and informal response communities. Social media platforms such as Twitter increase the participation of the informal response community in crisis response. Yet, challenges remain in realizing the formal and informal response communities as a cooperative work system. We demonstrate a supportive technology that recognizes the existing capabilities of the informal response community to identify needs (seeker behavior) and provide resources (supplier behavior), using their own terminology. To facilitate awareness and the articulation of work in the formal response community, we present a technology that can bridge the differences in terminology and understanding of the task between the formal and informal response communities. This technology includes our previous work using domain-independent features of conversation to identify indications of coordination within the informal response community. In addition, it includes a domain-dependent analysis of message content (drawing from the ontology of the formal response community and patterns of language usage concerning the transfer of property) to annotate social media messages. The resulting repository of annotated messages is accessible through our social media analysis tool, Twitris. It allows recipients in the formal response community to sort on resource needs and availability along various dimensions including geography and time. Thus, computation indexes the original social media content and enables complex querying to identify contents, players, and locations. Evaluation of the computed annotations for seeker-supplier behavior with human judgment shows fair to moderate agreement. In addition to the potential benefits to the formal emergency response community regarding awareness of the observations and activities of the informal response community, the analysis serves as a point of reference for evaluating more computationally intensive efforts and characterizing the patterns of language behavior during a crisis.
Similar content being viewed by others


1 Introduction
Reliance on both the formal (professional) and informal (citizen-based) response communities is a well-recognized requirement for effective crisis management (Palen et al. 2010; Purohit et al. 2014). Social media potentially amplifies the influence of the informal response community, both by expanding the geographic region that participates in emergency response from onsite to remote, and by extensively distributing information and requests. Yet despite a seemingly viable role for citizens in emergency response, and recent initiatives1 by the formal response community, such as the U.S. Federal Emergency Management Agency (FEMA), command and control models from the formal response organizations do not easily accommodate the social media that the informal response community has so readily adopted (Palen and Liu 2007; Starbird and Palen 2010).
The CSCW literature clarifies the challenges of cooperative work in general, and allows us to reflect on the potential roles and responsibilities of the formal and informal response communities in cooperative crisis response. People engage in cooperative work when they are mutually dependent in their work, (e.g., regarding decision making and task sequencing, etc.) in order to complete the work (Schmidt and Liam 1992). Cooperating workers must articulate (divide, allocate, coordinate, schedule, mesh, interrelate) their distributed activities. Dividing the work, often between personnel units with specialized skills, distributes task interdependencies among those units (Malone and Crowston 1990). One unit’s effort to ameliorate the situation inevitably changes it, and each unit must track these intentional changes. In established organizations, predefined agreement on roles and responsibilities facilitates tracking and provides the shared understanding essential to cooperative work (Isaacs and Clark 1987; Clark & Brennan, 1991). But the decomposition of a complex problem can never fully avoid unanticipated interaction (Simon 1962). As a result, members of a cooperative system must be able to monitor the conduct of the interactive working parts (Heath and Paul 1992). That is, each unit requires information in order to maintain mutual awareness of activity that affects the others (Schmidt and Liam 1992). Personnel who are co-located talk out loud to render their activities visible to other members of the cooperative system (Heath and Paul 1992). But when cooperative work occurs in a dynamic and distributed environment, unanticipated changes place further demand on maintaining awareness.
In the remaining subsections of this introduction we focus on the inherent articulation and awareness challenges in the formal crisis response organizations and identify the additional complications associated with the inclusion of onsite or remotely-located informal response communities, whose roles are not established by preceding agreement and who do not understand the complexities of the formal response system. We then suggest that an effective blend of the formal and the informal response communities hinges on exploiting the latter’s capabilities for observing, acting and recording without expecting it to possess knowledge of the workings of the former. We identify computational technology for social media traffic, to provide a bridge between the informal and formal response communities that facilitates cooperation regarding both articulation and awareness. This technology exploits the language patterns associated with resource seekers and resource suppliers in social media traffic, aided by a domain ontology driven by the formal response community. The approach allows us to partition social media content from the informal response community into classes that are meaningful according to the framework of the formal response community.
1.1 The articulation challenge in the formal response community
Cooperation within the formal response community is often reliant on a military-inspired notion of hierarchical decomposition and control (Dynes 1983). Established roles and responsibilities, such as those identified in the U.S. FEMA handbook (FEMA 2009), attempt to decompose the domain into independent tasks (Quarantelli 1988). Decision makers within a formal organization evaluate reports of needs to distribute resources. One side effect of this policy is that formal organizations become a fixed bottleneck in resource distribution, creating limitations in responsiveness.
Some of the constraints that govern articulation are potentially idiosyncratic and/or local (Flach et al. 2013). For example, concern for disease and pestilence places restrictions on the clothing, bedding, and food that is acceptable for distribution. People with certain medical needs may not be accepted at public shelters. Citizens may not be able to receive asthma treatments from emergency medical technicians, who require a special waiver from local regulations on their interventions. In our local community, citizens should call the power company for downed power lines, rather than the fire department, unless the lines are active. In short, the formal crisis response system is sociotechnical, reflecting both cultural assumptions and constraints associated with the use of technology that reflect a work practice (Lave and Wenger 1991) grounded in technical knowledge, legal requirements, experience, and convention (Livingston 1987). Even the formal system finds it difficult to grapple with these constraints. Given this complexity, we cannot require general citizens to understand the formal response system in order to contribute. Nevertheless, in the absence of this understanding, the well-intentioned efforts of the informal response community have clear potential to distract and even disrupt the formal response community. For example, volunteers can overwhelm the disaster site with unneeded supplies that place additional demands on local processing (Dynes and Quarantelli 1970). During the response to Hurricane Sandy, The U.S.’s National Public Radio reported that unsolicited resources effectively created a second disaster for the formal response community (Fessler 2013).
1.2 The awareness challenge in the formal response community
General challenges to awareness within and between the formally established organizations (Quarantelli 1988) contribute to puzzling oversights such as the apparently available public school buses that were never deployed for evacuation during Hurricane Katrina (Myers 2005). Communication to build mutual awareness suffers for a variety of reasons. The numerous stakeholders (e.g., civilian, military, and medical entities) may not benefit from co-location, requiring other forms of communication in addition to talking-out-loud. A damaged communication infra-structure may further compromise communication. Differences in terminology among agencies contribute to the communication problem. In the U.S., the National Incident Management System (NIMS) and the U.S. Incident Command System (ICS) have sponsored efforts to standardize vocabulary across the formal response agencies to enhance interoperability. But military and civilian responders resist conforming to NIMS and ICS guidelines in favor of locally coherent, expeditious terminology. For example, different agencies conceptualize the term “oxygen” differently, due to the different delivery technologies they can access (Flach et al. 2013). As a result, even members within the formal response community may lack awareness of their available resources.
Known psychological bias (Pearson and Clair 1998) pervades the formal organization’s attempt to comprehend the unexpected unfamiliar crisis circumstances (Weick 1988), further compromising awareness. Isolation from the informal response community exacerbates groupthink (Garnett and Kouzmin 2007) and leads to a tunnel vision among specialists (Perrow 1984). Adding insight from the informal response community holds the promise of increasing awareness about conditions on the ground within the formal response community, and contributes to the recommended decentralization of response necessary for flexible and rapid response to evolving circumstances. While contact with the informal response community therefore appears potentially beneficial to the formal response community, the conventional interface employs one-to-one contact between citizens and the formal organizations, typically emergency telephone lines such as 911. This creates a deluge of citizen data and inquiry that risks obscuring relevant information, potentially hindering awareness. Indeed, the professional responder that informed Latonero and Shklovski (2011) refers to the demands of managing the deluge as “inhuman”, (p. 12). Social media provides an alternative to clogging telephone lines, but expands the scope of influence to include both onsite and remote citizens. As a result, social media generates much more content (both relevant and irrelevant) than human recipients can process efficiently. For example, during Hurricane Sandy, a mere 4.5 thousand samples of the 2.5 million posts (0.18 %) generated follow up with the Red Cross (Baer 2012).
Benevolent volunteers operating outside of the pre-established, rationalized task decomposition also create new awareness problems for the formal response community. Volunteers who independently assume responsibility may not directly communicate their intentions, altering the field of operations unbeknownst to the formal response community. Intervention by the informal response community exacerbates the information flow problem between functions, as no protocol establishes an anticipated source or flow of information from the informal response community. While the FEMA handbook (FEMA 2009) establishes a point of contact in the formal response organization responsible for anticipated participants in the volunteer community (such as religious organizations), the question remains as to who serves as the corresponding agent responsible for communicating the activities of the ad hoc volunteer community. In recognition of this problem, the Digital Humanitarian Network (http://digitalhumanitarians.com) has been established to create an engagement interface between volunteer communities and the formal organizations, such as United Nations Office of Humanitarian Affairs (UNOCHA). Nevertheless, the recent UNOCHA- Humanitarian Data Exchange project, (http://docs.hdx.rwlabs.org/) highlights interoperability issues including the persisting need to manage the varying terminology across participants.
