
Abstract
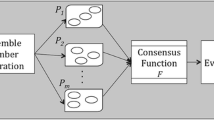
Cluster ensemble aims at producing high quality data partitions by combining a set of different partitions produced from the same data. Diversity and quality are claimed to be critical for the selection of the partitions to be combined. To enhance these characteristics, methods can be applied to evaluate and select a subset of the partitions that provide ensemble results similar or better than those based on the full set of partitions. Previous studies have shown that this selection can significantly improve the quality of the final partitions. For such, an appropriate evaluation of the candidate partitions to be combined must be performed. In this work, several methods to evaluate and select partitions are investigated, most of them based on relative clustering validity indexes. These indexes select the partitions with the highest quality to participate in the ensemble. However, each relative index can be more suitable for particular data conformations. Thus, distinct relative indexes are combined to create a final evaluation that tends to be robust to changes in the application scenario, as the majority of the combined indexes may compensate the poor performance of some individual indexes. We also investigate the impact of the diversity among partitions used for the ensemble. A comparative evaluation of results obtained from an extensive collection of experiments involving state-of-the-art methods and statistical tests is presented. Based on the obtained results, a practical design approach is proposed to support cluster ensemble selection. This approach was successfully applied to real public domain data sets.
Similar content being viewed by others


References
Aeberhard S, Coomans D, de Vel O (1992) Comparison of classifiers in high dimensional settings. Tech Rep 02, Department of Computer Science and Department of Mathematics and Statistics, James Cook University of North Queensland, Douglas
Alcock R, Manolopoulos Y (1999) Time-series similarity queries employing a feature-based approach. In: 7th hellenic conference on informatics, Ioannina, Greece, pp 27–29
Asuncion A, Newman D (2007) UCI machine learning repository. http://www.ics.uci.edu/~mlearn/MLRepository.html
Ayad HG, Kamel MS (2008) Cumulative voting consensus method for partitions with variable number of clusters. IEEE Trans Pattern Anal Mach Intell 30(1):160–173. doi:10.1109/TPAMI.2007.1138
Azimi J, Fern X (2009) Adaptive cluster ensemble selection. In: Twenty-first international joint conference on artificial intelligence (IJCAI-09), Pasadena, CA, USA, pp 992–997
Bezdek JC, Pal NR (1998) Some new indexes of cluster validity. IEEE Trans Syst Man Cybern 28(3): 301–315
Bollacker KD, Ghosh J (1998) A supra-classifier architecture for scalable knowledge reuse. In: ICML ’98: Proceedings of the fifteenth international conference on machine learning. Morgan Kaufmann Publishers Inc., San Francisco, pp 64–72
Calinski RB, Harabasz J (1974) A dendrite method for cluster analysis. Commun Stat 3: 1–27
Caruana R, Munson A, Niculescu-Mizil A (2006) Getting the most out of ensemble selection. In: Proceedings of the 2006 sixth international conference on data mining, pp 828–833
Davies DL, Bouldin DW (1979) A cluster separation measure. IEEE Trans Pattern Anal Mach Intell 1: 224–227
Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7: 1–30
Dimitriadou E (2003) Explorative data analysis and applications. PhD thesis, Technische Universität Wien, Wien
Dimitriadou E, Weingessel A, Hornik K (1999) Fuzzy voting in clustering. In: Brewka G, Der R, Gottwald S, Schierwagen A (eds) Fuzzy-neuro systems. Leipziger Universittsverlag, Leipzig, pp 63–74
Dudoit S, Fridlyand J (2003) Bagging to improve the accuracy of a clustering procedure. Bioinformatics 19(9): 1090–1099
Dunn JC (1974) Well separated clusters and optimal fuzzy partitions. J Cybern 4: 95–104
Dunn OJ (1961) Multiple comparisons among means. J Am Stat Assoc 56(293):52–64. http://www.jstor.org/stable/2282330
Fern XZ, Brodley CE (2004) Solving cluster ensemble problems by bipartite graph partitioning. In: Proceedings of ICML’04, New York, NY, USA, p 36. doi:10.1145/1015330.1015414
Fern XZ, Lin W (2008) Cluster ensemble selection. J Stat Anal Data Min 1(3): 128–141. doi:10.1002/sam.v1:3
Fisher R (1936) The use of multiple measurements in taxonomic problems. Ann Eugen 7(2): 179–188
Fred ALN, Jain AK (2005) Combining multiple clusterings using evidence accumulation. IEEE Trans Pattern Anal Mach Intell 27(6): 835–850
Greene D, Tsymbal A, Bolshakova N, Cunningham P (2004) Ensemble clustering in medical diagnostics. In: CBMS ’04: proceedings of the 17th IEEE symposium on computer-based medical systems. IEEE Computer Society, Washington, DC, USA, pp 576–581. http://dx.doi.org/10.1109/CBMS.2004.40
Hadjitodorov ST, Kuncheva LI (2007) Selecting diversifying heuristics for cluster ensembles. In: 7th international workshop, pp 200–209
Hadjitodorov ST, Kuncheva LI, Todorova LP (2006) Moderate diversity for better cluster ensembles. Inf Fusion 7(3): 264–275. doi:10.1016/j.inffus.2005.01.008
Halkidi M, Batistakis Y, Vazirgiannis M (2001) On clustering validation techniques. Intell Inf Syst J 17(2-3): 107–145
Handl J, Knowles J (2007) An evolutionary approach to multiobjective clustering. IEEE Trans Evolution Comput 11(1): 56–76
