
Abstract
The cost of Burn-In is a major concern for the testing of Automotive Systems-on-Chip (SoC). This paper highlights problematic aspects of a Burn-In flow and describes a two-layered adaptive technique that permits to optimize the stress application and strongly reduce BI test time. At the SoC level, the described methodology adaptively copes with FLASH erase time uncertainties; at the Automatic Test Equipment (ATE) level, the strategy relies on power monitors and tester intelligence. The paper reports experimental results on a SoC manufactured by STMicroelectronics; figures show an optimized usage of stress resources and demonstrates a reduction of 25% in the BI test time when using the proposed adaptive techniques.
Similar content being viewed by others


1 Introduction
The manufacturing test of an Integrated Circuit (IC) is a long duration flow that requires several test procedures to be applied at different stages of the assembly process. Several steps compose the test flow for a Safety Critical IC, and Fig. 1 illustrates a general overview of the whole process. Some common steps, performed for the entire production, consist of many Wafer Sort phases interleaved with some bake periods [5], before the packaging phase. A Final test phase at ambient temperature concludes the test for non-safety-critical devices.

Represents the manufacturing test process of electronic devices, including additional phases for safety-critical applications
Conversely, the test process continues for components used in safety-critical applications such as Automotive SoCs. Additional test steps are either the Burn-In (BI) or its enhancement called Test During Burn-In (TDBI), followed by a Final Test phase performed at hot (high temperature) and cold (low temperature). The purpose of the Burn-In is to screen out all chips that could show defects in their early life phase and bring the devices to the useful life phase in advance as the BI is accelerating aging. Burn-in is performed by an Automatic Test Equipment (ATE) having the ability to
-
provide high temperature,
-
electrically stimulate the device to stress the silicon and the package
BI is usually associated with long testing time aspect of the test economy that makes it a bottleneck of the entire IC manufacturing process. The overall duration of BI depends on several factors:
-
The composition of the device under test: for example, components like FLASH memories requires a very repetitive and extensive stress procedure, that consists of a sequence of up to thousands consecutive erase operations, each taking up to tens of seconds for MB-sized cuts [10, 12].
-
The manufacturing technology: it is required to apply an external stress for enough time, such as applying high temperature by means of a climatic chamber, to accelerate aging of IC materials according to Arrhenius law [8].
-
The defect types: it is needed to electrically stimulate the IC, while in the climatic chamber, in the right way, to target specific defects (both random and technology-dependent) that could appear in the early life stages of a device.
Nowadays, System-on-Chips for safety-critical applications, such as automotive, integrate large FLASH memory cuts, up to 10 MB and more; quality standards for FLASH mandate FLASH erase cycling, which consists in erasing the embedded FLASH memory up to hundreds of times. This is a procedure that occupies a significant phase of the electrical stress. Thus, this stress phase dominates the BI time for automotive products and can last for much more than half of the overall duration, including the stress of all other SoC components. Furthermore, the FLASH erase time is nondeterministic, it may vary from chip to chip and according to conditions of the environment. The latter is a serious concern as it may negatively affect the test time [7].
Another characteristic of devices used in safety-critical missions is the complexity and dimension of the digital logic. This portion of the SoC area needs strong functional stress, which is becoming today long and power consuming due to the increasing complexity.
The focus of this paper is on describing a methodology to reduce BI test time, working on the FLASH cycling phase and showing how to optimally parallelize structural (FLASH) and functional (CPU and Peripheral) stress phases. Other structural tests (like scan stress and BIST execution) are not considered in our approach, as they are occupying a relatively short amount of time with respect to the FLASH cycling and functional stress phases.
Our work starts from the most recent advances in the BI field, as over the past several decades engineers struggled trying to reduce BI costs. Highly parallelized solutions are commonly adopted to maximize the throughput of BI campaigns. Nevertheless, BI equipments, managing thousands of devices in parallel, show limitations concerning power supply capabilities that are required for such numbers; if they are not able to manage all device in parallel when performing electrical stress, a solution needs to be implemented, such as to divide the device population into several clusters that run sequentially. A key point to address this challenge is to devise a proper scheduling that minimizes the duration of the procedure while considering power limitation of the tester.
Additionally, techniques able to parallelize BI stress phases have been explored [7], by isolating working domains and making them operate in parallel.
The manuscript addresses the problem of reducing burn-in time by describing a two-layered strategy.
First, it proposes to provide the Device Under Test (DUT) with enough smart capabilities that allow it to save time by adapting the test execution flow to special asynchronous operations performed during the BI phase. These features become relevant during the FLASH Erase Cycling phase where hundreds of erase operations are performed and are characterized by a variable duration that, depending on the temperature, can span from 25 to 45 s. A proper management of the erase time variability permits to save precious time.
Finally, the paper describes a technique to adaptively manage the execution of the BI flow to decrease and optimize the overall test time without violating power constraints. This is obtained by using BI tester facilities that allow to effectively schedule functional stress procedures performed in parallel with FLASH erases.
2 Background
The purpose of the Burn-In (BI) process is to give rise to infant mortalities (early life latent failures) that naturally affect a population of electronic devices [8]. Figure 2 illustrates the bathtub curve, which shows the presence of early life latent failures on its left side. These failures are mainly associated to intrinsic faults within the silicon, assembly errors or damages resulting from inappropriate handling. The Burn-In approach takes advantage of elevated temperatures able to accelerate the appearance rate of infant defects that arise during this part of life of the device. BI ensures that the shipped devices will not show other defects than random failures during the useful life phase, where the failure rate is considered constant.