1.3 Capabilities of the informal response community
We endeavor to exploit the specific expertise of the ad hoc informal response community without expecting it to possess knowledge of the workings of the formal response community, in particular the manner in which the formal response community articulates its work. Below, we highlight a capability to identify needs and resources to facilitate the allocation of resources that is at the heart of emergency response (Garnett and Kouzmin 2007). Further, social media provide a persisting, accessible record of both intent and action.
Victims and their neighbors may contribute to emergency response by sharing information about the environment (e.g., flood levels, road blockages). Here citizens serve as passive sensors, reporting on the changing state of affairs and implied or associated needs (Sheth 2009). We call these reports of needs seeker behavior . This record of citizen needs aids awareness in the formal response community (Palen et al. 2010). However, citizens may also mobilize and direct their own resources (e.g., vehicles, food, and supplies) before official help arrives (Palen and Liu 2007; Perng et al. 2012). We call these offers of help supplier behavior . This behavior impacts both articulation and awareness within the formal response community. Unanticipated resources might affect decision making regarding procurement and distribution within the community at large to avoid the second disaster of oversupply (such as in the aftermath of Hurricane Sandy), while reducing pervasive undersupply (Fessler 2013). Because supplier behavior alters the environment, it necessitates awareness in the formal response community to either manage the alteration or attempt to circumvent it if necessary. Table 1 illustrates these two types of citizen behavior using Twitter during a crisis.
The ready adoption of social media for seeker and supplier behavior has a more general benefit to the potential cooperation between the informal and formal response communities. Social media messages (called “tweets” on Twitter) constitute what Weick (1988) calls an “enactment”, a self-motivated, material, and symbolic record of action that lends itself to subsequent analysis to facilitate awareness in the formal response community.
We suggest that systematic patterns of language usage in social media can be exploited for computational screening, sorting and inference, and presentation to the formal response community guided by a domain model based on UNOCHA’s Humanitarian Exchange Language (HXL) (Keßler et al. 2013). Systematicity in language usage makes it possible to sort content and thereby reduce information overload for the recipients, who can now select the content they must review. For instance, the fire department need not intercept reports for downed power lines that are dead. Similarly, units responsible for responding to areas of medical need can temporarily suppress the monitoring of social media traffic related to the collection of food donations.
In the following section (2), we discuss related work specific to crisis informatics, and seeker-supplier behavior identification. Section 3 covers the method for mining systematic patterns of language usage in social media for computational screening, and domain model driven resource-based classification for an annotated information repository. Section 4 presents the experimental work and evaluation of the seeker-supplier distinction with respect to human judgment. We complete the paper with a discussion of the findings in section 5, including future avenues of research and conclusions drawn from our work regarding computational assistance in the analysis of social media.
2 Related work on social media in crisis response
Certainly, many researchers and practitioners are actively exploring a variety of paradigms to examine the use of social media during a crisis, especially Twitter. Limited work addresses the use of social media by the formal response community (Latonero and Shklovski 2011). One line of work addresses the distribution of messages to the informal response community from the formal response community. Latonero and Shklovski (2011) report on the use of Twitter by the formal response community to distribute advice to the informal response community, echoing Starbird and Stamberger’s (2010) observation of the prevalence of retweeting content originating in the formal system. Sicker et al. (2010) discuss the numerous policy issues that the formal response community must address in the exploitation of social media, including liability and security.
Several efforts address the use of social media in the informal response community (Purohit et al. 2013b). Similar in spirit to our interest in resource seekers who report on need, Vieweg et al. (2010) provide a detailed analysis of situational awareness content embedded in Twitter traffic, sensitive to the type and phase of the emergency. Their analysis informs the message features that we can anticipate, including the mingling of both resource seekers and suppliers in the corpus and context-dependent variability in the description of the situation and its geographic location. Such variable terminology challenges automated analysis. Data mining efforts such as Ushahidi (see Banks & Hersman, 2009), a successful crowdsourcing based mapping tool, depend on human moderators. Mathioudakis and Koudas (2010) focuses on trend detection in Twitter, to help identify emerging needs during crisis response. Pohl et al. (2012) develop automated methods for clustering crisis-related sub-events expressed in social media content. We appreciate the Pohl et al. (2012) approach for its potential ability to mediate between the terminology of the community and the terminology of the formal response organizations. A noteworthy approach by Starbird (Starbird and Stamberger 2010; Starbird et al. 2012) focuses on exploiting the collective wisdom of the informal response community in vetting and amplifying verified information, to damp rumors and misleading posts by combining the participation of the crowd with machine processing.
Regarding our interest in resource suppliers, The UN Cluster system classifies resources according to the organization responsible for that type. Imran et al. (2013) used a data-driven approach to the classification of resource types with supervised classification. Using a data-driven approach, the data drive the extraction and population of an ontology from social media using Machine Learning based techniques. However, limitations in the sample can limit coverage of the analysis. Reuter et al. (2013) also focus on resource suppliers. Their prototype system organizes the groups, activities, tasks, and comments available in social media. However, user studies point to the need to address the problems of storage, query, and representation to render the data useful for human review. Reuter et al. (2013) do not explicitly address the need to separate resource seeker posts and resource supplier posts that co-mingle in the corpus.
While addressing resource seekers and suppliers separately would seem to reduce clutter for the recipient, separate technologies for the identification of seekers and suppliers obscures the match between the two. The American Red Cross exercises a manual approach to matching, relying on human volunteers to identify relevant content and match resource requests with offers. This results in high confidence in the judgments, but at a high cost of human labor. In another approach to identifying available resources and matching them, specialized portals such as Recovers.org, AIDMatrix.org, and VolunteerMatch.com provide registration of volunteers and donations. These efforts are compatible with our concern for the limited crisis response knowledge in the informal response community and the need for contact with key players in the informal response community. Recently Varga et al. (2013) addressed the issue of matching reported need against aid related messages. However, their computationally intensive Natural Language Processing (NLP) method does not identify the type of resource needs, important for contextually identifying and matching the seeker and supplier intentions. Furthermore, reliance on lexical overlap omits the cases where the same noun is not present in two candidate problem and aid messages. For example, tweet pairs such as “There are many injured people in Sendai city” and “We are sending ambulances to Sendai” match conceptually despite the absence of word overlap. Purohit et al. (2014) performs supervised classification to automatically identify and match social media messages related to needs. However, their approach remains sensitive to the distribution of resources in the sample and compromises classifier generality.
To these efforts we add a top-down, domain knowledge-driven approach to the classification of content to facilitate content search. Using a domain knowledge-driven approach, domain experts provide a hierarchical classification scheme to organize information while also capturing relationships between the classes (Jihan and Segev 2013). The Management Of A Crisis (MOAC) vocabulary (Limbu 2012) and the UNOCHA’s Humanitarian Exchange Language (HXL) ontology (Keßler et al. 2013) reflect the domain knowledge-driven approach. Such models are more comprehensive than the data-driven approach. However, they face the daunting challenge of modeling the entire domain.
Our approach complements ongoing attempts to create vocabulary tags for message classification within the informal response community, as in the Tweak the Tweet concept (Starbird and Stamberger 2010; Starbird and Palen 2010; Starbird 2011) where instructions for categorizing relevant tweets are distributed through Twitter. The resulting labels are amenable to computational analysis and therefore, leverage crowd participation in the computing process. At issue is the source of leverage on the categorization process. Tweak the Tweet empowers the informal response community with the responsibility to categorize, while we employ an ontology guided by the formal response system to infer a categorization. Thus, we make limited assumptions regarding the knowledge of the informal response community. We also note that compliance with artificial constraints (such as labeling) is particularly prone to failure under stress or non-standard circumstances (Dietrich 2003). Furthermore, predefined categories may risk excluding content that fails to fit (Bowker and Star 2000), in part by failing to capture contextual nuance (Furnas et al. 1987) and requiring post-hoc revision. Therefore, our complementary approach localizes flexibility and adaptation in modifiable classification software, inspired by an ontology drawn from the formal response community.
3 Method
We believe that the cooperation between the informal and formal response communities can be improved substantially with computational approaches to filter and sort the social media messages, and we focus here on the Twitter microblogging social network (Tsukayama 2014). To this end, we specifically focus on detecting and abstracting seeker and supplier behaviors. In this manner, the tweet becomes a computationally accessible boundary object of use to the formal organization (Star and Griesemer 1989), but need not require the terminology or reflect the work practices of these organizations.
Making the tweet computationally accessible also allows for abstraction to the pattern level, shifting the initial interpretive process from purely cognitive to partially perceptual, (Bennett and Flach 1992) and providing an approach to managing data overload (Henson et al. 2012). However, while lower levels of abstraction (e.g., tweets with individual requests and specific local references) risk overwhelming the human reviewer, high levels of abstraction risk denying a role for human interpretation. An advantage of the computational boundary object is that the human reviewer can permeate the abstraction, to audit and evaluate the data sources that contribute to the organizing representation. The right dimensions of abstraction combined with computationally supported permeability are critical to supporting coordination between the formal response organization and the various hybrid, informal, and emerging organizations.
