
Abstract
The process of integrating large volumes of data coming from disparate data sources, in order to detect records that refer to the same entities, has always been an important problem in both academia and industry. This problem becomes significantly more challenging when the integration involves a huge amount of records and needs to be conducted in a real-time fashion to address the requirements of critical applications. In this paper, we propose two novel schemes for online record linkage, which achieve very fast response times and high levels of recall and precision. Our proposed schemes embed the records into a Bloom filter space and employ the Hamming Locality-Sensitive Hashing technique for blocking. Each Bloom filter is hashed to a number of hash tables in order to amplify the probability of formulating similar Bloom filter pairs. The main theoretical premise behind our first scheme relies on the number of times a Bloom filter pair is formulated in the hash tables of the blocking mechanism. We prove that this number strongly depends on the distance of that Bloom filter pair. This correlation allows us to estimate in real-time the Hamming distances of Bloom filter pairs without performing the comparisons. The second scheme is progressive and achieves high recall, upfront during the linkage process, by continuously adjusting the sequence in which the hash tables are scanned, and also guarantees, with high probability, the identification of each similar Bloom filter pair. Our experimental evaluation, using four real-world data sets, shows that the proposed schemes outperform four state-of-the-art methods by achieving higher recall and precision, while being very efficient.









Similar content being viewed by others


Notes
LSH-based collision counting has also been studied in Karapiperis and Verykios (2016) under a different focus and theoretical development. Specifically, the method therein provides guarantees for a matching pair in achieving the required number of collisions.
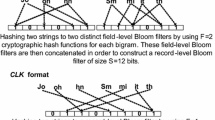
A \(\lambda \)-gram is a substring genarated by sliding a window of length \(\lambda \) over the characters of a string value.
The Hamming distance between two Bloom filters is equal to the number of components in which these Bloom filters differ.
A z-score is the number of standard deviations that an element lies from the mean value.
The value of L for P-RDS is a function of k and \(\vartheta \) as discussed in Sect. 3.2
The resolution of a bucket involves performing the distance computations of the pairs stored therein, and then classifying those pairs as matching or non-matching.
The value of k should be sufficiently large because otherwise a small number of buckets is generated in each \(T_{l}\), which are overpopulated by Bloom filters resulting in the formulation of mostly dissimilar pairs.
The Jaro-Winkler similarity result between ‘TAMPA’ and ‘TEMPA’ is 0.88, while between ‘LOS ANGELES’ and ‘LOS ANGALES’ is 0.98.
LSHDB can be found at https://github.com/dimkar121/LSHDB. Test data sets have been uploaded at https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/JKBULA.
Using Double Metaphone encoding, ‘SMITH’ and ‘SMYTH’ are encoded both as ‘SM0’.
We exclude redundant distance computations by using a Bloom filter, which implements a very fast bounded-memory buffer.
We perform logical XOR operations between the Bloom filters.
References
Altwaijry H, Kalashnikov D, Mehrotra S (2013) Query-driven approach to entity resolution. Int Conf Very Large Data Bases (PVLDB) 6:1846–1857
Andoni A, Indyk P (2008) Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Commun ACM (CACM) 51(1):117–122
Bhattacharya I, Getoor L Licamele L (2006) Query-time entity resolution. In: International conference on knowledge discovery and data mining (KDD), pp 529–534
Bilenko M, Kamath B, Mooney RJ (2006) Adaptive blocking: learning to scale up record linkage. In: International conference on data mining (ICDM), pp 87–96
Christen P (2012) A survey of indexing techniques for scalable record linkage and deduplication. Trans Knowl Data Eng (TKDE) 12(9):1537–1555
Christen P, Gayler R, Hawking D (2009) Similarity—aware indexing for real-time entity resolution. In: International conference on information and knowledge management (CIKM), pp 1565–1568
Cohen WW, Richman J (2002) Learning to match and cluster large high-dimensional data sets for data integration. In: International conference on knowledge discovery and data mining (SIGKDD), pp 475–480
Dey D, Mookerjee V, Liu D (2011) Efficient techniques for online record linkage. Trans Knowl Data Eng (TKDE) 23(3):373–387
Elmagarmid A, Ipeirotis P, Verykios V (2007) Duplicate record detection: a survey. Trans Knowl Data Eng (TKDE) 19(1):1–16
Firmani D, Saha B, Srivastava D (2016) Online entity resolution using an oracle. Int Conf Very Large Data Bases (PVLDB) 9:384–395
Hernandez MA, Stolfo SJ (1995) The merge/purge problem for large databases. In: International conference on management of data (SIGMOD), pp 127–138
Ioannou E, Nejdl W, Niederee C, Velegrakis Y (2010) On-the-fly entity-aware query processing in the presence of linkage. Int Conf Very Large Data Bases (PVLDB) 3(1):429–438
Karapiperis D, Verykios VS (2015) An LSH-based blocking approach with a homomorphic matching technique for privacy-preserving record linkage. Trans Knowl Data Eng (TKDE) 27(4):909–921
Karapiperis D, Verykios VS (2016) A fast and efficient Hamming LSH-based scheme for accurate linkage. Knowl Inf Syst (KAIS) 49(3):861–884
Karapiperis D, Gkoulalas-Divanis A, Verykios VS (2016a) LSHDB: a parallel and distributed engine for record linkage and similarity search. In: International conference on data mining (ICDM) demos, pp 1–4
Karapiperis D, Vatsalan D, Verykios VS, Christen P (2016b) Efficient record linakge using a compact Hamming space. In: International conference on extending database technology (EDBT), pp 209–220
Kim H, Lee D (2010) Fast iterative hashed record linkage for large-scale data collections. In: International conference on extending database technology (EDBT), pp 525 – 536
Papenbrock T, Heise A, Naumann F (2015) Progressive duplicate detection. Trans Knowl Data Eng (TKDE) 27(5):1316–1329
Schnell R, Bachteler T, Reiher J (2009) Privacy-preserving record linkage using Bloom filters. Med Inform Decis Mak (BMC) 9:41
Shrivastava A, Li P (2014) Improved densification of one permutation hashing. In: International conference on uncertainty in artificial intelligence (UAI), pp 732–741
Steorts R, Ventura S, Sadinle M, Fienberg S (2014) A comparison of blocking methods for record linkage. In: Privacy in statistical databases (PSD), pp 253–268
Whang SE, Menestrina D, Koutrika G, Theobald M, Garcia-Molina H (2009) Entity resolution with iterative blocking. In: SIGMOD, pp 219–232
Whang SE, Marmaros D, Garcia-Molina H (2013) Pay-as-you-go entity resolution. Trans Knowl Data Eng (TKDE) 25(5):1111–1124
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Kurt Driessens, Dragi Kocev, Marko Robnik-Šikonja, Myra Spiliopoulou.
Rights and permissions
About this article

Cite this article
Karapiperis, D., Gkoulalas-Divanis, A. & Verykios, V.S. Fast schemes for online record linkage. Data Min Knowl Disc 32, 1229–1250 (2018). https://doi.org/10.1007/s10618-018-0563-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-018-0563-0