
Abstract
Significant progress has been made in information retrieval covering text semantic indexing and multilingual analysis. However, developments in Arabic information retrieval did not follow the extraordinary growth of Arabic usage in the Web during the ten last years. In the tasks relating to semantic analysis, it is preferable to directly deal with texts in their original language. Studies on topic models, which provide a good way to automatically deal with semantic embedded in texts, are not complete enough to assess the effectiveness of the approach on Arabic texts. This paper investigates several text stemming methods for Arabic topic modeling. A new lemma-based stemmer is described and applied to newspaper articles. The Latent Dirichlet Allocation model is used to extract latent topics from three Arabic real-world corpora. For supervised classification in the topics space, experiments show an improvement when comparing to classification in the full words space or with root-based stemming approach. In addition, topic modeling with lemma-based stemming allows us to discover interesting subjects in the press articles published during the 2007–2009 period.
Similar content being viewed by others



1 Introduction
Arabic is one among the six official languages of the United Nations organization where a considerable work has been done to develop the multilingual United Nations Bibliographic Information System Thesaurus. This UNBIS Thesaurus is used in subject analysis of documents and other materials relevant to the United Nations programs and activities. In addition, Arabic is one of the top ten languages in the Internet. For a global population of 350 millions in Arabic world, Internet World StatsFootnote 1 have reported, for Internet Arabic users, the highest growth rate with 2,501.2% for the period 2000–2010.
Unfortunately, developments in Arabic information retrieval (IR) did not follow this extraordinary growth. For most of the studies in the different IR tasks (such as categorization, clustering and search), English was used as the main language. However, when switching to Arabic, two approaches have been adopted for evaluating IR methods: either by retaining English as a pivot language when using parallel corpora in a cross-language context; either by processing the original Arabic text and analyzing the IR methods in a mono-language context. Although the first approach allows an equitable evaluation, it depends on the availability and the quality of parallel corpora. In the second approach, the evaluation of IR methods requires standard corpora and appropriate linguistic preprocessing. This approach becomes more interesting for the IR tasks with semantic analysis. It avoids the loss of meaning caused by translation from languages with high inflectional morphology such as Arabic (Oard and Gey 2002; Larkey et al. 2004). Unfortunately, Arabic IR, including stemming methods, did not receive sufficient standard evaluation.
In this context, three major challenges face the developments of the Arabic IR and generalization of existing methods on Arabic texts: (1) How to efficiently extract a good stem from a morpheme that implies several segmentations and senses? (2) How to apply a topic model to capture the semantics embedded in Arabic texts? (3) How to make more accessible Arabic resources for IR tasks to benefit from the various developments in non-commercial context.
This work aims to answer the first two questions raised above. On the one hand, a lemma-based stemming approach is proposed and compared with other Arabic stemmers. On the other hand, the Latent Dirichlet Allocation (LDA) model is used to extract Arabic topics from newspaper articles. As regards the third question, our experiments are conducted on three real-world corpus automatically crawled from the Web. All results and resources will be made freely available for the research community.
This paper presents first related works on Arabic stemming and topic modeling. Then, the lemma-based stemmer is described and evaluated with other approaches for Arabic text analysis. Afterwards, the generative process for LDA topic modeling is illustrated. Before presenting the results of our experiments, three datasets of newspaper articles are described. Finally, we discuss the main results and conclude our study.
2 Related works
2.1 Arabic stemming
Among the successful approaches for Arabic stemming, a root-based stemmer has been developed by (Khoja and Garside 1999). Based on predefined root lists and morphological analysis, Khoja algorithm attempts to extract the true root. However, more than one root can be found in an isolated word without diacritics. Although the KhojaFootnote 2 stemmer has not been maintained since its first publication, it has been widely used and analyzed in later works. As an instance, Al-Shammari lemma-based stemmer included Khoja algorithm for verbs stemming (Al-Shammari and Lin 2008). The authors combined successfully light stemming, root stemming and dictionary lookup. In addition to its effectiveness in clustering task, the Al-Shammari algorithm outperformed Khoja and light-stemmers in terms of over-stemming evaluation (Al-Shammari 2010).
For light stemming, several variants have been developed (Larkey et al. 2002). When applying in the AFP_ARB corpus, the authors have found that light stemmer was more effective for cross-language retrieval than a morphological stemmer. They deduce that it is not essential for a stemmer to yield the correct root. Surprisingly, in a technical report (Larkey and Connell 2001), the authors claim that these results, either in mono-lingual or cross-language retrieval, were obtained with no prior experience with Arabic. Another study has confirmed the same result which prefers light stemming for Arabic retrieval tasks (Moukdad 2006).
On the contrary, Brants et al. reported that, whether by stemming or using full forms, they have obtained the same performances for document topic analysis (Brants et al. 2002). A recent study about Arabic text categorization has highlighted this contradiction in literature and attempted to analyze various stemming tools (Said et al. 2009). In (Darwish et al. 2005), the authors showed that using context to improve the root extraction process may enhance the IR process. However, the context root extraction is computationally expensive compared with the light and root stemming. Similar to Khoja but without a root dictionary, a good light stemmer was developed by (Taghva et al. 2005). The authors found that stem lists are not required in an Arabic stemmer. They deduced that finding the true grammatical root of a term should not be the goal of a stemmer for document retrieval.