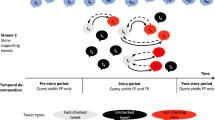
We approach the problem of analyzing and summarizing of social media traffic from the informal response community using the analysis framework shown in the Figure 1. Our general computational strategy is to cull, sort, and index a tweet corpus for subsequent human review, consistent with the functions of the formal organization. We rely on a small number of modular processing steps, each consisting of limited and simple heuristics. While we avoid many of the semantic challenges of more intensive NLP, we also acknowledge the potential of missing important but unique content. Our view is that a smaller subset of useful and organized actionable information trumps a more comprehensive but noisy corpus that requires extensive low-level human review. Here we focus on the following steps (marked as Si, where i = 1 to 6) in Figure 1.

Analysis framework to assist cooperation between the formal and informal response communities.
-
(S1) Data collection: Event related data collection in real-time.
-
(S2) Conversational Classification: Corpus filtering with a domain-independent classification of coordination, based on indicators of conversational behavior.
-
(S3) Resource-based Classification: Semantic analysis using a disaster related domain model, extending the current model with need-related linguistic indicators to identify relevant need data in the tweet and any links it contains. This includes resources, actors, and spatio-temporal information.
-
(S4) Lexical Pattern-based Seeker-Supplier Identification: Limited lexical and syntactic analysis of verbs for a particular kind of tacit cooperation to distinguish between resource needs and their availability.
-
(S5) Annotated Information Repository: A repository of annotated tweets with resource-need type, behavior (seeker or supplier) and metadata including location, time and author information in a Semantic Web technology based queryable form.
-
(S6) Information Visualization Platform: A spatio-temporal-thematic visualization platform supported by the annotated information repository, for human review augmenting our Twitris system (Purohit et al. 2013a; Sheth et al. 2014). Below we provide background material for each of these steps.
3.1 (S1) Data collection using Twitter
Twitter is a microblogging service that provides a social network structure and medium, allowing users to distribute short messages (tweets). Twitter supports conversations as well as information distribution, by enabling tweet forwarding to other groups of users. Users post updates and subscribe to (or ‘follow’) tweets from other users, thus forming social networks. A 140 character limit influences the scope of message content and therefore constrains communication practices. Consequently, tweets may contain URL links to web pages or blogs, sometimes employing condensed URL versions shortened by external services (e.g., http://t.co/vt8fhbn7). A hashtag convention (e.g., #JapanEarthquake) allows users to define searchable topics. Platform-supported engagement features also include Reply (tweet in response to another user’s tweet), Retweet or RT (forwarding of someone’s tweet), and Mention (acknowledging another user).
To reflect language behavior in response to a crisis, we collected data for three different events: The Haitian 2010 and Japanese 2011 earthquakes and Hurricane Sandy 2012. Data collection using Twitter has two possible methods: an older search-based API using keywords and a newer streaming-based API (Twitter Developer 2013). We used the older method for data collection during the Haiti 2010 and Japan 2011 crises (Nagarajan et al. 2009). The newer Twitter Streaming API provides real-time tweet collection, including tweet text and metadata (timestamp, location, and author information), which we used for Hurricane Sandy 2012. Our crawling modules are based on the Twitter Storm distributed real-time computation system (Marz 2011) that utilizes the Streaming API to provide real-time data compatible with additional real-time computation. We can track up to 5,000 users and 400 keywords simultaneously using the streaming API’s filter method. The Streaming API rate limits the crawl if streaming data for the desired keywords rises above 1 % of the fire hose, which often happens during large-scale disasters, creating data loss (Twitter Developer 2013).
3.2 (S2) Conversational classification: domain independent analysis
Information filtering begins by detecting coordinated citizen efforts in social media traffic using domain independent linguistic properties to identify potentially coordinated verbal exchange (Honeycutt and Herring 2009). As reported by our prior work (Purohit et al. 2013c), psycholinguistic theory and conversation analyses inspire our detection of coordination (Clark and Wilkes-Gibbs 1986; Goodwin and Heritage 1990; Mark 2002). Accordingly, properties of an exchange, including opening and closing phrases, anaphora, and deixis, reveal the existence of conversational coordination, and hence the emergence of a new informal response community. Our research showed that features of conversation are better indicators of relevant substance than platform-supported engagement features alone, such as “Reply”.
For this purpose, we use machine learning classifiers developed in our prior work (Purohit et al. 2013c) for filtering tweets reflecting coordination in conversation. First, we generate features for each tweet by checking the frequency of certain linguistic constructs in the text, such as the subject pronoun set (she, he, we, they). For example, a tweet containing the word ‘he’ twice will receive a score of “2” for this linguistic feature. Second, we pass the feature vector through a classification model that predicts whether a tweet is relevant for further processing or if it is just noise. Details on the rationale and construction of these classifiers appear in Purohit et al. (2013c).
3.3 (S3) Resource-based classification using domain model: domain dependent analysis
In this step we add the ability to identify domain content relevant to emergency response. While many similar efforts exist, our specific concern is the preservation of near real-time analysis for two functions by leveraging domain model: a.) to inform the tweet annotation technique for resource-need representation, and b.) to manage the information for the annotated repository to enable awareness for the formal response community. We extend the domain knowledge-driven models discussed previously (MOAC and HXL) with required but missing concepts for seeker and supplier behavior, and indicators of resource needs using a lexicon. For example, the “shelter” class contains words “emergency center,” “tent,” and “shelter,” along with lexical alternatives. For the present demonstration, we focus on three resource categories: food, shelter and medical needs. Thus, we endeavor to exploit a minimum, but always expandable subset that provides the maximum coverage while controlling false alarms.
For creating lexicons of indicator words for concepts, we relied on various documents collected via interactions with domain experts (Flach et al. 2013), our Community Emergency Response Team (CERT) training, Rural Domestic Preparedness Consortium training, and publically available references (Homeland Security 2010; FEMA 2012; Verity 2011). Using a first aid handbook (Swienton and Subbarao 2012), we created an extensive “medical” subset of emergency indicators, where we identified words which pertained specifically to first aid or injuries and included those words along with variations in tense (i.e., breath, breathing, breathes) and common abbreviations (i.e. mouth to mouth, mouth 2 mouth, CPR). A local expert with FEMA experience augmented the model with additional indicators and provided anecdotal context. The current model with food, medical, and shelter resource indicators contain 43 concepts and 45 relationships, and is available at http://twitris.knoesis.org/images/datasets-and-models/. We created this domain model in the OWL language using the Protégé ontology editor (Protégé 2013). Each type of disaster is listed as an entity type with indicators for that disaster listed as individuals under a corresponding indicator entity. Therefore a relationship is declared stating that a particular disaster concept, say Flood, relates by property ‘has_a_positive_indicator’, with ‘Flood_i’ indicator entity, that includes all words under that heading. Each disaster has a declared negative relationship with the negative indicator list (e.g., ‘erotic’ under sexual words indicators) under the entity name Negative_Indicator_i. Finally resources are declared as individuals under the appropriate entity in the same way, but relationships are not explicitly stated with any disaster in order to provide flexibility.
Using the disaster domain model to identify resources, we identify the class of relevant resource needs based on the presence of the entities in the tweet text in correspondence with the lexicon of the disaster domain model. For example, a message containing a request for blood donation will get classified with the resource need class ‘Medical’ in the domain model based on existence of ‘blood’ being in our medical lexicon. To express detail, tweets may include URL references to an external medium (e.g., “RT @Chillie_Mo: Overnight shelter for Hurricane victims in NY http://t.co/feLdI7hj”). The frequency of these links suggested the need to examine the relevance of the content of these external sources, using the resource needs lexicon in the disaster domain model. Our URL extraction and processing module extracts and expands the URL, as needed. For example,http://t.co/feLdI7hj expands to http://www.nyc.gov/html/misc/html/2012/overnight_shelter.html). We crawl the URL for its content and title. If the content contained words in our lexicon for any resource need, we considered it to be a potentially useful message.
3.4 (S4) Lexical pattern-based seeker-supplier identification: domain dependent analysis
Consistent with our focus on the identification and separation of seekers and suppliers, we separate the corpus into tweets indicating seeker behavior for resource needs and tweets indicating supplier behavior of available resources or help. We exploit simple heuristics, local to the tweet, with few dependencies and limited effort to invoke clarifying context. Three sets of heuristics contribute to our analysis: lexical heuristics, syntactic heuristics, and spatio-temporal analysis.
Lexical Heuristics--We rely on a lexicon of verbs to distinguish between seeker and supplier behaviors. While it is possible to articulate need without a verb, for example by stating the noun in question (e.g., “Water!”), such formulations are potentially ambiguous regarding the seeker-supplier distinction. We focus primarily on verbs corresponding to Schank’s P-Trans primitive (Schank 1972), reflecting the transfer of property. Levin’s analysis of verbs (Levin 1993), grounded in over 800 citations in the scholarly literature, provides a resource for selecting these verbs. Our lexicon of seeker-supplier verbs includes the Levin categories of: give, future having, send, slide, carry, sending/carrying, put, removing, exerting force, change of possession, hold/keep, contact, combining/attaching, creation/transformation, perception, communication. We included categories of slide, exerting force, combining/attaching, creation/transformation, and perception to test discriminant validity.
