
Abstract
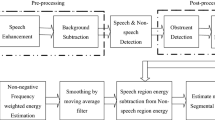
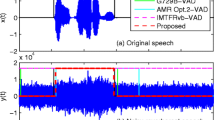
The performance of any speech based systems depends on the quality of input speech signals. The signal to noise ratio (SNR) is considered to be a measure of the quality of speech signal. This paper reports some analyses (based on experimental evaluations) that are focused on calculating the quality of the speech signal so as to improve the overall accuracy of the system. As compared to existing methods that are based on voice activity detection (VAD), the proposed method is based on glottal activity detection (GAD) to detect the speech and non-speech regions from the input speech signals. Literature reveals that the GAD provides better results than VAD under noisy data condition for the above mentioned task. The proposed method uses a filter with specified cut-off frequency to separate the noise components that are present in the speech activity region. After that, we calculate the SNR as the ratio of the total energy in the speech activity region to that of the non-speech regions. The comparative analyses with two state-of-the-art techniques, viz, National Institute of Standards and Technology (NIST) SNR tool and Waveform Amplitude Distribution Analysis (WADA) SNR algorithm suggest that under different data conditions the proposed method outperforms the existing ones. Since the proposed model depends on the signal processing techniques and does not require any classifier or model to be developed, therefore it is found to be computationally efficient as compared to other two methods.








Similar content being viewed by others

References
Breithaupt, C., Gerkmann, T., & Martin, R. (2008). A novel a priori SNR estimation approach based on selective cepstro-temporal smoothing. In International Conference on Acoustics, Speech and Signal Processing. (pp. 4897–4900). IEEE.
Cohen, I. (2005a). Relaxed statistical model for speech enhancement and a priori SNR estimation. IEEE Transactions on Speech and Audio Processing, 13(5), 870–881.
Cohen, I. (2005b). Speech enhancement using super-Gaussian speech models and noncausal a priori SNR estimation. Speech Communication, 47(3), 336–350.
Elshamy, S., Madhu, N., Tirry, W., & Fingscheidt, T. (2015). An iterative speech model-based a priori SNR estimator. In Sixteenth Annual Conference of the International Speech Communication Association.
Ephraim, Y., & Malah, D. (1984). Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(6), 1109–1121.
Ephraim, Y., & Malah, D. (1985). Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 33(2), 443–445.
Fodor, B., & Fingscheidt, T. (2012). Reference-free SNR measurement for narrowband and wideband speech signals in car noise. In Proceedings of Speech Communication: ITG Symposium (pp. 1–4). VDE.
Furui, S. (1989). Digital speech processing synthesis, and recognition. New York: Marcel Dekker.
Garofolo, J. S., Lamel, L. F., Fisher, W. M., Fiscus, J. G., Pallett, D. S., Dahlgren, N. L., & Zue, V. (1993). Timit acoustic-phonetic continuous speech corpus. Philadelphia: Linguistic Data Consortium.
Gerkmann, T., Breithaupt, C., & Martin, R. (2008). Improved a posteriori speech presence probability estimation based on a likelihood ratio with fixed priors. IEEE Transactions on Audio, Speech, and Language Processing, 16(5), 910–919.
Hansen, J. H., & Pellom, B. L. (1998). An effective quality evaluation protocol for speech enhancement algorithms. In Fifth International Conference on Spoken Language Processing.
Hirsch, H. G., & Ehrlicher, C. (1995). Noise estimation techniques for robust speech recognition. In International Conference on Acoustics, Speech, and Signal Processing ICASSP-95. (Vol. 1, pp. 153–156). IEEE.
Hu, G., & Wang, D. (2008). Segregation of unvoiced speech from nonspeech interference. The Journal of the Acoustical Society of America, 124(2), 1306–1319.
Hu, Y., & Loizou, P. C. (2007). Subjective comparison and evaluation of speech enhancement algorithms. Speech Communication, 49(7–8), 588–601.
Kim, C., & Stern, R. M. (2008). Robust signal-to-noise ratio estimation based on waveform amplitude distribution analysis. In Ninth Annual Conference of the International Speech Communication Association.
Kinnunen, T., & Li, H. (2010). An overview of text-independent speaker recognition: From features to supervectors. Speech Communication, 52(1), 12–40.
Lotter, T., & Vary, P. (2005). Speech enhancement by MAP spectral amplitude estimation using a super-Gaussian speech model. EURASIP Journal on Advances in Signal Processing, 2005(7), 354850.