Compared to English and other languages, the research relating to Arabic texts stemming is fairly limited (Taghva et al. 2005). The main efforts to build efficient Arabic IR systems have been achieved in a commercial framework. The approaches used for these systems as well as the performance accuracy are not known. As a significant example, Siraj systemFootnote 3 from Sakhr allows to classify Arabic text and to extract named entities with human-satisfying response. However, it has no technical documentation to explain the used method neither the system evaluation.
2.2 Topic modeling
The LDA model has been introduced within a general Bayesian framework where the authors developed a variational method and EM algorithm for learning the model from collection of discrete data (Blei et al. 2003). The authors applied their model in document modeling, text classification and collaborative filtering. For document modeling, they trained a number of latent variable models, including LDA, on two texts corpora to compare the generalization performance compare the generalization performance, as measured by likelihood of held-out test data. Based on different datasets with various document numbers and vocabulary sizes, experiments show that the LDA model outperforms other models such as unigram model and pLSI.
In (Blei et al. 2006), LDA model was tested on CGC Bibliography items. Experiments show that LDA had better predictive performance than two standard models (unigram and mixture of unigrams). In the text classification problem, SVM has been trained in the low-dimensional representations produced by LDA from unlabeled documents. The authors conducted two binary classification experiments using the Reuters-21578 dataset. They realize a similar performance compared with SVM classification based on full words space.
It is worth pointing out that most datasets used for LDA evaluation are freely available and included few thousands of English documents (sometimes up to 20,000) with some 30,000 unique words. This was considered sufficient for analyzing and assessing the model performances but this is not the same case for topic modeling in other languages such as Arabic.
Since the original introduction of the LDA model, several contributions have been proposed. However, few studies, on finding latent topics in Arabic context, have been identified. In addition to the works related to Arabic topic detecting and tracking (Oard and Gey 2002; Larkey et al. 2004), a segmentation method that uses the Probabilistic Latent Semantic Analysis (Hofmann 1999) have been applied to AFP_ARB corpus for monolingual Arabic document topic analysis (Brants et al. 2002). In (Larkey et al. 2004), the researchers compared different topic tracking methods. They claimed that it should be preferable to use separate language for building specific topic models. Good topic models have been obtained when native Arabic stories are available. However, Arabic topic tracking has not been improved in texts translated from English stories.
In fact, studies on Arabic IR are insufficient and the few works carried out for topic modeling as well as for text stemming lack of rigorous evaluation. Considering the high inflectional morphology in Arabic, it seems more appropriate to learn LDA model in mono-language context taking more care for linguistic aspects. However, a large investigation on stemming methods is required for assessing Arabic topic modeling in real-world corpora.
3 Arabic text analysis
Unlike the indo-European languages, Arabic belongs to the Semitic languages family. Written from right to left, it includes 28 letters. Despite the fact that different Arabic dialects are spoken in the Arab world, there is only one form of the written language found in printed works which it is known as the Modern Standard Arabic, herein referred to as Arabic (Kadri and Nie 2006). In addition to its derivational morphology, the main characteristics of the Arabic language, which complicate any automatic text analysis, are the agglutination and the non-vocalization.
3.1 Arabic language features
Arabic is a highly inflected language due to its complex morphology. An Arabic word can be one of three morpho-syntactic categories: nouns, verbs or particles. Several works have used other categories (such as prepositions and adverbs) with no good reason except that they are taken from English (Larkey et al. 2002; Tuerlinckx 2004; Moukdad 2006).
The lemma is the dictionary entry which is fully vocalized and relates to any form of text. Particularly, the verbs are reduced to the third masculine singular in past tense. All nouns and verbs are derived from a non-vocalized root according to one of the Arabic patterns. The root is a linguistic unit carrying a semantic area. It is a non-vocalized word (more general than lemma) and often consists of only 3 consonants (rarely 4 or 5 consonants) (Kadri and Nie 2006; Tuerlinckx 2004).
3.1.1 Morphological complexity
In Semitic languages, the root is an essential element from which various words may be derived according to specific patterns or schemes. The morphological complexity in Arabic is characterized by inflection and derivation.
Inflection modifies the word to express different grammatical categories for the same meaning such as gender, number, place or tense. Some irregular inflection schemes did not use simple prefixed or suffixed roots but also they apply infixation and complex affixation process. The following examples illustrate Arabic inflection with the irregular plural (called broken plural):
-
from the root [Elm]
 : plural of [Eilm, science]
: plural of [Eilm, science] is [Eulum, sciences]
is [Eulum, sciences]  ,
, -
from the root [ktb]
 : plural of [kitAb, book]
: plural of [kitAb, book] is [kutub, books]
is [kutub, books]
 : plural of [Eilm, science]
: plural of [Eilm, science] is [Eulum, sciences]
is [Eulum, sciences]  ,
, : plural of [kitAb, book]
: plural of [kitAb, book] is [kutub, books]
is [kutub, books]
However, derivation is a root affixation process generating a new word with different meaning but generally in the same semantic area. An example of verb derivation from the root [Elm] is [>aEolam, notify/inform]
is [>aEolam, notify/inform] and [{isotaEolam, inquire]
and [{isotaEolam, inquire] .
.
3.1.2 Agglutination
In Arabic text, a lexical unit is not easily identifiable from a graphic unit (word delimited by space characters or punctuations marks). Morphological affixation process becomes more complicated when extra affixes are agglutinated to a lemma. Indeed, a word can be extended by attaching four kinds of affixes (antefix, prefix, suffix and postfix). Table 1 shows an example of an agglutinated and inflected word, [wayaEolamuwnahu] where various kinds of affixes are attached to the core form [Elm]
where various kinds of affixes are attached to the core form [Elm]
 .