Syntactic Heuristics--The analysis requires syntax as well as a lexicon. For example, a subject with the main verb “have” and any noun suggests a supplier. However, the same string preceded by the auxiliary verb “do” and the pronoun “you” suggests a seeker because the combination of syntax and pronoun reverses the illocutionary force through an interrogative structure. However, the abbreviated and unconstrained Twitter medium prevents reliance on punctuation for the identification of interrogatives. Pronouns and word order assist in the seeker-supplier distinction associated with interrogatives, e.g., “Can you send water? (seeker) and “I can send water” (supplier). We exploit the auxiliary verbs (‘be’, ‘do’, ‘have’, as well as the modals ‘can’, ‘could’, ‘may’, ‘might’, etc.), word order (e.g. verb-subject positions), question words (‘wh’-words and ‘how’), and the conditional (‘if’).
An exhaustive list of such limited heuristics is still subject to error, largely due to the phenomenon of indirect speech acts, which rely on shared background knowledge to reinterpret apparently factual information (Searle 1975; Clark 1979). Accordingly, asserting a problem is a classic approach to articulating need, e.g., “it is hot in here” means “I need air” and/or “open the window”. Similarly, “The Red Cross can provide housing” provides a supplier fact. However, “I bet the darn governor can provide housing” could imply a disgruntled seeker employing an indirect speech act, because unlike the Red Cross, the governor does not directly supply housing. Moreover, we cannot yet identify the implicit interrogative in “Sam thought that Beth had water”, which calls into question whether Beth in fact had water (Higgenbotham 1997). The factual statement could also imply that Beth is seeking water, Sam is seeking water, or the speaker is seeking water, none of which is actually asserted.
The above two types of heuristics lead to development of a number of simple templates for rule based classifier that combine syntax and verbs associated with the transfer of property to suggest illocutionary force. We list them in Table 2.
Spatio-Temporal analysis--A disaster prompts a global informal community response, much of which is irrelevant to the immediate response of the formal organization, for example the distribution of redundant reports, instead of new on-site information about the situation. Hence a subsequent phase of analysis should address the spatio-temporal dimensions of the tweet. Proximal seekers and suppliers have more immediate utility to a particular response organization than remote seekers and suppliers. On the other hand, remote suppliers could influence longer term planning and also support crowd based filtering (Starbird et al. 2012). For these reasons, we separate and organize the data on the dimensions of space and time. Unfortunately, most tweets do not contain geolocation tags. For example, only 21 % of the tweets from the Hurricane Sandy data had geolocation information (location information from tweet metadata as well as author’s profile). Consistent with Cheng et al. (Cheng et al. 2010) we found that location information may be embedded in text. In our case this arises from the passive language employed. E.g. “Manassas opens pet friendly shelter: City of Manassas VA will open a shelter for Hurricane Sandy victims” indicates the location of available resources. However, we do not address the text embedded location issue in this paper.
3.5 (S5) Annotated information repository
We create the annotated corpus for a disaster event by associating metadata with each tweet as shown in Figure 2, encoded in the semantic web technology format, RDF: Resource Description Framework (RDF Core Working Group 2004). Our metadata includes resource class, author name, time of posting, geolocation (retrieved from both tweet metadata as well as author profile location) via Google maps APIs, hashtags (user classified topics), resource-need type, seeker and supplier behavior, etc. We extend the annotation mechanism for further enrichment of the metadata with entities from DBPedia (Auer et al. 2007) that helps fetch associated information about people, places, and organizational affiliation of the entities that can be leveraged for complex queries.

Sample of extensible metadata for an annotated tweet.
3.6 (S6) Information visualization platform: Twitris
The resulting database of annotated tweets with resource needs, seeker-supplier behavior, and other tweet metadata is potentially accessible to human analysis and query. However, the presence of both volume and detail requires a combination of search and abstraction capabilities, which we are calling a permeable boundary object. We provide a prototype visualization platform for assisting coordination, primarily to illustrate the functionality that is both likely required and feasible given a computationally accessible information repository. This enables users to filter information according to their goals (e.g., by geography and time), by need category, and by seeker versus supplier nature. For example, one can explore complex questions, such as ‘give me a list of all users posting about shelter need in the New Jersey area’ or ‘where is the blood donation center near Dayton Ohio?’ For the purpose of visualization, we extend the Twitris platform (http://twitris.knoesis.org), currently in version 3 (Purohit et al. 2013a; Sheth et al. 2014), which provides social media analysis along three dimensions: spatio-temporal-thematic (Nagarajan et al. 2009), people-content-network (Purohit et al. 2012) and sentiment-emotion-subjectivity (Smith et al. 2012). Twitris presents important “nuggets” (weighted key-phrases) extracted from the tweet data for a chosen time and location, thus providing a sense of community activity from a spatio-temporal perspective. Twitris also presents a cumulative version of all such information nuggets (http://twitris.knoesis.org/oklahomatornado/topics/).
4 Experiments and results
In this section we describe the data collection (4.1) for experiments to evaluate the approach, followed by results for the domain independent and dependent analyses (4.2) covering model driven resource-based classification and the seeker-supplier analysis. The output populates an annotated information repository accessible via a visualization platform (4.3). We complete the section with evaluation (4.4).
4.1 Data collection
To study the three different types of events (Haiti Earthquake 2010, Japan Earthquake 2011, and Hurricane Sandy 2012) as shown in Table 3, our crawler in the Twitris system constantly collected the filtered stream of English language tweets from the Twitter Search and Streaming API for event-related keywords and hashtags (e.g., “hurricane sandy”, “#sandy” for the Hurricane Sandy 2012) during the period indicated in Table 3. We note an event of crawling server failure for 5 hours on the night of 30 October affecting the Hurricane Sandy data set. An initial set of keywords and hand-selected hashtags served as a seed set. We then expanded the initial set by extracting the top frequent terms in the collected data and manually checked relevance. Our final seed sets contained two core keywords (their variants include hashtag combinations) for the Haiti earthquake, ten for the Japan earthquake, and five for Hurricane Sandy events. The Japan earthquake event has a larger seed set due to extensive discussion around contingent events like the Fukushima reactor leak and the resulting tsunami.
4.2 Domain independent and dependent analysis results
Table 4 illustrates some characteristics of the domain independent analysis-based filtering. Table 5 presents the distribution of resource-based need classification for our data sets and Table 6 shows statistics about the seeker-supplier behavior identification for different cases of need types for the output of domain independent analysis for a disaster event data stream.
Domain independent analysis substantially reduced the size of the corpus for further analysis, although less dramatically for the Hurricane Sandy sample. As shown in Table 6, our approach classifies a small percentage as shelter, medical, or food related, and as shown in Table 7, a small percentage as seeker or supplier.
As shown in Table 6, our classification scheme identifies more supplier than seeker behavior. Table 7 illustrates the results of this processing with specific examples from the corpus in separate sections corresponding to algorithm judgments of not relevant, seeker or supplier. Despite the mention of a hurricane, we are able to screen out the pervasive “thoughts and prayers” message, and irrelevant commentary that does not trigger our ontology. We note the identification of seeker behavior for basic needs- food and shelter in the messages of informal response community, which can contribute in awareness of the formal response community. Also, the association of multiple need types can be observed within a single message also, such as for voluteering and food. Additionally, to explore seeker behavior in depth, we analyzed other important needs related data, such as power and animal care. Seeker behavior is sometimes associated with individual declarations of power outages. When tied to location information, these can be helpful depending upon the type of crisis and the local power distribution system. Unpredictable, narrow or spotty bands of crisis, for example from a tornado, particularly in combination with above ground power distribution challenge damage assessment. We also note the ability to identify needs related to power such as generators, batteries and power cords. Finally we note the detection of pet care needs, which in Hurricane Katrina proved so detrimental to evacuation decision making that it spawned the U.S. Pets Evacuation and Transportation Standards Act of 2006 (https://www.govtrack.us/congress/bills/109/hr3858#summary/libraryofcongress). Supplier behavior includes pointers to databases as well as local suppliers, of potential interest to the formal response community.
4.3 Visualization of spatio-temporal resource distribution
The visualization prototype provides several functions that hinge on the prior analyses and resulting annotated data repository. The prototype in Figures 3, 4, 5 and 6 employs our Twitris platform for social media event analysis (see also section 3.6). Figure 3 illustrates the basic capability to index tweets by geographic location.

Visualization interface showing location points (pushpins) on the map with substantial data clusters on a chosen day for the Hurricane Sandy event.

Visualization interface showing important key phrases (tags) in the repository annotated with supplier behavior for a chosen geolocated pushpin and time.

Visualization interface showing important key phrases in the repository from the tweet set annotated with seeker behavior for a chosen geolocated pushpin and time.