Manam, A. B., Revanth, T. S., Das, R. K., & Prasanna, S. M. (2016). Speaker verification using acoustic factor analysis with phonetic content compensation in limited and degraded test conditions. In Region 10 Conference (TENCON), 2016 IEEE (pp. 1402–1406). IEEE.
Martin, R. (1993). An efficient algorithm to estimate the instantaneous SNR of speech signals. In Third European Conference on Speech Communication and Technology.
Martin, R. (2001). Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Transactions on Speech and Audio Processing, 9(5), 504–512.
Moazzeni, T., Amei, A., Ma, J., & Jiang, Y. (2012). Statistical model based SNR estimation method for speech signals. Electronics Letters, 48(12), 727–729.
Morales-Cordovilla, J. A., Ma, N., Sánchez, V., Carmona, J. L., Peinado, A. M., & Barker, J. (2011). A pitch based noise estimation technique for robust speech recognition with missing data. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4808–4811). IEEE.
Murty, K. S. R., Yegnanarayana, B., & Joseph, M. A. (2009). Characterization of glottal activity from speech signals. IEEE Signal Processing Letters, 16(6), 469–472.
Narayanan, A., & Wang, D. (2012). A CASA-based system for long-term SNR estimation. IEEE Transactions on Audio, Speech, and Language Processing, 20(9), 2518–2527.
Paez, M., & Glisson, T. (1972). Minimum mean-squared-error quantization in speech PCM and DPCM systems. IEEE Transactions on Communications, 20(2), 225–230.
Papadopoulos, P., Tsiartas, A., & Narayanan, S. (2016). Long-term SNR estimation of speech signals in known and unknown channel conditions. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(12), 2495–2506.
Plapous, C., Marro, C., & Scalart, P. (2006). Improved signal-to-noise ratio estimation for speech enhancement. IEEE Transactions on Audio, Speech, and Language Processing, 14(6), 2098–2108.
Pollak, P., & Vondrasek, M. (2005). Methods for speech SNR estimation&58: Evaluation tool and analysis of VAD dependency. Radioengineering, 14(1), 6–11.
Rabiner, L. R., & Schafer, R. W. (1978). Digital processing of speech signals. Upper Saddle River: Prentice Hall.
Ren, Y., & Johnson, M. T. (2008). An improved SNR estimator for speech enhancement. In IEEE International Conference on Acoustics, Speech and Signal Processing. ICASSP. (pp. 4901–4904). IEEE.
Saha, P., Baruah, U., Laskar, R. H., Mishra, S., Choudhury, S. P., & Das, T. K. (2016). Robust analysis for improvement of vowel onset point detection under noisy conditions. International Journal of Speech Technology, 19(3), 433–448.
Scalart, P. (1996). Speech enhancement based on a priori signal to noise estimation. In IEEE International Conference on Acoustics, Speech, and Signal Processing (Vol. 2, pp. 629–632). IEEE.
Sohn, J., Kim, N. S., & Sung, W. (1999). A statistical model-based voice activity detection. IEEE Signal Processing Letters, 6(1), 1–3.
Suhadi, S., Last, C., & Fingscheidt, T. (2011). A data-driven approach to a priori SNR estimation. IEEE Transactions on Audio, Speech, and Language Processing, 19(1), 186–195.
Tchorz, J., & Kollmeier, B. (2003). SNR estimation based on amplitude modulation analysis with applications to noise suppression. IEEE Transactions on Speech and Audio Processing, 11(3), 184–192.
The NIST Speech, SNR Measurement [Online]. http://www.nist.gov/smartspace/nistspeechsnrmeasurement.html.
Varga, A., Steenneken, H. J. M., Tomlinson, M., & Jones, D. (1992). The NOISEX-92 study on the effect of additive noise on automatic speech recognition, 1992. Documentation included in the NOISEX-92 CD-ROMs.
Wang, D. (2005). Speech separation by humans and machines (pp. 181–197). Boston: Springer.
Zhao, X., Shao, Y., & Wang, D. (2011). Robust speaker identification using a CASA front-end. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). (pp. 5468–5471). IEEE
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Shome, N., Laskar, R.H. & Das, D. Reference free speech quality estimation for diverse data condition. Int J Speech Technol 22, 585–599 (2019). https://doi.org/10.1007/s10772-018-9537-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-018-9537-2