.
This situation can make a high ambiguity to extract the right core (stem) from an agglutinated form. In non-vocalized texts, morphology analysis become more difficult as illustrated above in Table 1. There are other agglutinative languages such as Japanese, Turkish and Finnish but the problem of non-vocalization is not as complicated as in Arabic.
3.1.3 Vocalization
Arabic word is vocalized with diacritics (short vowels) but unfortunately, full or partial vocalization can be found only in didactic documents or in Koranic text. This fact accentuates the ambiguity of words and requires from each automatic analyzer to pay more attention to the morphology and the word context. In Table 2, the non-vocalized word [bsm] gives more than one segmentation with different meanings. This is mainly due to diacritics missing in an agglutinated form.
gives more than one segmentation with different meanings. This is mainly due to diacritics missing in an agglutinated form.

3.2 Stemming methods
Stemming is a process for conflating inflected or derived words to a unique base-stem. It is an important way to reduce collection vocabulary. In addition, stemming avoids dealing with the same word as different index entries. Two classes of Arabic stemming methods can be identified: (1) Light stemmers by removing the most common affixes and, (2) Morphological analyzers by extracting each core (root or lemma) according to a scheme.
3.2.1 Light stemmers
They refer to the technique which truncates from a word a reduced list of affixes without trying to find roots. Effectiveness of this approach depends on the content of prefixes and suffixes lists. When, in English, one tries to find a stem by, mainly, removing conjugation suffixes, we have to deal in Arabic texts with ambiguous agglutinated forms that imply several morphological derivations. An analysis of such an approach can be found in (Larkey et al. 2002). ISRI stemmer is another example of light stemming (Taghva et al. 2005). Without a root dictionary, the ISRI Footnote 4 algorithm use some affix lists and most common patterns to extract roots. Nevertheless, it keeps normalized form for unfound stem.
This kind of stemmers can effectively deal with most practical cases, but in some ones, the right word is lost. As an example, in the word [wafiy] , one can read two agglutinated prepositions that mean to “and in” but another will consider a noun, which means “faithful/complete”.
, one can read two agglutinated prepositions that mean to “and in” but another will consider a noun, which means “faithful/complete”.
3.2.2 Morphological analyzers
In morphological analysis, we try to extract more complete forms according to vocalization variation and derivation patterns knowledge. We can distinguish two categories of analyzers according to the nature of desired output unit: (1) Root-based stemmers and, (2) lemma-based stemmers. The choice between the two approaches depends on how further stemming results, in IR tasks or in language modeling, will be used.
In first category, the Khoja stemmer, which attempts to find root for Arabic words, has been proposed in (Khoja and Garside 1999). A list of roots and patterns is used to determine the right stem. This approach produces abstract roots, which reduce significantly the dimension of document features space, but it leads to a confusion of divergent meaning embedded in a unique non-vocalized stem. For example, stemming of the word  cited above in Table 1 must deduce the root-stem
cited above in Table 1 must deduce the root-stem  with possible meaning to verbs “to know or to teach”. However, the same root can mean to the noun “flag”.
with possible meaning to verbs “to know or to teach”. However, the same root can mean to the noun “flag”.
In second category, a lemma-based stemmer has been developed and compared to Khoja stemmer (Al-Shammari and Lin 2008). The authors combined light stemming with Khoja algorithm for antefixes removal and verbs stemming before processing the remaining words as nouns. They use a stop list exceeding 2,200 words with verbs and nouns dictionaries as linguistic resources. In addition to clustering performance comparison, they used a collection of concept groups for under- and over-stemming evaluation. Unfortunately, neither these resources nor the test collections are available. As shown in Table 2, an Arabic word can induce more than one stem and so more than one lemma. The above approaches did not support this aspect.
For this purpose, a set of Arabic lexiconsFootnote 5 has been developed with rules for legal combinations of lemma-stems and affixes forms (Buckwalter 2002). P. Brihaye has developed AraMorph, Footnote 6 a java package for Arabic lemmatization based on Buckwalter Arabic morphological analyzer. Several stemming solutions can be proposed for each word. From this analyzer, one can develop, under some considerations, a lemma-based stemmer. This approach will be described hereafter.
3.3 Lemma-based stemmer
We propose to develop an algorithm for lemma-based stemmer that is called the Brahmi-Buckwalter Stemmer and referred henceforth as BBw. Based on the resources of the Buckwalter morphological analyzer, two main contributions can be reported for the BBw stemmer: (1) Normalization preprocessing and, (2) stem selection with morphological analysis.
3.3.1 Normalization
This step is performed for normalizing the input text. Then the obtained list of tokens will be processed by the Buckwalter morphological analyzer.
-
Convert to UTF-8 encoding
-
Tokenize text respecting the standard punctuation
-
Remove diacritics and tatweel (
 )
) -
Remove non-Arabic letters and stop-words.
-
Replace initial alef with hamza (
 or
or 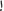 ) by bar-alef (
) by bar-alef (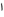 )
) -
Replace final waw or yeh with hamza (
 or
or  ) by hamza (
) by hamza ( )
) -
Replace maddah (
 ) or alef-waslah (
) or alef-waslah ( ) by bar-alef (
) by bar-alef ( )
) -
Replace two bar-alef (
 ) by alef-maddah (
) by alef-maddah ( )
) -
Replace final teh marbuta (
 ) by heh (
) by heh ( )
) -
Remove final yeh (
 ) when the remaining stem is valid.