Related content to provided better context in the bottom section for the selected key phrase “hurricane sandy victims” in the tag cloud shown from the annotated repository, for the event “Hurricane Sandy”.
We augment our Twitris platform functionality by presenting filtered information along multiple dimensions. First, we use color to layer a classification of resource-needs on the data (Figure 4). The tabs in Figures 4 and 5 illustrate the specific ability to sort on messages with seeker and supplier behavior using key phrases. Figure 5 illustrates the potential to permeate the abstraction to reach individual tweets (shown in Figure 6). Thus, one can ask the question, “in a particular location X, users Y are asking for what kinds of resources Z”, etc. Consistent with the practice of having television sets in the emergency operations center, we also include access to the richer contextual information from the Web of data— related news, blogs/articles, and Wikipedia.
We make no claims concerning the optimal usability of this prototype interface. Our point is the computational feasibility of near real-time domain-based abstraction, and associated capabilities for pattern detection, sorting, and querying to transform the tweet corpus into a boundary object between the informal and formal response communities.
4.4 Evaluation
The methods covered in this paper include two new major steps: a resource-based needs classification using a domain model, and seeker-supplier intent identification. The first step performs the task of entity spotting in the tweet text based on the given sets of lexicon in the domain model for respective resource-needs such as ‘medical’. We skip evaluation of this simple keyword matching task in favor of the second step. For the second step, we developed a random set of 2000 tweets from the Hurricane Sandy event corpus. Using native speaker language skills, a research assistant unfamiliar with the project technology defined the illocutionary force (serving as ground truth) for each tweet as: seeker, supplier, both, or none. In this capacity, the human judge provides a challenging common sense test with access to far more syntax, semantics and pragmatics than our heuristics. Below in Table 8, we present the agreement between these ground truth assignments and the annotations our approach computes.
Table 8 contains two types of analyses. The first type (columns 1, 2, and 3 at the left), which we call “relevance”, examines the agreement between ground truth and the algorithm, collapsing across the seeker/supplier distinction. Any mismatched rating between “none” and “seeker or supplier” constitutes an error. Similarly, any combination of “seeker” and “supplier” ratings constitutes a hit. The second type of analysis (columns 4 and 5 at the right) specifically examines the seeker/supplier decision by separating out only those tweets that received either a seeker or supplier label for both ground truth and the algorithm. For all analyses we present D’, and precision and recall metrics, along with Cohen’s Kappa metrics, which take into account biases in the distribution of positive and negative cases relative to ground truth.
Using Landis and Koch guidelines, Cohen’s Kappa suggests “fair” agreement for the relevance judgment for the full evaluation tweet set. We also split the full evaluation set into separate subsets of tweets with and without URL links (see Table 9), with the expectation that material in the URLs unavailable to the ground truth judgment was potentially increasing false alarms. However, splitting the randomly selected set into subsets that includes tweets with URLs and those without provides an unexpected improvement in the evaluation metrics.
We examined seeker/supplier agreement using just those tweets receiving seeker/supplier judgments from both ground truth and the algorithm. Because both the algorithm and ground truth had the potential to judge a tweet as both seeker and supplier, we required a policy to assess agreement for a “both” rating with both “seeker” and “supplier”. We examined a liberal policy, in which the ambiguity was resolved in favor of an agreement, and a conservative policy, in which the tweets in question were deleted from the analysis. For both approaches D’ and Cohen’s Kappa values are both “moderate”. The good precision and recall values for this complex seeker-supplier analysis suggests that our algorithms have captured much of the common sense seeker-supplier judgment.
5 Discussion
Our approach to merging the informal and formal crisis response community in an effective collaborative system relies on the inherent abilities of the informal response system in observing the affected area, contributing to the supply of needed resources and providing a record of their activities. We use computational technology to interpret and annotate this content using models from the formal response domain, to promote compatibility with the formal domain. We have combined conversation analysis and modest NLP, with a lightweight HXL extended domain model and Semantic Web technology driven data management, to distinguish between seeker and supplier behavior tweets and their accessibility. It is intended to assist in emergency response coordination in both the effective distribution of resources and enhanced awareness of activity in the informal response community. Below we identify conclusions, limitations and implications regarding the language behavior in the informal response community, the computational approach and the promise of such techniques for crisis management.
5.1 Language behavior
We exploit the systematic language behavior that appears in the medium in order to annotate the observations and activities of the informal response community for the formal response organization. Our annotation focused on seeker and supplier because a seeker informs awareness of the changing conditions, while a supplier informs the distribution of resources even while they change the environment. By avoiding artificial roles for the informal response community in the annotation process, we avoid assumptions about the compatibility of public knowledge and terminology with the technical detail of the formal emergency response organizations.
The seeker-supplier behavior agreement was good, despite a number of limitations in the analysis. For example, our algorithms do not account for the ambiguity of seeker donations, which may function as both an articulation of need as well as a potential source of help. We are also missing rules for handling negation. We suspect that potential seekers are not likely to articulate the absence of need using Twitter, e.g., “I don’t need shelter”. Here negation does not flip seeker to supplier, but rather seeker to noise. The absence of rules for negation could be increasing our false alarms on the relevance decision. Access to the Twitter stream provides a unique opportunity to assess the prevalence of negation during a disaster.
The syntax pertaining to the contributions of seekers and suppliers is admittedly limited to factually-oriented declarations and potentially misses indirect speech acts, in which speakers indicate a problem that implies a request for assistance. For example, a message could inquire “Do you have any water?” instead of “We need water”. We simply do not yet know the prevalence of indirect speech acts in these corpuses. However, politeness is often a motivation for the indirect speech act. While the collapse of social order in a disaster is a myth (Quarantelli 2008), politeness violates conversational maxims, regarding quantity, manner, and relevance (Pinker 2007). As such, the modification of more efficient propositions occurs for a reason, for example avoiding the embarrassment of denial. In a crisis, the criticality and urgency of need would seem to eliminate concern for embarrassment. At the moment, the ability to sort and search on concepts in the domain model (e.g., medical properties, shelter, and food) still provides responders with access to content embedded in an indirect speech act, although these won’t be classified along the seeker-supplier distinction. For example, we provide support for identifying the prevalence of population complaints like a headache in a region affected by a chemical spill, or gastrointestinal problems in the case of an epidemic or contamination.
5.2 Computational approach
Our general strategy is to annotate incoming tweets with metadata, calculated in near real-time and stored in a database for later query. While the annotation does depend on the systematic use of language in the tweets in the informal response community, much of the inference depends on the ontology of the formal response community. In this sense, the computation generates a boundary object and common ground between the informal and formal crisis response community. The existence of this annotated database avoids additional complex, time-consuming human or computational analysis at querying time, thereby supporting real-time human interaction. The metadata are also critical to the ability to present abstract, permeable summaries of the Twitter data that are accessible for further human analysis while remaining sensitive to data overload.
Modular, relatively modest processes and an HXL extended disaster domain model generated promising results for the ability to separate relevant, actionable tweets from noise. Our work establishes a preliminary reference point for subsequent improvements, either employing more computationally intensive approaches, or, as we favor, a more complete set of heuristics for seeker-supplier behavior as well as resource-needs and an enriched domain model with an additive impact on processing time. Our evaluation metric values for the seeker-supplier distinction fare well relative to approach of Varga et al. (2013) with much more computationally intensive and restricted methods, given our precision values as high as 0.85 suggesting an ability to capture language patterns computationally. Their approach generally obtained Kappa scores across different analyses ranging from 0.55 to 0.74, although we note that unlike us, they did not characterize the corpus composition, which has great bearing on chance agreement. In addition they used a different disaster data set, and we suspect a different distribution of signal and noise, as suggested by recall statistics that are much lower (as low as 0.30) than ours (ranging between 0.61 and 0.77). We also note that our approach gives higher recall compared to Purohit et al. (2014) but lower precision. However, their approach intentionally focused on higher precision than recall, and therefore is not directly comparable. Nevertheless, we note the low precision for our relevance analyses, revealing a specific concern for false alarms likely resulting from a domain model that is too generic. This was one motivation for developing our own lexicon sets in this study, targeting domain-specific resources, and the effort to transfer property between seekers and suppliers.
We have also demonstrated the ability to analyze embedded links for filtering irrelevant content, which is almost certainly beyond human capability in near real-time at the required scale. We were initially surprised by a potential correlation between URL existence and human judgment. Perhaps the URL is a proxy for complex content that we have not yet captured in our rules. Or perhaps the mere presence of a URL suggests substance (as opposed to irrelevant rants). Therefore URLs affect the ground truth judgment by creating a general impression of the tweet trustworthiness, assuming restraint in the creation of URLs. Starbird et al. (2010) note that tweets with URLs reflect well-distributed knowledge, while tweets without URLs provide more unique content of greater interest to the responders. However, the availability of information on the internet does not guarantee its accessibility to responders. In addition, the URL existence appears to be a useful property for partitioning the tweet corpus, consistent with our goal of focusing human effort when and where it is most needed and leaving the remainder for computational analysis. Thus our cheap domain specific heuristics could be as good as, if not better than, thorough and slow analysis for a large number of cases (Gigerenzer and Goldstein 1996).
