
Abstract
Twitter (http://twitter.com) is one of the most popular social networking platforms. Twitter users can easily broadcast disaster-specific information, which, if effectively mined, can assist in relief operations. However, the brevity and informal nature of tweets pose a challenge to Information Retrieval (IR) researchers. In this paper, we successfully use word embedding techniques to improve ranking for ad-hoc queries on microblog data. Our experiments with the ‘Social Media for Emergency Relief and Preparedness’ (SMERP) dataset provided at an ECIR 2017 workshop show that these techniques outperform conventional term-matching based IR models. In addition, we show that, for the SMERP task, our word embedding based method is more effective if the embeddings are generated from the disaster specific SMERP data, than when they are trained on the large social media collection provided for the TREC (http://trec.nist.gov/) 2011 Microblog track dataset.
Similar content being viewed by others

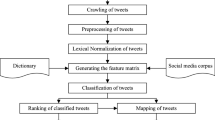

Notes
hereafter referred to as tweets
References
Bandyopadhyay, A., Ghosh, K., Majumder, P., Mitra, M. (2012). Query expansion for microblog retrieval. IJWS, 1(4), 368–380. https://doi.org/10.1504/IJWS.2012.052535.
Corso, G.M.D., Gulli, A., Romani, F. (2005). Ranking a stream of news. In: WWW.
Diaz, F.,Mitra, B., Craswell, N. (2016). Query expansion with locally-trained word embeddings. arXiv:1605.07891.
Dong, A., Chang, Y., Zheng, Z., Mishne, G., Bai, J., Zhang, R., Buchner, K., Liao, C., Diaz, F. (2010). Towards recency ranking in web search. In: WSDM, pp. 11–20. ACM. https://doi.org/10.1145/1718487.1718490.
Efron, M. (2010). Hashtag retrieval in a microblogging environment. SIGIR pp. 787–788. http://portal.acm.org/citation.cfm?id=1835449.1835616.
Ghosh, S., & Ghosh, K. (2016). Overview of the FIRE 2016 microblog track: Information extraction from microblogs posted during disasters. In: Working notes of FIRE 2016 - Forum for Information Retrieval Evaluation, Kolkata, India, December 7-10, 2016., pp. 56–61. http://ceur-ws.org/Vol-1737/T2-1.pdf.
Ghosh, S., Ghosh, K., Chakraborty, T., Ganguly, D., Jones, G.J.F., Moens, M. (eds.) (2017). Proceedings of the First International Workshop on Exploitation of Social Media for Emergency Relief and Preparedness co-located with European Conference on Information Retrieval, SMERP@ECIR 2017, Aberdeen, UK, April 9, 2017, CEUR Workshop Proceedings, vol. 1832. CEUR-WS.org. http://ceur-ws.org/Vol-1832.
Hiemstra, D. (2000). Using language models for information retrieval. Ph.D. thesis, University of Twente.
Imran, M., Castillo, C., Diaz, F., Vieweg, S. (2015). Processing social media messages in mass emergency: A survey. ACM Computing Surveys, 47(4), 67:1–67:38.
Ganesh, J., Gupta, M., Varma, V. (2016). Doc2sent2vec: A novel two-phase approach for learning document representation. In: SIGIR.
Jelinek, F., & Mercer, R.L. (1980). Interpolated estimation of markov source parameters from sparse data. In: Proceedings of the Workshop on Pattern Recognition in Practice.
Kim, H.K., Kim, H., Cho, S. (2017). Bag-of-concepts: Comprehending document representation through clustering words in distributed representation. Neurocomputing, 266(Supplement C), 336–352. https://doi.org/10.1016/j.neucom.2017.05.046. http://www.sciencedirect.com/science/article/pii/S0925231217308962.
Kusner, M.J., Sun, Y., Kolkin, N.I., Weinberger, K.Q. (2015). From word embeddings to document distances. In: Proceedings of the 32Nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, pp. 957–966. JMLR.org. http://dl.acm.org/citation.cfm?id=3045118.3045221.
Lau, J.H., & Baldwin, T. (2016). An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv:1607.05368.
Le, Q., & Mikolov, T. (2014). Distributed representations of sentences and documents. In: Proceedings of the 31st International Conference on International Conference on Machine Learning - Volume 32, ICML’14, pp. II–1188–II–1196. JMLR.org. http://dl.acm.org/citation.cfm?id=3044805.3045025.
MacKay, D.J., & Peto, L.C.B. (1994). A hierarchical dirichlet language model. Natural Language Engineering, 1, 1–19.
Massoudi, K., Tsagkias, E., de Rijke, M., Weerkamp, W. (2011). Incorporating query expansion and quality indicators in searching microblog posts. ECIR, 2011, 362–367.
Mikolov, T., Chen, K., Corrado, G., Dean, J. (2013a). Efficient estimation of word representations in vector space. arXiv:1301.3781.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J. (2013b). In Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., & Weinberger, K.Q. (Eds.), Distributed representations of words and phrases and their compositionality, (pp. 3111–3119). New York: Curran Associates, Inc. http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf.