) when the remaining stem is valid.
 )
) or
or 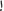 ) by bar-alef (
) by bar-alef (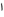 )
) or
or  ) by hamza (
) by hamza ( )
) ) or alef-waslah (
) or alef-waslah ( ) by bar-alef (
) by bar-alef ( )
) ) by alef-maddah (
) by alef-maddah ( )
) ) by heh (
) by heh ( )
) ) when the remaining stem is valid.
) when the remaining stem is valid.3.3.2 Stem selection
When an input token (in-token) is processed by the Buckwalter morphological analyzer, three cases can be reported: (1) A unique solution is given according to a specific pattern. (2) Multiple solutions are found corresponding to several patterns and lexicon entries. (3) No solution can be attributed to the in-token. The actions, that the BBw stemmer must undertake, will be detailed bellow.
Unique solution. The BBw stemmer retains only the non-vocalized lemma-stem of the solution (without affixes). A solution without noun or verb lemma (i.e., contains only particles) is ignored and therefore the in-token is considered as a stop-word.
Multiple solutions. The BBw stemmer treats all the proposed solutions as a set of separated unique solutions and thus retains all non-vocalized lemma-stem. Note that eliminating diacritics from lemmas may unify some stems and so reduce the solutions multiplicity. For example, Table 2 gives four vocalized solutions for the token [bsm]  but after removing diacritics from output lemmas, the BBw stemmer will identify only two confused stems {[bsm]
but after removing diacritics from output lemmas, the BBw stemmer will identify only two confused stems {[bsm]  , [sm]
, [sm]  }. It is worth pointing out that most of the Arabic proper names can be derived regularly from roots. In this case multiple solutions, including the in-token, must be considered.
}. It is worth pointing out that most of the Arabic proper names can be derived regularly from roots. In this case multiple solutions, including the in-token, must be considered.
No solution. The in-token cannot have a solution in the following cases, different reasons can be raised: (1) The in-token is wrong and it did not imply any Arabic lemma. (2) The in-token corresponds to a proper name (person, city, etc.) that has no entry in the dictionary. (3) The in-token is a correct Arabic word but it is not yet included in the current release of Buckwalter morphological analyzer.
In this study, we have opted to improve the normalization preprocessing in BBw algorithm based on the original Buckwalter lexicon. Three stemmer variants (BBw0, BBw1, BBw2) are developed and evaluated on different Arabic datasets. Table 3 summarizes stem selection approach for each BBwX stemmer.
3.3.3 Confusion degree measure
When the morphological analysis of an in-token implies multiple solutions, each BBwX stemmer produces multiple lemma-stems. From a collection (S), we denote by L ≠ 0 the total number of in-tokens after stop-words removal. L R ≠ 0 refers to the total number of stems when stemming (S) with an algorithm (R). Then, the confusion degree C(S|R) is defined as:
For example, C(S|Khoja) = 1, since the Khoja stemmer gives at most one stem for each token in any dataset S. This is an ideal situation for a stemming process but when applying the BBwX stemmers, the confusion degree C will be increased. We proposed this measure C(S|R) for assessing the lexical ambiguity in Arabic texts. For a human Arabic reader, this problem will be solved easily with semantic considerations guided by the context.
For BBwX stemming, note that all possible stems are equitably related to their in-token. At this stage, we have not precise knowledge to select the good stem. Nevertheless, that the relevant solution can be weighted later by a co-occurrence computation in local context. We think that this will be possible with LDA topic modeling.
3.4 Stemming evaluation
Although the literature describes various Arabic stemmers, only few of them have received a standard evaluation (Al-Shammari 2010; Said et al. 2009). A way to assess the effectiveness of stemming algorithms is to evaluate their performances in information retrieval tasks. This requires standard and representative test collections. Nevertheless, it is unsure that good performances in IR tasks result only from stemming quality (Paice 1996; Frakes 2003). Herein, we describe three stemming metrics used in this present work. Such metrics allow assessing some stemming aspects independently of IR tasks performance.
3.4.1 Index compression
The Index Compression Factor (ICF) represents the extent to which a collection of unique words is reduced (compressed) by stemming, the idea being that the heavier the Stemmer, the greater the Index Compression Factor (Frakes 2003). This can be calculated by:
N, Number of unique words before stemming; S, Number of unique stems after stemming
The ICF factor has been introduced as a strength measure to evaluate stemmers and compression performance. However, vocabulary compression did not mean to ideal stemming. In fact, a good stemmer is that stems all the words to their correct roots. The following measures may satisfy this condition.
3.4.2 Under- and over-stemming
Under-stemming is the failure to conflate morphologically related words. This occurs when two words that should be stemmed to the same root are not. An example of under-stemming would be if the words “adhere” and “adhesion” are not stemmed to the same root.
Over-stemming refers to words that should not be grouped together by stemming, but are. For example, merging the words “probe” and “probable” after stemming would constitute an over-stemming error.