The failure curve of an electronic component also known as Bathtub curve
The first attempt to reduce the cost of the BI process is based on the massive stimulation of a large set of devices at the same time. In fact, the BI phase is a highly parallelized process where devices are inserted into a special PCB for test called Burn-In Board (BIB) that can host hundreds of assembled devices. A BI tester is composed of a climatic chamber that accommodates a set of BIBs, a Driver Interface and a Host PC that manages the testing procedures for all the chips in parallel. Figure 3 illustrates a typical scenario.

a shows a Burn In Board and while figure ( b ) shows a BI Tester major component
During a Burn-In session, Systems-on-Chip (SoCs) for automotive applications undergo several types of stress procedures as depicted in Fig. 4. Internal stress procedures are aimed at providing a junction level stress [3] by raising the internal temperature and making the circuit toggle, thus complementing the external acceleration factor provided by the high temperature. In a common flow, the great majority of the test time during BI is dedicated to embedded FLASH memories stress and test phases, which are needed to ensure strict quality standards imposed by the automotive market. This technique is known as FLASH erase cycling and it is employed to exacerbate faults in the embedded flash memory modules of an IC. Gate stress [1, 9, 11, 14] for the digital parts is also an objective and, depending on the on-chip Design-for-Test infrastructure, it can be applied using scan chains, Built-in Self-Test engines, functional programs or a combination of them. Figure 4.A illustrates a traditional flow, where BI phases are fully serialized.

