
Abstract
In this paper, we present YuruBackup, a space-efficient and highly scalable incremental backup system in the cloud. YuruBackup enables fine-grained data de-duplication with hierarchical partitioning to improve space efficiency to reduce bandwidth of both backup and restore processes, and storage costs. On the other hand, YuruBackup explores a highly scalable architecture for fingerprint servers that allows to add one or more fingerprint servers dynamically to cope with increasing clients. In this architecture, the fingerprint servers in a DB cluster are used for scaling writes of fingerprint catalog, while the slaves are used for scaling reads of fingerprint catalog. We present the system architecture of YuruBackup and its components, and we have implemented a proof-of-concept prototype of YuruBackup. By conducting performance evaluation in a public cloud, experimental results demonstrate the efficiency of the system.












Similar content being viewed by others

Notes
The source code of the customized Cloudstone is available on http://code.google.com/p/clouddb-replication/.
Uploading/downloading a file to S3 is an I/O operation.
Fig. 12 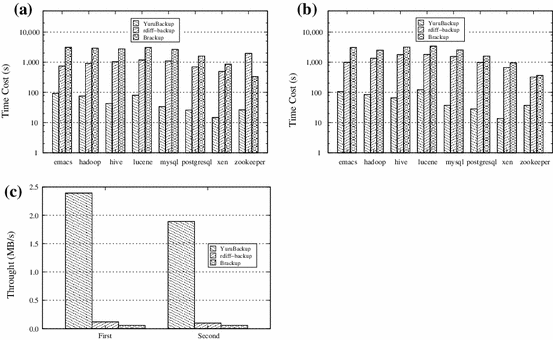
Restore performance comparison in a public cloud (AWS). a First incremental restore. b Second incremental restore. c Restore throughput

References
Agrawal, N., Bolosky, W.J., Douceur, J.R., Lorch, J.R.: A five-year study of file-system metadata. In: FAST, pp. 31–45 (2007)
Asigra: Asigra cloud backup and recovery software. White Paper (2012)
Cao, Y., Chen, C., Guo, F., Jiang, D., Lin, Y., Ooi, B.C., Vo, H.T., Wu, S., Xu, Q.: Es\(^{2}\): A cloud data storage system for supporting both oltp and olap. In: ICDE, pp. 291–302 (2011)
Dubnicki, C., Gryz, L., Heldt, L., Kaczmarczyk, M., Kilian, W., Strzelczak, P., Szczepkowski, J., Ungureanu, C., Welnicki, M.: Hydrastor: A scalable secondary storage. In: FAST, pp. 197–210 (2009)
EMC: Efficient data protection with emc avamar global deduplication software. White Paper (2010)
Fitzpatrick, B.: Brackup (2010). http://code.google.com/p/brackup/
Guo, F., Efstathopoulos, P.: Building a high-performance deduplication system. In: USENIX Annual Technical Conference (2011)
Lillibridge, M., Eshghi, K., Bhagwat, D.: Improving restore speed for backup systems that use inline chunk-based deduplication. In: FAST, pp. 183–197 (2013)
Merrill, D.R.: Four principles for reducing total cost of ownership. four-principles-for-reducing-total-cost-of-ownership.pdf (2011). http://www.hds.com/assets/pdf/
Meyer, D.T., Bolosky, W.J.: A study of practical deduplication. In: FAST, pp. 1–13 (2011)
Mitzenmacher, M.: Compressed bloom filters. In: PODC, pp. 144–150 (2001)
Muthitacharoen, A., Chen, B., Mazières, D.: A low-bandwidth network file system. In: SOSP, pp. 174–187 (2001)
Policroniades, C., Pratt, I.: Alternatives for detecting redundancy in storage systems data. In: USENIX Annual Technical Conference, General Track, pp. 73–86 (2004)
Rabin, M.O.: Fingerprinting by random polynomials. Tech. Rep. Technical Report TR-15-81, Center for Research in Computing Technology, Harvard University, MA (1981)
Rdiff-backup (2009). http://www.nongnu.org/rdiff-backup/
Sobel, W., Subramanyam, S., Sucharitakul, A., Nguyen, J., Wong, H., Patil, S., Fox, A., Patterson, D.: Cloudstone: multi-platform, multi-language benchmark and measurement tools for web 2.0. In: CCA (2008)
Srinivasan, K., Bisson, T., Goodson, G., Voruganti, K.: idedup: latency-aware, inline data deduplication for primary storage. In: FAST (2012)
Strzelczak, P., Adamczyk, E., Herman-Izycka, U., Sakowicz, J., Slusarczyk, L., Wrona, J., Dubnicki, C.: Concurrent deletion in a distributed content-addressable storage system with global deduplication. In: FAST, pp. 161–174 (2013)
Symantec: Symantec netbackup appliances: Key considerations in modernizing your backup and deduplication solutions. White Paper (2011)
Tan, Y., Jiang, H., Feng, D., Tian, L., Yan, Z.: Cabdedupe: A causality-based deduplication performance booster for cloud backup services. In: IPDPS, pp. 1266–1277 (2011)
Tridgell, A., Mackerras, P.: The rsync algorithm. Tech. Rep. TR-CS-96-05, Department of Computer Science, The Australian National University, Canberra (1996)
Vrable, M., Savage, S., Voelker, G.M.: Cumulus: filesystem backup to the cloud. In: FAST, pp. 225–238 (2009)
Xia, W., Jiang, H., Feng, D., Hua, Y.: Silo: A similarity-locality based near-exact deduplication scheme with low ram overhead and high throughput. In USENIX Annual Technical Conference (2011)
Xu, Q., Arumugam, R.V., Yong, K.L., Mahadevan, S.: Drop: Facilitating distributed metadata management in eb-scale storage systems. In: MSST (2013)
Xu, Q., Hou, X., Cui, B., Shen, H.T., Dai, Y.: Facilitating effective resource publishing and searching in dht networks. HKIE Trans. 16(3), 32–41 (2009a)
Xu, Q., Shen, H.T., Chen, Z., Cui, B., Zhou, X., Dai, Y.: Hybrid information retrieval policies based on cooperative cache in mobile p2p networks. Front. Comput. Sci. China 3(3), 381–395 (2009b)
You, L., Pollack, K.T., Long, D.D.E.: Deep store: an archival storage system architecture. In: ICDE, pp. 804–815 (2005)
Zhu, B., Li, K., Patterson, R.H.: Avoiding the disk bottleneck in the data domain deduplication file system. In: FAST, pp. 269–282 (2008)
Acknowledgments
We would like to thank Alan Fekete at the University of Sydney, Yong Khai Leong, Khin Mi Mi Aung and Rajesh Vellore Arumugam at Data Storage Institute, A*STAR for their help, and the anonymous reviewers for their suggestions. This work is supported by the National Basic Research Program of China (973) under Grant. 2011CB302305, and National Science Foundation of China under Grant No. 61073015. NICTA is funded by the Australian Government through the Department of Communications and the Australian Research Council through the ICT Centre of Excellence Program.
Author information
Authors and Affiliations
Corresponding author
Additional information
Yuru means cloud in Australian aboriginal language.
Q. Xu: The work was mostly done while the author was with NICTA and visiting Peking University.
Rights and permissions
About this article
Cite this article
Xu, Q., Zhao, L., Xiao, M. et al. YuruBackup: A Space-Efficient and Highly Scalable Incremental Backup System in the Cloud. Int J Parallel Prog 43, 316–338 (2015). https://doi.org/10.1007/s10766-013-0280-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10766-013-0280-7