Using a sample file of W grouped words, under-stemming errors are then counted as described in (Paice 1996). A concept group contains forms which are both semantically and morphologically related one to another. For each group g containing n g words, the number of pairs of different words defines the desired merged total (DMT g ):
Since a perfect stemmer should not merge any member of a group with other group words, for every group there is a desired non-merge total (DNT g ):
When summing these two totals over all groups, one can obtain the global desired merged total (GDMT) and the global desired non-merge total (GDNT) respectively. Thus, stemming errors are calculated as follows:
Conflation Index (CI): proportion of equivalent word pairs which were successfully grouped to the same stem; Distinctness Index (DI): proportion of non-equivalent word pairs which remained distinct after stemming
The under-stemming index (UI) and the over-stemming index (OI) are given by:
In (Paice 1996), the author proposed to compute the ratio of these two quantities as a measure of the stemming weight (SW):
The purpose of the Paice’s error-counting approach is that, although it is advantageous to have the index of terms compressed, this is only useful up to a point. This is because, as conflation becomes ‘heavier’, the merging of distinct concepts becomes increasingly frequent. At this point, small increases in Recall are gained at the expense of a major loss of Precision (Frakes 2003).
One question mark over this approach concerns the validity of the grouped file against which the errors are assessed. These grouped files were constructed by human judgment, during scrutiny of sample word lists (Paice 1996; Frakes 2003). For Arabic stemming evaluation, Al-Shammari has selected a sample of 419 words and has divided them into 81 conceptual groups (i.e. close to 5 words per group). Comparing to Khoja and Light stemmers, Al-Shammari’s lemmatizer has reduced over-stemming errors. However, no effective improvement is achieved for under-stemming counting (Al-Shammari 2010).
4 LDA topic model
Latent Dirichlet allocation (LDA) is a generative topic model for text documents (Blei et al. 2003). Based on the classical “bag of words” assumption, a topic model considers each document as a mixture of topics where a topic is defined by a probability distribution over words.
The distribution over words within a document (d) is given by:
where P(w|z) defines the probability distribution over words w given topic z and P(z|d) refers to the distribution over topics z in a collection of words (document). More details and interpretations about topic models can be found in (Blei et al. 2003; Steyvers and Griffiths 2007)
For a given number of topics T, LDA model will be trained from a collection of documents defined as follows:
-
N: number of words in vocabulary.
-
M: number of document in corpus.
-
T: number of topics, given as input value.
-
P(z/d): distribution over topics z in a particular document.
-
P(w/z): probability distribution over words w given topic z.
Then, we can define a generative process as follows:
For each document d = 1 to M (in dataset) do:
-
1.
Sample mixing probability θ d ~ Dir(α)
-
2.
For each word w di = 1 to N (in vocabulary) do:
-
2.a.
Choose a topic z di ∈ {1,…, T} ~ Multinomial (θ d )
-
2.b.
Choose a word w d ∈ {1,…, N} ~ Multinomial (β zdi )
-
2.a.
where α is a Dirichlet symmetric parameter and {β i } are multinomial topic parameter. Each β i assigns a high probability to a specific set of words that are semantically related. This distribution over vocabulary is referred to as topic. In the present work, we use LingPipe Footnote 7 LDA implementation which is based on Gibbs sampling for parameters estimation.
The choice of the number of topics can affect the interpretability of the results. A model with too few topics will generally result very broad topics. However, a model with too many topics will result in an uninterpretable model (Steyvers and Griffiths 2007). Since the number of topics (T) is given as an input parameter for training the LDA model, several methods were proposed to select a suitable T. An evident approach is to choose T that leads to best performance for tasks (classification, clustering …etc.).
5 Building Arabic datasets
As raised above, developments in Arabic IR are often faced with the problem of unavailability of standard free resources. So, we have opted to build our own experimentations datasets. For this aim, we developed a Web-CrawlerFootnote 8 to collect newspaper articles from several Arabic websites. In this study, we present three real-world corpora based on Echorouk, Footnote 9 Reuters Footnote 10 and Xinhua Footnote 11 Web-articles. Each article is saved with UTF-8 encoding in a separated text file where the first line is reserved to its title. A brief description is given in Table 4.
5.1 Datasets description
Echorouk collection contains 11,313 documents from Echorouk newspaper articles relating to 2008–2009 period. It is labeled according to eight categories. From the full corpus Ech-11k, we build a subset, Ech-4000, of 4,000 documents for preliminary evaluations.
Reuters collection, Rtr-41k, contains 41,251 Arabic documents relating to 2007–2008–2009 period. It is labeled according to six categories. A subset, Rtr-5251, of 5251 documents is used for preliminary evaluations.
Xinhua collection contains 36,696 Arabic documents relating to 2008–2009 period. It is labeled according to eight categories. A subset, Xnh-4500, of 4500 documents is used for preliminary evaluations. Table 5 describes the collected datasets with their distributions over published categories.
5.2 Arabic stemming
The three lemma-based stemmers (BBw0, BBw1 and BBw2) were applied on the three datasets described above. For comparison, we use ISRI algorithm for light stemming and 2 variants of Khoja algorithm for root-based morphological analysis. The first one, Khoja0, is the original Khoja algorithm which gives only the found roots. The second variant, Khoja1, allows adding unfound words to the vocabulary. Furthermore, we use the raw text as baseline characterization in preliminary experiments. For aligning comparison, the stop-word list used in BBwX algorithms is removed from other stemmers output.
For each stemmer, different sizes of corpus vocabularies are reported in Table 6. As a main observation for the three datasets, stemming results show that ISRI algorithm produce high vocabulary dimensions. Close to raw text, ISRI do not provide significant reduction in the feature space. On the contrary, morphology analysis, with Khoja and BBw, decrease the vocabulary size by unifying tokens those have a common root or lemma. Retaining only the correct form, Khoja0 and BBw0 stemmers produce the lower vocabularies.