5.3 Domain considerations
While our primary motivation is to facilitate cooperation between the formal and informal response communities, we note a potential evolution in the delivery of emergency services. In this regard, we make several observations. First, consistent with Palen and Liu 2007; Perng et al. 2012; and Reuter et al. 2013 we note a substantial effort to supply resources, from both the local and global informal response community. Making this accessible to the formal emergency response organization constitutes a potentially dramatic change to the conduct of emergency response operations, which otherwise must rely on either pre-arranged delivery contracts or idiosyncratic intuition about the location of resources (Flach et al. 2013). Currently there is no mechanism in place for someone outside of the formal emergency response organizations, for example an auto supply store, to communicate a stockpile of car chargers for cell phones.
We also note concern for the alignment of any technology and its abstractions (Bowker and Star 2000) with tacit, socio-cultural assumptions about crisis response. The focus on patterns of group need as opposed to individual need implies a culture that values distributing resources according to where they best serve the community. This may conflict with an assumption of the informal response community (particularly wealthy communities who ordinarily enjoy immediate response to a request for help) that resources exist to address individual need on demand. However, in the crisis scenario, required resources are limited, and a cry for help does not guarantee a timely response. Worse, persisting emphasis on the individual contact may in fact distract from the effort to maximize benefit from those resources that are available. Abstraction also reflects values in more explicit fashion, potentially interfering with the discovery of unanticipated patterns. For example, we highlight medical, shelter, and food. We could include religious resources, transportation, or trauma counseling. While we are optimistic about expanding the annotation scheme, our primary response to the certain risk of an incomplete analysis is permeability of the abstraction to the raw, albeit massive, data set.
5.4 Future work
Our ongoing work addresses the three themes just discussed. Regarding the computational approach, we are currently working to extend the domain model further with more HXL (Keßler et al. 2013) concepts beyond the seeker-supplier behavior of resource needs to assist coordination, for example, to coordinate discovery of the location of missing persons. Because the ontology and corresponding lexicon must change, we are investigating the inclusion of technological disasters, where computer systems in control of public utilities are compromised. We are already engaging in the World Wide Web consortium (W3C) group on emergency information management that is working to create standard recommendations using a Semantic Web framework, specifically advancing the coordination assisting functions in the modeling. Finally, we plan to address the event evolution problem using the Continuous Semantics framework (Sheth et al. 2010) to model evolving knowledge for improving coverage in the Twitter streaming data collection process. Nevertheless, reducing false alarms despite a growing knowledge base is a key to making the medium useful. As in our previous work (Purohit et al. 2013c), machine learning techniques can help us rank heuristics to identify the most diagnostic rules.
Work remains on matching seekers with suppliers. Presently we rely on human observers to discern the appearance of proximity that appears at the spatio-temporal visualization interface. Mapping the location information associated with both seekers and suppliers can help in the decision making for corresponding transportation paths (and delivery feasibility estimates for remote suppliers). We also note that recovering location information from tweet data suffers from missing geolocation metadata of the tweets and author profiles. Geographic tagging is critical to making such functions useful. We are currently investigating the identification of location information from text using the Stanford Parser (De Marneffe et al. 2006), based on Finkel et al. (2005), and annotating the identified location using a geolocation knowledge base such as DBpedia (Auer et al. 2007).
We will leverage our existing ability to gather and annotate tweets to continue a characterization of language behavior in this environment. The prevalence of indirect speech acts and the function of negation bear on the general influence of the medium on language behavior. Our use of a single source of ground truth does not acknowledge idiosyncratic, culturally laden contributions to the pragmatics of any utterance. This is not a deficiency that yields simply to consensus between more coders. At issue is the relevance of different cultures to the common sense judgment of seeker and supplier.
As we improve our technical capability, empirical evaluation with users takes on greater urgency, and we plan to work on improving it. Sufficient capability exists to support performance studies with human users. Empirical evaluation with users addresses the fundamental question of the importance of the seeker-supplier analysis as it contributes to cooperation between the formal and informal response communities. To be sure, there are many other dimensions of cooperation in this domain, e.g., the emergent cooperation exclusively within the informal response community that both Starbird and Palen (2010) and Purohit et al. (2013c) associated with social media. We are eager to understand the relative contributions of these dimensions.
In so doing, we face the usual measurement challenge of identifying suitable process and performance quality metrics in complex domains, along with potential modifications to the task resulting from the introduction of technology. For example, abstraction and summarization masks the role of individual need and could alter decision making and hence outcome in the distribution of resources. In addition, credit assignment in a complex, distributed task is not straightforward, as subtle variations apart from the function of the technology can influence process and outcome. For this reason, we will also continue to pursue verification that the technology is performing as claimed.
5.5 Contributions and Conclusion
We propose a linguistically inspired model to identify seeker and supplier behavior in social media posts, in order to enhance awareness and the articulation of work across the formal and informal response communities. The first step uses domain independent analysis to filter out messages with potential coordination relevance. The second step uses a lightweight HXL extended domain model to assist message classification for resource-needs and linguistic patterns for seeker-supplier behavior identification. The output of these analyses is a queryable Semantic Web repository of geographically and temporally situated, annotated tweets. Initial evaluation demonstrated fair to good agreement with the common sense judgment of seeker-supplier. We plan to release data sets for the three major disaster events we have examined, with 6 million tweets to support benchmarking in the research community.
The domain models, processing and the resulting repository scale additively with increases in the scope of the analysis, to enable near real-time processing in the creation of the repository, and real-time response to queries anticipated in prior processing. To illustrate the engagement this database supports, we present a visualization prototype that makes activity in the informal response community accessible to human review by the formal response organization. Summaries of the data (in the form of spatio-temporal aggregations and high frequency terms categorized according to the seeker-supplier distinction) counter the potential for data overload. The computational foundation of these summaries allows reviewers to permeate below the summaries to access and interpret the raw data. While computation aggregates messages with accessible content, filtering also allow human effort to focus on those aspects of the corpus that are less compatible with rule-based analyses. This technology has potential impact on the conduct of emergency response, by enhancing awareness in the formal response community to focus on patterns of need and assisting articulation by clarifying available resources. Future work will expand the domain analysis, assess the contributions of existing processes, characterize the usage of social media and increase and evaluate capability to support the formal organization.
References
Auer, Sören, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives (2007). Dbpedia: A Nucleus for a Web of Open Data. Berlin Heidelberg: Springer.
Baer, Drake (2012). As Sandy Became #Sandy, Emergency Services Got Social. Fast Company, November 2012. http://www.fastcompany.com/3002837sandy-became-sandy-emergency-services-got-social. Accessed 19 June 2014.
Banks, Ken and Erik Hensman (2009). FrontlineSMS and Ushahidi: A Demo. In Proceedings of the Third Information and Communication Technologies and Development, Doha, Qatar, 17–19 April 2009. IEEE, p. 484.
Bennett, Kevin. B. and John Flach (1992). Graphical Displays: Implications for Divided Attention, Focused Attention and Problem Solving. Human Factors, vol. 34, no. 5, pp. 513–533.
Bowker, Geoffrey C. and Susan Leigh Star (2000). Sorting Things Out: Classification and Its Consequences. Boston: MIT Press.
Cheng, Zhiyuan, James Caverlee, and Kyumin Lee (2010). You are where you Tweet: A Content-Based Approach to Geo-Locating Twitter Users. In Proceedings of the 19th ACM international conference on Information and knowledge management, Toronto, Canada, 26–30 October 2010. New York: ACM Press, pp. 759–768.
Clark, Herbert H. (1979). Responding to Indirect Speech Acts. Cognitive Psychology, vol. 11, pp. 430–477.
Clark, Herbert H. and Deanna Wilkes-Gibbs (1986). Referring as a Collaborative Process. Cognition, vol. 22, no. 1, pp. 1–39.
Clark, Herbert H. and Susan E. Brennan (1991). Grounding in Communication. Perceptions on Socially Shared Cognition, vol. 13, pp. 127–149.
De Marneffe, Marie-Catherine, Bill MacCartney, and Christpher D. Manning (2006). Generating Typed Dependency Parses from Phrase Structure Parses. In Proceedings of the 5th Edition of the International Conference on Language Resources and Evaluation (LREC), Genoa, Italy, 22–28 May 2006. pp. 449–454.
Dietrich, Ranier (2003). Communication in High Risk Environments. Hamburg, Germany: Helmut Buske Verlag.
Dynes, Russell R. and Enrico Quarantelli (1970). Interorganizational Relations in Communities under Stress. 7th World Congress of Sociology, Varna, Bulgaria, 14–19 September 1970. Varna, Bulgaria: Bulgarian Organizing Committee.
Dynes, Russell R. (1983). Problems in Emergency Planning. Energy, vol. 8, nos. 8–9, pp. 653–660.
FEMA (2009). Incident Management Handbook. Federal Emergency Management Agency. Washington, D.C.: U.S. Government Printing Office.