Illustrates the Burn-In process and details on its phases
As shown in Fig. 4 B, the FLASH erase cycling could be parallelized with functional stress procedures performed by the embedded processor cores. The FLASH erase operation is usually quite long (tens of seconds according to the size of the memory bank and the temperature at which the erase is performed) and, during its execution, it leaves the processor(s) free to perform other tasks such as functional stress or test procedures on the other modules of the SoC.
The parallelization approach brings a significant advantage in terms of BI time reduction [4], but may provoke power issues since parallel stress can show excessive current consumption. The parallelization technique is the base of the approach proposed in the next section, which deals with FLASH erase time uncertainty and stress power management.
3 Optimized Burn-in of Automotive SoC
This paper proposes a two-layered technique to optimize the stress application during the FLASH cycling phase and to reduce dramatically the length of the overall BI test phase; adaptive techniques are working both at chip and test equipment level.
At chip level, an adaptive technique manages the duration of stress and test sequences during the FLASH cycling phase. The time window management is strongly dependent on the time required to perform each single FLASH erase. This time may vary significantly from chip to chip, the erase time may in fact span from 25 s to 45 s, thus introducing a significant time overhead in the BI test phase. Adaptiveness is introduced on-chip in the form of a prediction algorithm able to estimate the duration of the next erase. In this way, every chip undergoing BI becomes aware of the actual erase time trend and can take over the traditional ATE-dependent flow, making internal decisions more effectively, autonomously scheduling the components of the stress and test suite, thus enabling a better usage of the test time.
Additionally, at the ATE level, an adaptive technique is employed to activate functional stress procedures to be run in parallel to the erase operations on a subset of the DUTs hosted on the BIBs. The proposed ATE architecture can decide on-the-fly the most suitable order of functional stress procedures to maximize the number of devices running in parallel with respect to the power budget of the tester. Current solutions work off-line and statically determine the largest subset of devices that can be driven in parallel without incurring power issues. In our approach, the tester itself decides which stress to run on which device according to a power-aware scheduling algorithm.
3.1 Adaptive Stress/Test Scheduling On-Chip
The need of adaptiveness at chip level is mainly related to the quality of the functional stress process. As mentioned above, the FLASH erase time changes from chip to chip and may vary even for the same device (i.e. two subsequent erases of the same memory bank may have time differences of several seconds). Moreover, FLASH erase timing strongly depends on the ambient temperature at which erase operations are performed, meaning that there is a significant difference between the duration of an erase performed at ambient temperature with respect to the same operation performed in a chamber with controlled temperature, where the temperature goes from 25 °C to 125 °C. Since the FLASH erase process is self-regulating, once the FLASH controller triggers it, other software can run in parallel until the completion is signaled through a value change of a dedicated flag bit in the flash status register.
This variability offers an opportunity for the implementation of an adaptive solution to entirely exploit the available test time window at its best. The proposed method allows to internally predict the duration of the erase, thus making the device aware of the time budget and to use it as effectively as possible. This allows the device to adapt accordingly the duration of the functional stress procedures; Fig. 5 illustrate the generic cases, first showing how a stand-alone flow for functional stress and erase works, then illustrating three different scenarios. In 5.a) the desired scenario is depicted, where the functional stress runs in parallel to the erase procedure, interleaved by a functional test scheduled immediately before the end of the erase; in this case, the system is ready to trigger a new flash erase as soon as possible and the time spent waiting for the completion of the erase is minimized. On the contrary, Fig. 5 b) shows a case where the time budget is not used effectively: functional stress phases are applied in a conservative way to always fit the erase window. Finally, the worst scenario is shown in Fig. 5c) where a time window longer than the real erase duration is considered; a new stress routine, starting right before the erase completion, will execute until the end, postponing the triggering of the next erase and therefore delaying the overall test duration.