In morphological analysis, it is clear that our lemma-based stemmer (BBw0) enhances the feature space when comparing to a root-based stemmer (Khoja0). However, the vocabularies produced when adding unrecognized tokens (Khoja1 and BBw2), show a lack in the used lexicons. We have expected such cases by analyzing the BBwX variants as described in a previous sections where we discussed the “no solution” causes. To analyze the loss caused by this lack, we compute the ratio of unfound tokens by comparison with all the words (found and unfound). Figure 1 shows that the BBw lexicon more complete than Khoja.

The unfound tokens rate for the two analyzers, Khoja and BBw
To complete our preliminary analysis and assess performances of BBwX stemmers when dealing with ambiguous forms, we compute the confusion degree as defined in (1).
According to Table 7, the maximum confusion degree, in real-world corpora, does not exceed 1.16. This indicates that when our stemming approach includes all multiple solutions in vocabulary, it preserves all word senses without significant lexical ambiguity.
5.3 Stemming evaluation
ICF and Paice metrics have been tested on the three datasets for analyzing stemmers’ quality. For evaluation fairness, the index compression factor has been calculated after stop-words removal as applied in BBwX stemmers. In lemma-based stemming, a larger stop-list with 575 words is used. As defined in (2), Table 8 summarizes the ICF computing.
Table 8 show that Khoja0 root-stemmer and BBw0 lemma-stemmer have performed the best compression over the three datasets. However, light stemming with ISRI did not give a significant index reduction. Because they keep unknown tokens as proper stems, the other variants of Khoja and BBw have reduced slightly the index.
For Paice’s evaluation, the main difficulty consists of how to build a representative concept groups. Al-Shammari has used a moderate set of 81 groups for comparing her lemmatizer to Khoja and light Arabic stemmers. Unfortunately, no test collections or concept groups used in experiments were available (Al-Shammari 2010).
In this study, we have built a large real-world concept-groups by processing the article titles in the three datasets (Ech-11k, Rtr-41k and Xnh-36k). After stop-words removal and preliminary grouping, we have selected the groups that contained 10 words at least. Then, we have revised the resulting groups with an Arabic expert before retaining a collection of 13,142 words distributed on 689 groups. Because all the selected words are recognized by Khoja and BBw stemmers, it was not necessary to calculate stemming errors for the other variants (KhojaX, BBwX). Table 9 gives results of the Paice’s evaluation.
Results show that our lemma-based stemmer provides the lowest over-stemming and under-stemming indexes (OI and UI). It is a significant performance compared to Khoja and ISRI stemmers. Remember that BBw stemmer can generate multiple stems for an in-token. Theoretically, this fact increases the under-stemming errors but empirically, results show that BBw improves the sense distinctness.
6 Experiments and results
The experiments performed for text categorization and topic modeling are described and analyzed in this section. Support vector machine (SVM) is a kernel-based method which has been introduced by (Vapnik 1995) for binary and multi-class classification. In this work, the LIBSVMFootnote 12 package is applied for multi-class text categorization. As SVM training parameter, the simple linear kernel is used with a cost parameter set to 10. For performance evaluation, fivefold cross validation is performed for each feature space of datasets.
It is worth pointing out that: (1) for each dataset, six stemmers (ISRI, Khoja0, Khoja1, BBw0, BBw1 and BBw2) are applied for categorization and topic modeling, (2) raw text is used as baseline, (3) for topic modeling, all datasets are used as unlabeled collections.
6.1 Classification in full word space
For the basic words space definition, the TF and the TF-IDF measures are applied on stemmed datasets. TF t refers to the term frequency of each term (t) in its document. The inverse document frequency (IDF t ) measures the general importance of the term over a set of documents (D). In this work, we use the simple formulation of a TF-IDF measure as follows:
The three subsets (Ech-4000, Rtr-5251 and Xnh-4500) are used for text categorization in the full word space. According to two term models (TF and TF-IDF) and various stemming approaches, Fig. 2 gives a preliminary evaluation for text classification.

Classification accuracy in the full-word space of the three datasets (Ech-4000, Rtr-5251 and Xnh-4500)
As a main observation, the Khoja stemmers give the weakest performances. With abstract root stemming and incomplete lexicon, Khoja0 algorithm decreases text characterization. When adding unfound tokens, Khoja1 variant improves slightly classification performances. Although the ISRI light stemmer produces huge vocabularies, it seems give good performances for classification in the full word space. The same point can be reported when dealing with raw text. However, the BBwX stemmers improve classification accuracy for reasonable dimension of words space.
6.2 Classification in topics space
The three subsets (Ech-4000, Rtr-5251 and Xnh-4500) with various stemming variants are trained with LDA algorithm. For several numbers of topics, we report in Tables 10, 11 and 12 the classification accuracy obtained by SVM cross-validation.
According to Tables 10, 11 and 12, we can deduce the suitable number of topics for each stemmed dataset. The best models may be obtained when choosing, for LDA training, a number of topics between 100 and 400.
Considering stemming methods, preliminary experiments show that Khoja stemmers give the lowest classification performances. Unexpected results for linguists show that with raw texts, topic modeling can produce performances as good as with morphological analysis. Remind us that light stemming (ISRI) also has generated large vocabularies where different entries should be conflated in a single Arabic stem.