FEMA (2012). Community Emergency Response Team Basic Training Participant Manual. Federal Emergency Management Agency, June 2012. https://www.fema.gov/library/viewRecord.do?id=6137. Accessed 19 June 2014.
Fessler, Pam (2013): Thanks, but No Thanks: When Post-disaster Donations Overwhelm. NPR, January 2013. http://www.npr.org/2013/01/09/168946170/thanks-but-no-thanks-when-post-disaster-donations-overwhelm. Accessed 19 June 2014.
Finkel, Jenny Rose, Trond Grenager, and Christopher D. Manning (2005). Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling. In Proceedings of the 43nd Annual Meeting of the Association for Computational Linguistics (ACL 2005), Ann Arbor, MI, 25–30 June 2005. Stroudsburg, PA: Association for Computational Linguistics, pp. 363–370.
Flach, John M., Debra Steele-Johnson, Valerie L. Shalin, and Glenn C. Hamilton (2013). Coordination and Control in Emergency Response. In Badiru & Racz (eds.): Handbook of Emergency Response: A Human Factors and Systems Engineering Approach (533–548). New York: Taylor & Francis, pp. 533–548.
Furnas, G. W., Landauer, T. K., Gomez, L. M., & Dumais, S. T. (1987). The Vocabulary Problem in Human-System Communication. Communications of the ACM, vol. 30, no. 11, pp. 964–971.
Garnett, James L. and Alexander Kouzmin (2007). Communicating Throughout Katrina: Competing and Complementary Conceptual Lenses on Crisis Communication. Public Administration Review, vol. 67, no. s1, pp. 171–188.
Gigerenzer, Gerd and Daniel G. Goldstein (1996). Reasoning the Fast and Frugal Way: Models of Bounded Rationality. Psychological Review, vol. 103, pp. 650–669.
Goodwin, Charles and John Heritage (1990). Conversation Analysis. Annual Review of Anthropology, vol. 19, pp. 283–307.
Heath, Christian and Paul Luff (1992). Collaboration and Control: Crisis Management and Multimedia Technology in London Underground Line Control Rooms. Computer Supported Cooperative Work (CSCW): An International Journal, 1, nos. 1–2, pp. 69–94.
Henson, Cory, Amit P. Sheth, and Krishnaprasad Thirunarayan (2012). Semantic Perception: Converting Sensory Observations to Abstractions. IEEE Internet Computing, vol. 16, no. 2, pp. 26–34.
Higgenbotham, James (1997). The Semantics of Questions. In S. Lappin (ed.): The Handbook of Contemporary Semantic Theory. Malden, MA: Blackwell Publishing.
Homeland Security (2010). Incident management handbook. U.S. Department of Homeland Security, January 2010.
Honeycutt, Courtenay and Susan C. Herring (2009). Beyond Microblogging: Conversation and Collaboration Via Twitter. In System Sciences, 2009. HICSS’09. 42nd Hawaii International Conference on System Sciences, Hawaii, 5–8 January 2009. The IEEE Computer Society Press, pp. 1–10.
Imran, Muhammad, Ioanna Lykourentzou, and Carlos Castillo (2013). Engineering Crowdsourced Stream Processing Systems. arXiv preprint arXiv:1310.5463. http://www.aphis.usda.gov/emergency_response/downloads/hazard/Incident%20Management%20Handbook6-09.pdf. Accessed 19 June 2014.
Isaacs, Ellen A. and Herbert H. Clark (1987). References in Conversation Between Experts and Novices. Journal of Experimental Psychology: General, vol. 116, pp. 26–37.
Jihan, Satria Hutomo and Aviv Segev (2013). Context Ontology for Humanitarian Assistance in Crisis Response. In T. Comes, F. Fiedrich, S. Fortier, J. Geldermann, and T. Müller (eds.): Proceedings of the 10th International ISCRAM Conference, Baden-Baden, Germany. Karlsruhe, Germany: KIT, pp. 526–535.
Keßler, Carsten, C. J. Hendrix, and Minu Limbu (2013). Humanitarian eXchange Language (HXL) Situation and Response Standard. Humanitarian Response, January 2013. http://hxl.humanitarianresponse.info/ns/index.html. Accessed 19 June 2014.
Latonero, Mark, and Irina Shklovski (2011). Emergency Management, Twitter, and Social Media Evangelism. International Journal of Information Systems for Crisis Response and Management (IJISCRAM), vol. 3, no.4, pp. 1–16.
Lave, Jean and Etienne Wenger (1991). Situated Learning. Legitimate Peripheral Participation. Cambridge: University of Cambridge Press.
Levin, Beth (1993). English Verb Classes and Alternations: A Preliminary Investigation, Conversation Analysis. Chicago, IL: The University of Chicago Press.
Limbu, Minu (2012): Management Of A Crisis (MOAC) Vocabulary Specification. ObservedChange, January 2012. http://observedchange.com/moac/ns/. Accessed 19 June 2014.
Livingston, Eric (1987). Making Sense of Ethnomethodology. London: Routledge & Kegan Paul, pp. 86–87.
Malone, Thomas W. and Kevin Crowston (1990). What is Coordination Theory and How Can it Help Design Cooperative Work Systems?. In Proceedings of the 1990 ACM conference on Computer-supported cooperative work, 7–10 October 1990, Los Angeles, CA. New York: ACM Press, pp. 357–370.
Mark, Gloria. (2002). Extreme Collaboration. Communications of the ACM, vol. 45, pp. 89–93.
Marz, Nathan (2011): Twitter’s Storm: Distributed Real-Time Computation System. The Apache Software Foundation, 2011. http://storm.incubator.apache.org/documentation/Home.html. Accessed 19 June 2014.
Mathioudakis, Michael and Nick Koudas (2010). Twittermonitor: Trend Detection over the Twitter Stream. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data,Indianapolis, IN, 6–11 June 2010. New York: ACM, pp. 1155–1158.
Myers, Lisa (2005): What Went Wrong in Katrina’s Wake?. NBC News Investigates, September 2005. http://www.nbcnews.com/id/9231926/ns/nbc_nightly_news_with_brian_williams-nbc_news_investigates/t/what-went-wrong-katrinas-wake/. Accessed 19 June 2014.
Nagarajan, Meenakshi, Karthik Gomadam, Amit P. Sheth, Ajith Ranabahu, Raghava Mutharaju, and Ashutosh Jadhav (2009). Spatio-Temporal-Thematic Analysis of Citizen-Sensor Data - Challenges and Experiences. In Proceedings from the Tenth International Conference on Web Information Systems Engineering, 5–7 October 2009. Berlin Heidelberg: Springer, pp. 539–553.
Palen, Leysia and Sophia B. Liu (2007). Citizen Communications in Crisis: Anticipating a Future of ICT-Supported Public Participation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 30 April – 3 May 2007, San Jose, CA. New York: ACM Press, pp. 727–736.
Palen, Leysia, Kenneth M. Anderson, Gloria Mark, James Martin, Douglas Sicker, Martha Palmer, and Dirk A. Grunwald (2010). Vision for Technology-Mediated Support for Public Participation & Assistance in Mass Emergencies & Disasters. In Proceedings of the 2010 ACM-BCS Visions of Computer Science Conference, 13–16 April 2010, Edinburgh, Scotland. Swinton, UK: British Computer Society, p. 8.
Pearson, Christine M. and Judith A. Clair (1998) Reframing Crisis Management. Academy of Management Review, vol. 23, no. 1, pp. 59–76.
Perng, Sung-Yueh, Monika Büscher, Ragnhild Halvorsrud, Lisa Wood, Michael Stiso, Leonardo Ramirez, and Amro Al-Akkad (2012). Peripheral Response: Microblogging During the 22/7/2011 Norway Attacks. In L. Rothkrantz, J. Ristvej, and Z. Franco (eds.): Proceedings from the 9th International Conference on Information Systems for Crisis Response Management (ISCRAM), Vancouver, Canada. 22–25 April 2012. Vancouver, Canada: Simon Fraser University.
Perrow, Charles (1984). Normal Accidents: Living with High-Risk Technologies. New York: Basic Books.
Pinker, Steven (2007). The Evolutionary Social Psychology of Off-Record Indirect Speech Acts. Intercultural Pragmatics, vol. 4, no. 4, pp. 437–461.
Pohl, Daniela, Abdelhamid Bouchachia, and Hermann Hellwagner (2012). Automatic Identification of Crisis-Related Subevents Using Clustering. In Proceedings of the 11th International Conference on Machine Learning and Applications (ICLMA), 12–15 December 2012, Boca Raton, FL. IEEE, pp. 333–383
Protégé (2013): Protégé: Ontology Editor and Knowledge-Base Framework. Stanford Center for Biomedical Informatics Research, Stanford University. http://protege.stanford.edu/. Accessed 30 March 2013.
Purohit, Hemant and Amit P. Sheth (2013a). Twitris v3: From Citizen Sensing to Analysis, Coordination and Action. In Proceedings of the Seventh International Conference on Weblogs and Social Media, 8–11 July 2013, Cambridge, MA. Palo Alto, CA: The AAAI Press, pp. 746–747.