Compare the stand-alone vs. parallel execution with scenarios. The parallel case shows possible advantages or drawbacks of the technique
The next paragraph describes the key ideas to monitor the FLASH erase variability and it introduces an implementation of a simple prediction algorithm used in our test case.
3.1.1 Exponential Average
An effective and easy way to predict the FLASH erase time, thus efficiently using the time window for functional stress/test applications was inspired by CPU scheduling algorithms that implement the exponential average equation as it is presented in [13].
Given a DUT and the impossibility to know the FLASH erase time a priori, a guess, close enough to the real duration, is needed. From our experimental analysis, it resulted that is very likely that the current FLASH erase time will follow the trend of the previous ones. Then, it is possible to estimate an approximate value for the FLASH erase window and allocate the right number of cycles of stress/test for the predicted duration. Similarly, the duration of a specific operation on a CPU could be obtained by means of an exponential average of previous alike operations. The following formula defines the exponential average estimation:
where tn is the length of n-th operation, τn + 1 is the next predicted value for the next operation and α is a coefficient between 0 and 1. tn gives the more recent information on the effective duration, τn represents the past estimation of the duration of the n-th operation, α controls the influence that previous predictions have on the next one. If α tends to 0, τn + 1 is heavily affected by τn, the recent prediction history has a considerable effect. Inversely, if α tends to 1, τn + 1 tends to tn, the prediction is influenced more by the effective duration of the last operation. When α is 0.5, estimated and effective values have the same weight. t0 and τ0 are the starting values for the predictor and strongly affect the speed at which the algorithm will produce an acceptable estimation.
From the basic form it is possible expand τn + 1 as follows:
α is less than 1 so 1-α is less than 1 too, it easy to understand that every coefficient has a value lower than the previous one [13]. This method estimates well the duration of next FLASH erase because it correlates the prediction with the history of the system.
3.1.2 Implementation of On-Chip Scheduler
A real-time scheduler has been embedded as test and stress manager in the actual test pattern loaded into the DUT on-chip memory at test time. The scheduler can dynamically adapt to the FLASH erase duration and schedule test and stress routines to minimize the time spent on polling the status register that signals the completion of the flash erase. The time window forecast is carried out through an exponential averaging estimation that takes care of previous effective erase times and the gap with respect the predicted one. A weight parameter α is used to leverage how much the predicted result is dependent on the effective measured erase time or on the last forecasted duration. The equation that regulates the prediction is
The speed with which the algorithm converges to an acceptable value is strongly dependent on the initial values (t0 and τ0) that are provided as starting points for the first estimation. Besides, a constant number of clock cycles β is always added to the prediction as a guard band to never outmatch the effective erase time threshold, because the key is to proceed and triggering the next erase as soon as the previous one terminates.
Once the next erase window is estimated within an acceptable error, the scheduler can effectively allocate test time and stress time since the execution times of those routines has been previously characterized once in the early stages of the functional test program and their values, expressed in clock cycles, have been stored for future use. If the prediction is accurate enough, less time is spent in constantly checking the completion of the erase phase and a better and uniform functional stress is executed in parallel to the flash erase.
3.2 BI Tester Adaptive Facilities
A BI tester requires adaptive facilities to maintain a high parallelization level, which is a key in order to decrease the global test time and cost. As explained in section 2, a high parallelization level characterizes the BI flow and this feature allows a massive test of many DUTs for test cost reduction. There are several critical steps that need to be followed concerning the validation of power consumption profile during the BI because it is mandatory to ensure that the power budget of ATE drivers can cover the BI power demand. The problem arises due to the enhancement and scaling of nowadays technology nodes. New generations devices usually consume more power than the actual generation i.e. a multicore device requires higher power than a single core. Power budget might be insufficient, and a highly parallelized BI processes may not be guaranteed without an enhancement or even a complete replacement of ATE drivers. In this case, the validation phase reduces the parallelization and the BI cost increases consequently. This is the main reason that lead us to find a solution to maintain a high parallelization with the available power resources.
Nowadays, test engineers typically schedule the activation of DUTs for every BI phase statically, solution that often leads to a high-power consumption. A common solution is a group partition of the DUTs present on the BIB and execute the BI phase one group at a time. This kind of scheduling takes place off-line. In this way, the power demand of DUTs is under control, but the BI test time and cost increases as a drawback.
A dynamic scheduling of resources may allow a greater time save. A novel power management approach is an effective solution to increase the overall performance of ATE and to finally reduce BI time. Figure 6 gives an idea of possible benefits. Six DUT (DUT1, DUT2, …, DUT6) must execute a suite of functional stress tests (T1, T2, …, T4) in parallel with FLASH erase and each test has its own power consumption profile. Figure 6a shows the current static approach to perform a power-aware test by means of Sectors and we refer to this strategy as Sector Policy while Fig. 6b illustrates the possible benefits introduced by means of a dynamic test scheduling and we refer to this methodology as On-Line Scheduling Policy. In the Sector Policy, DUTs are grouped in different sectors (Sector1, Sector2) and tests run on each DUT one after the other. As it can be seen, there might be a significant waste of time due to the poorly managed power resources. This does not happen with the On-Line Scheduling Policy where the key idea is a reduction of the test time by sharing the power resources between remaining tests and not between DUTs.

Compares the sector and on-line scheduling policies with an example. Given 6 different DUT which must perform 6 different tests the On-line scheduling methods reduces the whole test
The main issue of the static strategy is that the allocation of power resources for the execution of the test suite is made in advance. This implies an over allocation of the power supply for each DUT because it is necessary to guarantee, at least, the power needed for the test that consumes the most. The schedule of tests, instead, can be performed off-line, but this remains a major challenge given the non-negligible probability of power hazard due to the high parallelization. For this main reason, the best way to share the power resources is by adopting an on-the-fly solution.
3.2.1 On-Line Schedule Policy on Burn-in ATE
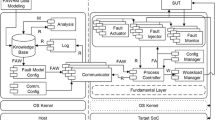
ATE needs some modifications to achieve better performance concerning power management with a better allocation of shared resources and avoidance of risks for the whole system. Figure 7 shows a suggested architecture. Differently from the traditional solutions, the paper proposes an ATE-Scheduler on the Processing Unit and a Power Monitor between the DUTs and the Processing Unit. The Scheduler is aware of the impact of power and current consumption of the test phases and it manages the resources allocation. The Power Monitor is a set of current and voltage sensors, which measure the electrical parameters related to the consumption of DUTs. Power Monitor transmits the sampled values to the ATE-Scheduler to check the available power supply. In addition, Power Monitor alerts the Processing Unit if there is an incumbent power-related danger due to an anomalous power consumption by any DUT.