Focusing on morphological analyzers, experiments show that BBw lemma-based stemmers improve classification in topics space compared to Khoja root-based stemmers. For Reuters collection as example, we highlight in Fig. 3 the difference between the stemmers which retain only the correct Arabic forms. It is clear that lemma-based stemming enhances LDA modeling even with low topics number.

Classification accuracy in topics space of the Rtr-5251 corpus. Comparison between root-based (Khoja0) and lemma-based (BBw0) stemming
6.3 Finding topics in newspaper articles
In this section, we illustrate some results of LDA modeling in Arabic texts. The BBw2 algorithm was used for stemming the three complete datasets (Echorouk, Reuters and Xinhua). Note that a latent topic can be titled with human assessment according to its relevant terms. For example, we give in Table 13 topics distribution which are most relevant to the word [mAl, money] .
.
 ) in Echorouk (Ech-11k) dataset
) in Echorouk (Ech-11k) datasetIn addition, we propose to compute the categories distribution over learned topics. A confusion matrix (category\topic) can be obtained by adding document distributions of the same category. In Table 14, we give an illustration of the categories distribution over the eight main topicsFootnote 13 from Reuters dataset. By setting a likelihood threshold at 10%, one can identify relevant topics in each category. For example, one will easily discover that the main subjects in sport category during 2007–2009 were football and Tennis.
Furthermore, words can be analyzed by finding their different contexts when training LDA for each collection. Among 100 latent topics, we report in Table 15 the relevant topics to some words. Two senses can be assigned to the first one, [slAm] , either peace or greeting/salutation.
, either peace or greeting/salutation.
 and [mAl]
and [mAl] ) in each dataset
) in each datasetIt is clear, in Table 15, that the different contexts related to this word imply the first sense excepting the topic “Coal mines in Australia”. In fact, the forth topic in Xnh-36 k dataset is related to another word. The input token [slAmh] has two BBw stemming solutions ([slAm]
has two BBw stemming solutions ([slAm] and [slAmh]
and [slAmh] ). The second solution means safety which is highly correlated to security and safety requirements in coal mines. However, vocabularies obtained by Khoja stemming do not contain this entry because the word [slAm]
). The second solution means safety which is highly correlated to security and safety requirements in coal mines. However, vocabularies obtained by Khoja stemming do not contain this entry because the word [slAm] was indexed by its root [slm]
was indexed by its root [slm] . This non-vocalized word induces various senses such as [sul~im, be conceded]
. This non-vocalized word induces various senses such as [sul~im, be conceded] , [silom, peace]
, [silom, peace] and [sul~am, stairs]
and [sul~am, stairs] . Furthermore, Khoja algorithm indexes under the same root other lemmas such as [isolam, Islam]
. Furthermore, Khoja algorithm indexes under the same root other lemmas such as [isolam, Islam] and [saliym, correct]
and [saliym, correct] .
.
The second word, [mAl] , means either money/capital/funds or lean/bend/incline/sympathize. However, Table 15 shows that several specific topics are related to the first sense including some ways to financing Al-Qaida organization.
, means either money/capital/funds or lean/bend/incline/sympathize. However, Table 15 shows that several specific topics are related to the first sense including some ways to financing Al-Qaida organization.
7 Conclusion and future work
For information retrieval tasks, several stemming approaches have been proposed and applied on Arabic texts. The light stemmers try to remove from a word the most common affixes. However, the morphological analyzers attempt to extract the correct root or lemma. The preference of a particular method depends on the nature of the following IR task. Unfortunately, the literature does not give clear answers for choosing the appropriate stemming method. Using raw text for categorization or topic analysis can also lead to acceptable performances (Brants et al. 2002; Said et al. 2009).
Two main contributions were presented in this study: Firstly, we have proposed the BBw lemma-based stemming with specific text normalization and multiple lemmas indexing. By applying a confusion measure on three real-world corpora, we have shown that our stemming approach may preserve the semantic embedded in Arabic texts without compromising lexical characterization. The Paice’s evaluation has been used to measure under- and over-stemming errors. The results have shown a high effectiveness for our approach. The BBw lemma-based stemmer reduces significantly vocabulary dimension, under- and over-stemming errors. In addition, classification performance is improved slightly compared to classification of raw and light stemmed texts.
For morphological analysis, three BBw variants were compared to root based stemmers (Khoja0 and Khoja1). The two variants tested for Khoja algorithm have shown a lack in its lexicon (roots and patterns). This limitation was surmounted by adding the unfound words as new vocabulary entries. However, it would be judicious to maintain permanently linguistic resources.
Secondly, three real-world corpora were tested for Arabic stemming and topic modeling. Tens of thousands of Web-articles were automatically crawled from Echorouk, Reuters and Xinhua. The variety of writing styles allows us to validate the proposed lemma-based stemmer. For topic modeling evaluation, SVM classification was successfully tested with various stemming methods. In particular, the proposed BBw stemming approach proved its efficiency in both text classification and Arabic topic modeling.
Furthermore, topic LDA modeling was applied in Arabic texts. A large investigation was carried out by varying the topics number. Classification in topics space was achieved to assess the performances LDA model with different stemming methods. When training LDA in BBw vocabularies, interpreting topics was easier than those obtained from Khoja roots.
It is worth pointing that it is difficult to understand how one can assess semantic aspects in Arabic texts without sufficient linguistic knowledge (Larkey et al. 2002, 2004). This study shows that effective developments in Arabic IR and topic modeling can not be performed without close collaboration between computer scientists and Arabic language experts.
