
Abstract
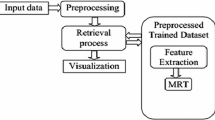
Storing as well as retrieving the data on a specific time frame is fundamental for any application today. So an efficiently designed query permits the user to get results in the desired time and creates credibility for the corresponding application. To avoid the difficulty in query optimization, this paper proposed an improved query optimization process in big data (BD) using the ACO-GA algorithm and HDFS map-reduce. The proposed methodology consists of ‘2’ phases, namely, BD arrangement and query optimization phases. In the first phase, the input data is pre-processed by finding the hash value (HV) using the SHA-512 algorithm and the removal of repeated data using the HDFS map-reduce function. Then, features such as closed frequent pattern, support, and confidence are extracted. Next, the support and confidence are managed by using the entropy calculation. Centered on the entropy calculation, the related information is grouped by using Normalized K-Means (NKM) algorithm. In the 2nd phase, the BD queries are collected, and then the same features are extorted. Next, the optimized query is found by utilizing the ACO-GA algorithm. Finally, the similarity assessment process is performed. The experimental outcomes illustrate that the algorithm outperformed other existent algorithms.







Similar content being viewed by others

References
Rawat, J.S., Kishor, S., Kumari, M.: A survey on query optimization in cloud computing. Int J Adv Technol Eng Sci 4(10), 2348 (2016)
Gu, R., Yang, X., Yan, J., Sun, Y., Wang, B., Yuan, C., Huang, Y.: SHadoop: improving mapreduce performance by optimizing job execution mechanism in hadoop clusters. J Parallel Distrib Comput. 74(3), 2166–2179 (2014)
J Wolf, D Rajan, K Hildrum, R Khandekar, V Kumar, S Parekh, and KL Wu 2010, “Flex: A slot allocation scheduling optimizer for mapreduce workloads”, In Proceedings of the ACM/IFIP/USENIX 11th International Conference on Middleware, Springer-Verlag, pp. 1-20
Barba-González, C., García-Nieto, J., Nebro, A.J., Cordero, J.A., Durillo, J.J., Navas-Delgado, I., Aldana-Montes, J.F.: jMetalSP: a framework for dynamic multi-objective big data optimization. Applied Soft Computing 69, 737–748 (2018)
Song, J., Ma, Z., Thomas, R., Ge, Yu.: Energy efficiency optimization in big data processing platform by improving resources utilization. Sustainable Computing: Informatics and Systems 21, 80–89 (2019)
Mahajan, D., Blakeney, C., Zong, Z.: Improving the energy efficiency of relational and NoSQL databases via query optimizations. Sustainable Computing: Informatics and Systems 22, 120–133 (2019)
Rini John, and Nikita Palaskar, “A survey of various query optimization techniques”, International Journal of Computer Applications, vol. 975, pp. 8887
Roy, C., Pandey, M., Rautaray, S.S.: A proposal for optimization of data node by horizontal scaling of name node using big data tools. In: Proceedings of the 3rd International Conference for Convergence in Technology (I2CT), IEEE, pp. 1–6 (2018)
Dwivedi, J., Tiwary, A.: Big data analytics: an overview. Int. J. Sci. Technol. Res. 5(07) (2016)
Regita Thangam, A., John Peter, S.: An extensive survey on various query optimization techniques. IJCSMC 5, 148–154 (2016)
Armbrust, M., Xin, R.S., Lian, C., Huai, Y., Liu, D., Bradley, J.K., Meng, X. et al: Spark sql: relational data processing in spark. In: Proceedings of the ACM SIGMOD international conference on management of data, ACM, pp. 1383–1394 (2015)
Zhou, J., Bruno, N., Ming-Chuan, W., Larson, P.-A., Chaiken, R., Shakib, D.: SCOPE: parallel databases meet MapReduce. VLDB J. 21(5), 611–636 (2012)
Vavilapalli, V.K., Murthy, A.C., Douglas, C., Agarwal, S., Konar, M., Evans, R., Graves, T. et al.: Apache hadoop yarn: yet another resource negotiator. In: Proceedings of the 4th annual Symposium on Cloud Computing, ACM, pp. 5 (2013)
Boutin, E., Ekanayake, J., Lin, W., Shi, B., Zhou, J., Qian, Z., Wu, M., Zhou, L.: Apollo: scalable and coordinated scheduling for cloud-scale computing., In: Proceedings of the 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14), pp. 285–300 (2014)
Zaharia, M., Chowdhury, M., Franklin, M.J., Shenker, S., Stoica, I.: Spark: cluster computing with working sets. HotCloud 10(10–10), 95 (2010)
Sahal, R., Khafagy, M.H., Omara, F.A.: Exploiting coarse-grained reused-based opportunities in Big Data multi-query optimization. J. Comput. Sci. 26, 432–452 (2018)
Ghazi, M.R., Gangodkar, D.: Hadoop, MapReduce and HDFS: a developers perspective. Proc. Comput. Sci. 48, 45–50 (2015)
Li, Y., Wang, H., Li, Y.: Research on query analysis and optimization based on spark. In: Proceedings of the 6th International Conference on Computer Science and Network Technology (ICCSNT), IEEE, pp. 251–255 (2017)
Armbrust, M., Das, T., Davidson, A., Ghodsi, A., Or, A., Rosen, J., Stoica, I., Wendell, P., Xin, R., Zaharia, M.: Scaling spark in the real world: performance and usability. Proc. VLDB Endow. 8(12), 1840–1843 (2015)
Sahal, R., Nihad, M., Khafagy, M.H., Omara, F.A.: iHOME: index-based join query optimization for limited big data storage. J. Grid Comput. 16(2), 345–380 (2018)
Joshi, M., Srivastava, P.R.: Query optimization: an intelligent hybrid approach using cuckoo and tabu search. Int. J. Intell. Inf. Technol. (IJIIT) 9(1), 40–55 (2013)
Guo, B., Jiong, Yu., Liao, B., Yang, D., Liang, L.: A green framework for DBMS based on energy-aware query optimization and energy-efficient query processing. J. Netw. Comput. Appl. 84, 118–130 (2017)
Li, J., Xia, X., Liu, X., Wang, B., Zhou, D., An, Y.: Probabilistic group nearest neighbor query optimization based on classification using ELM. Neurocomputing 277, 21–28 (2018)
Zhang, B., Wang, X., Zheng, Z.: The optimization for recurring queries in big data analysis system with MapReduce. Future Gener. Comput. Syst. 87, 549–556 (2018)
Jafarinejad, M., Amini, M.: Multi-join query optimization in bucket-based encrypted databases using an enhanced ant colony optimization algorithm. Distrib. Parallel Databases 36(2), 399–441 (2018)
Bao, C., Cao, M.: Query optimization of massive social network data based on hbase. In: Proceedings of the IEEE 4th International Conference on Big Data Analytics (ICBDA), pp. 94–97 (2019)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kumar, D., Jha, V.K. An improved query optimization process in big data using ACO-GA algorithm and HDFS map reduce technique. Distrib Parallel Databases 39, 79–96 (2021). https://doi.org/10.1007/s10619-020-07285-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10619-020-07285-z