Purohit, Hemant, Jitendra Ajmera, Sachindra Joshi, Ashish Verma, and Amit P. Sheth (2012). Finding Influential Authors in Brand-Page Communities. In Proceedings of the 6th AAAI International Conference on Weblogs and Social Media (ICWSM), 4–7 June 2012, Dublin, Ireland. Palo Alto, CA: AAAI Press, pp. 551–554.
Purohit, Hemant, Carlos Castillo, Patrick Meier, and Amit P. Sheth (2013b). Crisis Mapping, Citizen Sensing and Social Media Analytics: Leveraging Citizen Roles for Crisis Response. In Proceedings of the Seventh International Conference on Weblogs and Social Media, Cambridge, MA, 8–11 July 2013. Palo Alto, CA: The AAAI Press, p. xxiii.
Purohit, Hemant, Andrew Hampton, Valerie L. Shalin, Amit P. Sheth, John M. Flach, and Shreyansh Bhatt (2013c). What Kind of #Conversation is Twitter? Mining #Psycholinguistic Cues for Emergency Coordination. Computers in Human Behavior, vol. 29, no. 6, pp. 2438–2447.
Purohit, Hemant, Carlos Castillo, Fernando Diaz, Amit P. Sheth, and Patrick Meier (2014). Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers. First Monday, vol. 19, no. 1.
Quarantelli, Enrico Louis (1988). Disaster Crisis Management: A Summary of Research Findings. Journal of Management Studies, vol. 25, no. 4, pp. 373–385.
Quarantelli, Enrico Louis (2008). Conventional Beliefs and Counterintuitive Realities. Social Research, vol. 75, no. 3, pp. 873–904.
RDF Core Working Group (2004). Resource Description Framework (RDF) for Data Inter-Change on the Web. W3C, 25 February 2004. http://www.w3.org/RDF/. Accessed 24 June 2014.
Reuter, Christian, Oliver Heger and Volkmar Pipek (2013). Combining Real and Virtual Volunteers Through Social Media. In T. Comes, F. Fiedrich, S. Fortier, J. Gelderman, and T. Müller, (eds.): Proceedings of the 10th International ISCRAM Conference, Baden-Baden, Germany. Karlsruhe, Germany: KIT, pp. 780–790.
Schank, R. (1972) Conceptual Dependency: A Theory of Natural Language Understanding, Cognitive Psychology, vol. 3, pp. 552–631.
Schmidt, Kjeld and Liam Bannon (1992). Taking CSCW Seriously: Supporting Articulation Work. Computer Supported Cooperative Work (CSCW): An International Journal, vol. 1, nos. 1–2, March 1992 pp. 7–40.
Searle, John R. (1975). Indirect Speech Acts. In P. Cole & J. L. Morgan (eds.): Syntax and Semantics, 3: Speech Acts. New York: Academic Press, pp. 59–82.
Sheth, Amit P. (2009). Citizen Sensing, Social Signals, and Enriching Human Experience. IEEE Internet Computing, vol. 13, no. 4, July/August 2009, pp. 80–85.
Sheth, Amit P., Christopher Thomas, and Pankaj Mehra (2010). Continuous Semantics to Analyze Real-Time Data, IEEE Internet Computing, vol. 14, no. 6, pp. 84–89.
Sheth, Amit P., Ashutosh Sopan Jadhav, Pavan Kapanipathi, Lu Chen, Hemant Purohit, Alan Gary Smith, Wenbo Wang (in press). Twitris- A System for Collective Social Intelligence. In R. Alhajj and J. Rokne (eds): Encyclopedia of Social Network Analysis and Mining (ESNAM). USA: Springer Reference.
Sicker, Douglas C., Dirk Grunwald, Lisa Blumensaadt, Leysia Palen, and Kenneth M. Anderson (2010). Policy Issues Facing the Use of Social Network Information During Times of Crisis. The 38th Annual Telecommunications Policy Research Conference (TPRC) for Public Safety and Emergency session, Arlington, Virginia, 1–3 October 2010.
Simon, Herbert A. (1962). The Architecture of Complexity. Springer US. pp. 457–476.
Smith, Alan Gary, Amit P. Sheth, Ashutosh Sopan Jadhav, Hemant Purohit, Lu Chen, Michael Cooney, Pavan Kapanipathi, Pramod Anantharam, Pramod Koneru, and Wenbo Wang (2012). Twitris+: Social Media Analytics Platform for Effective Coordination. In the NSF Social Computational Systems (SoCS) Symposium, Ann Arbor, MI, 16–18 July 2012.
Star, Susan Leigh and James R. Griesemer (1989). Institutional Ecology, ‘Translations’ and Boundary Objects: Amateurs and Professionals in Berkeley’s Museum of Vertebrate Zoology, 1907–39. Social Studies of Science, vol. 19, no. 3, pp. 387–420.
Starbird, Kate (2011). Digital Volunteerism during Disaster : Crowdsourcing Information Processing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011. New York: ACM Publications, pp. 1071–1080.
Starbird, Kate and Jeannie Stamberger (2010). Tweak the Tweet: Leveraging Microblogging Proliferation with a Prescriptive Grammar to Support Citizen Reporting. In S. French, B. Tomaszewski, and C. Zobel (eds.): The 7th International Information Systems for Crisis Response and Management Conference, Seattle, WA, USA, May 2010. USA: bvdwalle.
Starbird, Kate, Leysia Palen, Amanda L. Hughes, and Sarah Vieweg (2010). Chatter on the Red: What Hazards Threat Reveals about the Social Life of Microblogged Information. In Proceedings of the ACM 2010 Conference on Computer Supported Cooperative Work (CSCW), Savannah, GA. New York: ACM Press, pp. 241–250.
Starbird, Kate and Leysia Palen (2010). Pass It On?: Retweeting in Mass Emergencies. In S. French, B. Tomaszewski, and C. Zobel (eds.): The 7th International Information Systems for Crisis Response and Management Conference, Seattle, WA, USA, May 2010. USA: bvdwalle.
Starbird, Kate, Grace Muzny, and Leysia Palen (2012). Learning from the Crowd : Collaborative Filtering Techniques for Identifying On-the-Ground Twitterers during Mass Disruptions. In L. Rothkrantz, J. Ristvej, and Z. Frenco (eds.): Proceedings from the 9th International Conference on Information Systems for Crisis Response Management (ISCRAM), Vancouver, Canada, 22–24 April 2012. Vancouver, Canada: Simon Fraser University.
Swienton, Raymond E. and Italo Subbarao (eds.) (2012). Basic Disaster Life Support, Course Manual (3rd Ed.). USA: American Medical Association.
Tsukayama, Hayley (2014): Twitter Turns 7: Users Send over 400 Million Tweets Per Day. The Washington Post, 21 March 2013. http://articles.washingtonpost.com/2013-03-21/business/37889387_1_tweets-jack-dorsey-twitter. Accessed 19 June 2014.
Twitter Developer (2013): REST API Rate Limiting in v1.1. Twitter, 15 March 2013. https://dev.twitter.com/docs/rate-limiting/1.1. Accessed 24 June 2013.
Varga, István, Motoki Sano, Kentaro Torisawa, Chikara Hashimoto, Kiyonori Ohtake, Takao Kawai, Jong-Hoon Oh, and Stijn De Saeger (2013). Aid is Out There: Looking for Help from Tweets during a Large Scale Disaster. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013. Red Hook, NY: Curran Associates, Inc., vol. 1, pp. 1619–1629.
Verity, Andrej (ed.) (2011): OCHA: Lessons Learned Report on the Collaboration with Volunteer and Technical Community in Libya and Japan. Digital Humanitarian Network, November 2011. http://digitalhumanitarians.com/sites/default/files/resource-field_media/OCHALessonsLearnedCollaborationwithVTCsinLibyaandJapanFinalNov2011.pdf. Accessed 23 June 2014.
Vieweg, Sarah, Amanda L. Hughes, Kate Starbird, and Leysia Palen (2010). Microblogging during Two Natural Hazards Events : What Twitter May Contribute to Situational Awareness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, 10–15 April 2010. New York: ACM Press, pp. 1079–1088.
Weick, Karl E. (1988). Enacted Sensemaking in Crisis Situations. Journal of management studies, vol. 25, no. 4, 305–317.
Acknowledgments
This work is supported by the NSF (IIS-1111182, 09/01/2011 - 08/31/2014) SoCS program. We thank the NSF for their generous support, our colleagues for the valuable comments on the draft and preliminary discussion about designing a coordination analysis framework, James Gruenberg from Wright State’s Calamityville for valuable insight into disaster management, and research assistants, especially Dylan Clericus (undergraduate), Meagan Newman, and Harry Abramovitz.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Purohit, H., Hampton, A., Bhatt, S. et al. Identifying Seekers and Suppliers in Social Media Communities to Support Crisis Coordination. Comput Supported Coop Work 23, 513–545 (2014). https://doi.org/10.1007/s10606-014-9209-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10606-014-9209-y