As future work, the BBw stemmer will be improved by handling additional irregular forms and enhancing lexicons to proper names (person, location and organization). Further effort must be oriented to topic model integration with end-user retrieval system.
Notes
Internet World Stats, Usage and population statistics (Miniwatts Marketing Group). Updated for June 30, 2010, last visited in August 2010. http://www.internetworldstats.com/.
Freely available at http://www.zeus.cs.pacificu.edu/shereen/ArabicStemmerCode.zip.
Available at http://www.alias-i.com/lingpipe/index.html.
Developed with Amine Roukh and Abdelkadir Sadouki in the Mostaganem University.
Algerian newspaper with online edition at http://www.echoroukonline.com/.
International news agency with Arabic online edition at http://www.ara.reuters.com/.
Chinese news agency with Arabic online edition at http://www.arabic.news.cn/.
LIBSVM-2.89 is available at http://www.csie.ntu.edu.tw/~cjlin/libsvm+zip.
More details are available at https://sites.google.com/site/abderrezakbrahmi/.
References
Al-Shammari, E. (2010). Lemmatizing, stemming, and query expansion method and system. US Patent 20100082333, April 2010.
Al-Shammari, E., & Lin, J. (2008). A novel Arabic lemmatization algorithm. In Proceedings of the workshop on analytics for noisy unstructured data, Singapore, pp. 113–118.
Blei, D. M., Franks, K., Jordan, M. I., & Mian, I. S. (2006). Statistical modeling of biomedical corpora: Mining the caenorhabditis genetic center bibliography for genes related to life span. BMC Bioinformatics, 7, 250. doi:10.1186/1471-2105-7-250.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3, 993–1022.
Brants, T., Chen, F., & Farahat, A. (2002). Arabic document topic analysis. LREC-2002 workshop on Arabic language resources and evaluation, Las Palmas, Spain.
Buckwalter, T. (2002). Buckwalter Arabic morphological analyzer version 1.0. Linguistic data consortium, University of Pennsylvania. LDC catalog no. LDC2002L49.
Darwish, K., Hassan, H., & Emam, O. (2005). Examining the effect of improved context sensitive morphology on Arabic information retrieval. In Proceedings of the ACL workshop on computational approaches to semitic languages, Ann Arbor, Michigan, pp. 25–30.
Frakes, W. B. (2003). Strength and similarity of affix removal stemming algorithms. In SIGIR forum (Vol. 37, issue 1), pp. 26–30.
Hofmann T. (1999). Probabilistic latent semantic analysis. In Proceedings of the fifteenth conference on uncertainty in artificial intelligence, pp. 289–296.
Kadri, Y., & Nie, J. (2006). Effective stemming for Arabic information retrieval. The challenge of Arabic for NLP/MT, international conference at the British Computer Society (BCS), pp. 68–74. London, UK.
Khoja, S., & Garside, R. (1999). Stemming Arabic text. Technical report. Computing Department, Lancaster University, Lancaster.
Larkey, L. S., Ballesteros, L., & Connell, M. E. (2002). Improving stemming for Arabic information retrieval: Light stemming and co-occurrence analysis. In Proceedings of SIGIR 2002, pp. 275–282. Tampere, Finland.
Larkey, L. S., & Connell, M. E. (2001). Arabic information retrieval at UMass in TREC-10. In TREC 2001, pp. 562–570. Gaithersburg, Maryland, USA.
Larkey, L. S., Feng, F., Connell, M. E., & Lavrenko, V. (2004). Language-specific models in multilingual topic tracking. In Proceedings of SIGIR 2004, 402–409. Sheffield, UK.
Moukdad, H. (2006). Stemming and root-based approaches to the retrieval of Arabic documents on the Web. Webology, 3(1), article 22.
Oard, D. W., & Gey, F. (2002). The TREC-2002 Arabic/English CLIR track. In TREC2002 notebook, pp. 81–93.
Paice, C. D. (1996). Method for evaluation of stemming algorithms based on error counting. Journal of the American Society for Information Science, 47(8), 632–649.
Said, D., Wanas, N., Darwish, N., & Hegazy, N. (2009). A study of text preprocessing tools for Arabic text classification. In Proceedings of the 2nd international conference on Arabic language resources and tools, pp. 230–236. Cairo, Egypt.
Steyvers, M., & Griffiths, T. (2007). Probabilistic topic models. Handbook of Latent Semantic Analysis. Mahwah, NJ: Lawrence Erlbaum.
Taghva, K., Elkoury, R., & Coombs, J. (2005). Arabic stemming without a root dictionary. In Proceedings of the international conference on information technology: Coding and computing, Vol. 01, pp. 152–157.
Tuerlinckx, L. (2004). La lemmatisation de l’arabe non classique. In JADT 2004, 7e Journées internationales d’Analyse statistique des Données Textuelles, pp. 1069–1078.
Vapnik, V. N. (1995). The nature of statistical learning theory. New York, NY, USA: Springer-Verlag New York, Inc.
Acknowledgments
We gratefully acknowledge Professor Patrick Gallinari, director of LIP6 laboratory (Paris-France), for his valuable advices to achieve this work. We would like to thank the reviewers of INRT journal for their insightful and constructive comments.
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article
Cite this article
Brahmi, A., Ech-Cherif, A. & Benyettou, A. Arabic texts analysis for topic modeling evaluation. Inf Retrieval 15, 33–53 (2012). https://doi.org/10.1007/s10791-011-9171-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10791-011-9171-y