Mikolov, T., Yih, W., Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations. In: NAACL HLT 2013.
Ounis, I., Macdonald, C., Lin, J., Soboroff, I. (2011). Overview of the trec-2011 microblog track. In: Proceeddings of the 20th Text REtrieval Conference (TREC 2011), vol. 32.
Ponte, J., & Croft, W. (1998). A language modeling approach to information retrieval. In: Proc. ACM SIGIR.
Porter, M.F. (1997). Readings in information retrieval. chap. An Algorithm for Suffix Stripping, (pp. 313–316). San Francisco: Morgan Kaufmann Publishers Inc. http://dl.acm.org/citation.cfm?id=275537.275705.
Robertson, S.E., Walker, S., Jones, S., Hancock-Beaulieu, M. (1994). Okapi at TREC-3. In: Proceedings of the Third Text REtrieval Conference (TREC 1994). NIST.
Varga, I., et al. (2013). Aid is out there: Looking for help from tweets during a large scale disaster. In: Proc. ACL.
Xing, C., Wang, D., Zhang, X., Liu, C. (2014). Document classification with distributions of word vectors. In: Signal and Information Processing Association Annual Summit and Conference (APSIPA), 2014 Asia-Pacific, pp. 1–5. https://doi.org/10.1109/APSIPA.2014.7041633.
Author information
Authors and Affiliations
Corresponding author
Appendix: Queries in the SMERP Collection
Appendix: Queries in the SMERP Collection
<top>
<num>SMERP-T1</num>
<title> WHAT RESOURCES ARE AVAILABLE</title>
<desc>Identify the messages which describe the availability of some resources.</desc>
<narr> A relevant message must mention the availability of some resource like food, drinking water, shelter, clothes, blankets, blood, human resources like volunteers, resources to build or support infrastructure, like tents, water filter, power supply, etc. Messages informing the availability of transport vehicles for assisting the resource distribution process would also be relevant. Also, messages indicating any services like free wifi, sms, calling facility etc. will also be relevant. In addition, any message or announcement about donation of money will also be relevant. However, generalized statements without reference to any resource would not be relevant.</narr>
</top>
<top>
<num>SMERP-T2 </num>
<title> WHAT RESOURCES ARE REQUIRED</title>
<desc> Identify the messages which describe the requirement or need of some resources.</desc>
<narr> A relevant message must mention the requirement / need of some resource like food, water, shelter, clothes, blankets, human resources like volunteers, resources to build or support infrastructure like tents, water filter, power supply, blood and so on. A message informing the requirement of transport vehicles assisting resource distribution process would also be relevant. Also, messages requesting for any services like free wifi, sms, calling facility etc. will also be relevant. In addition, messages asking for donation of money will also be relevant. However, generalized statements without reference to any particular resource would not be relevant.</narr>
</top>
<top>
<num> SMERP-T3</num>
<title> WHAT INFRASTRUCTURE DAMAGE, RESTORATION AND CASUALTIES ARE REPORTED</title>
<desc> Identify the messages which contain information related to infrastructure damage, restoration and casualties</desc>
<narr> A relevant message must mention the damage or restoration of some specific infrastructure resources, such as structures (e.g., dams, houses, mobile towers), communication facilities (e.g., roads, runways, railway), electricity, mobile or Internet connectivity, etc. Messages reporting injury or death of people will also be relevant. Generalized statements without reference to infrastructure resources would not be relevant.</narr>
</top>
<top>
<num>SMERP-T4</num>
<title> WHAT ARE THE RESCUE ACTIVITIES OF VARIOUS NGOs / GOVERNMENT ORGANIZATIONS</title>
<desc> Identify the messages which describe on-ground rescue activities of different NGOs and Government organizations.</desc>
<narr> A relevant message must contain information about relief-related activities of different NGOs and Government organizations engaged in rescue and relief operation. Messages that contain information about the volunteers visiting different geographical locations would also be relevant. Messages indicating that organizations are accumulating money and other resources will also be relevant. However, messages that do not contain the name of any NGO / Government organization would not be relevant.</narr>
</top>
Rights and permissions
About this article

Cite this article
Bandyopadhyay, A., Ganguly, D., Mitra, M. et al. An Embedding Based IR Model for Disaster Situations. Inf Syst Front 20, 925–932 (2018). https://doi.org/10.1007/s10796-018-9847-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10796-018-9847-6