Hochberg Y, Tamhane AC (1987) Multiple comparison procedures. Wiley, New York
Hollander M, Wolfe DA (1999) Nonparametric statistical methods. Wiley-Interscience, New York
Hruschka ER, Campello RJGB, de Castro LN (2004a) Evolutionary algorithms for clustering gene-expression data. In: Proceedings of IEEE international conference on data mining, Brighton/England, pp 403–406
Hruschka ER, Campello RJGB, de Castro LN (2004b) Improving the efficiency of a clustering genetic algorithm. In: Advances in artificial intelligence—IBERAMIA 2004: 9th Ibero-American conference on AI, Puebla, Mexico, November 22–25. Proceedings. Lecture notes in computer science, vol 3315. Springer, New York, pp 861–870
Hubert LJ, Arabie P (1985) Comparing partitions. J Classif 2: 193–218
Jaccard P (1908) Nouvelles recherches sur la distribution florale. Bull Soc Vandoise des Sci Nat 44: 223–270
Jain A, Dubes R (1988) Algorithms for clustering data. Prentice Hall, Upper Saddle River
Karypis G, Kumar V (1999) A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J Sci Comput 20(1):359–392. http://glaros.dtc.umn.edu/gkhome/metis/metis/overview
Kasturi J, Acharya R (2004) Clustering of diverse genomic data using information fusion. In: SAC ’04: proceedings of the 2004 ACM symposium on applied computing. ACM, New York, pp 116–120. doi:http://doi.acm.org/10.1145/967900.967926
Kaufman L, Rousseeuw P (1990) Finding groups in data: an introduction to cluster analysis Wiley series in probability and mathematical statistics. John Wiley & Sons, New York
Kuncheva LI (2004) Combining pattern classifiers. John Wiley & Sons, New York
Kuncheva L, Hadjitodorov S (2004) Using diversity in cluster ensembles. In: Systems, man and cybernetics, 2004 IEEE international conference on, vol 2, pp 1214–1219 10.1109/ICSMC.2004.1399790
Kuncheva L, Hadjitodorov S, Todorova L (2006) Experimental comparison of cluster ensemble methods. In: Information fusion, 2006 9th international conference on, pp 1–7. doi:10.1109/ICIF.2006.301614
Mangasarian OL, Wolberg WH (1990) Cancer diagnosis via linear programming. SIAM News 23(5): 1–18
Margineantu D, Dietterich T (1997) Pruning adaptive boosting. In: Proceedings of the 14th international conference on machine learning, pp 211–218
Milligan GW, Cooper MC (1985) An examination of procedures for determining the number of clusters in a data set. Psychometrika 50: 159–179
Monti S, Tamayo P, Mesirov J, Golub T (2003) Consensus clustering: a resampling-based method for class discovery and visualization of gene expression microarray data. Mach Learn 52(1-2): 91–118
Naldi MC, Campello RJGB, Hruschka ER, Carvalho ACPLF (2011) Efficiency issues of evolutionary k-means. Appl Soft Comput 11(2): 1938–1952. doi:10.1016/j.asoc.2010.06.010
Ng AY, Jordan MI, Weiss Y (2002) On spectral clustering: analysis and an algorithm. In: Advances in neural information processing systems, vol 2, pp 849–856
Pakhira MK, Bandyopadhyay S, Maulik U (2004) Validity index for crisp and fuzzy clusters. Pattern Recog 37(3):487–501, doi:10.1016/j.patcog.2003.06.005, http://www.sciencedirect.com/science/article/B6V14-49YH94Y-3/2/399727cea74b53ae0b747d5f73922009
Paulovich FV, Nonato LG, Minghim R, Levkowitz H (2008) Least square projection: a fast high-precision multidimensional projection technique and its application to document mapping. IEEE Trans Visual Comput Graph 14:564–575. doi:10.1109/TVCG.2007.70443, www.lcad.icmc.usp.br/~paulovic/pex/repository/data.zip
Rousseeuw PJ (1987) Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J Computat Appl Math 20: 53–65
Strehl A, Ghosh J (2002) Cluster ensembles: a knowledge reuse framework for combining multiple partitions. J Mach Learn Res 3: 583–617
Topchy A, Jain A, Punch W (2004) A mixture model for clustering ensembles. In: Proceedings of the SIAM international conference on data mining (SDM’2004), Lake Buena Vista, Florida, USA, pp 331–338
Tumer K, Agogino AK (2008) Ensemble clustering with voting active clusters. Pattern RecognL ett 29(14): 1947–1953. doi:10.1016/j.patrec.2008.06.011
Vendramin L, Campello RJGB, Hruschka ER (2009) On the comparison of relative clustering validity criteria. In: SIAM international conference on data mining, Sparks/USA, pp 733–744
Vendramin L, Campello RJGB, Hruschka ER (2010) Relative clustering validity criteria: a comparative overview. Stat Anal Data Min 3(4): 209–235. doi:10.1002/sam.10080
Walpole RE, Myers R, Myers SL (2006) Probability and statistics for engineers and scientists. Macmillan, New York
Weingessel A, Dimitriadou E, Hornik K (2003) An ensemble method for clustering. In: Distributed statistical computing (DSC’2003), Wien, Austria, pp 1–12
Yeung K, Medvedovic M, Bumgarner R (2003) Clustering gene-expression data with repeated measurements. Genome Biol 4(5):R34. doi:10.1186/gb-2003-4-5-r34, http://genomebiology.com/2003/4/5/R34
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Charu Aggarwal.
Rights and permissions
About this article
Cite this article
Naldi, M.C., Carvalho, A.C.P.L.F. & Campello, R.J.G.B. Cluster ensemble selection based on relative validity indexes. Data Min Knowl Disc 27, 259–289 (2013). https://doi.org/10.1007/s10618-012-0290-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-012-0290-x