Shows proposed architecture for a Burn-In ATE to address current limits
The scheduling can address the problem when it knows the amount of shared resources and the resources required by all jobs, but it does not know the time required to perform those jobs. The current computation needs accurate awareness in terms of power availability, thus enabling to take decisions based on consumption monitoring. A greedy solution, which is inspired by the scheduler proposed in [14], is chosen to handle the complexity of the problem.

First, the ATE-Scheduler sorts all the tests that DUTs have to execute in decreasing order, according to their power consumption, in a list L. Then, it chooses the from L test with the highest power consumption, which can be covered by the available resources. Afterward, the ATE-Scheduler locks the necessary resources, drops the test from the list, starts the test and waits for a feedback from the Power Monitor. This process is repeated until it is possible to schedule a test. When resources run out, the ATE-Scheduler waits until a test is complete. When a test finishes, the ATE-Scheduler releases the allocated resources and it searches again a schedulable test inside L.
4 Experimental Results
A case study has been considered to demonstrate the effectiveness of the proposed solutions. Suggested approaches have been experimented on a 90 nm CMOS technology SoC employed in safety critical automotive systems and manufactured by STMicroelectronics. The embedded processor is a 32-bit dual issue Power Architecture® core coupled with two levels of memory hierarchy consisting of 8 KB of instruction cache, backed up by 192 KB on-chip SRAM and up to 4 MB of internal FLASH. This chip usually undergoes BI due to the safety-critical nature of its target applications.
The case of study examines the BI process of 80 DUT in parallel in the erase cycling phase. This segment of BI erases the FLASH 500 times. The erase duration is random and, when operating at 125 °C, requires between 35 to 45 s to be completed. TEN different stress programs are scheduled during the erase cycling phase, so each stress program can be scheduled 50 times and there is not a required order. These programs are short and are repeated to the whole erase duration. Table 1 summarizes the current consumption, the duration and the target of the stress programs. The erase cycling process is performed at an operating frequency of 128 MHz and the SoC supply voltage is 1.32 V. These values are close to the circuit limits and allow to increase and improve the aging acceleration.
Two different experiments have been performed to certify the validity of the proposed methodologies, one concerning the on-chip adaptive stress and test scheduling and the other regarding BI tester adaptive mechanisms.
The first experiment evaluates the efficiency of the on-chip scheduler and shows an improvement concerning the uniformity of the stress procedure. The experiment routine consists in the execution of stress/test programs that reside in RAM and that can run in parallel with FLASH erases as described in section 2.1. Eight different stress programs, presented in [3], were used for the trial, each of which targets specific modules.
The second experiment estimates the advantage of adaptive features on a BI ATE and it demonstrates a considerable test time reduction. This experiment is based on a model that has been built and simulated on MATLAB.
4.1 Test Scheduling On-Chip Results
The analyzed cycling is composed by 20 consecutive erase instances. Experimental results show that the implemented adaptive scheduler can guess the next erase window with an accuracy of around 3.13% that on a mean erase time of 27.67 s translates to a ± 0.87 s average error. Cases in which the predicted erase is longer than the effective are uncommon and the occurrence is estimated in less than one wrong prediction over 20 attempts. The experiment results show that the proposed on-chip scheduler allows improving the stress ability for two reasons. On one hand, the prediction of the erase time is usually lower than the effective erase; this means that the total test time does not increase. On the other hand, the gap between the predicted and effective erase time decreases and it remains stable during the experiments; in this way, stress/test procedures can take advantage of the complete FLASH erase duration. Experimental data related to the two aspects just described are reported in Fig. 8.

Fig. 5 illustrate a graphical result of the prevision made by the Adaptive Scheduling On-Chip using an erase cycle with 20 instances
A key benefit of this approach is that the adaptive scheduling strategy can be easily scaled to an indefinite number of DUTs. Moreover, internal scheduling processes run without the need of the intervention of the ATE making each device autonomous in its execution.
4.2 BI ATE Adaptive Experiments
The proposed BI ATE adaptive solution have been evaluated with a model extrapolated from the simulation of a regular FLASH erase cycling phase. The model has been extracted monitoring more than 1200 FLASH erase cycling. This model implements the proposed ATE on-line scheduling policy solution with on-chip scheduler and compares the results using the sector policy.
Data, collected during Burn-In experiments, is the starting point of our computations. In the case analyzed, a set of 8 functional programs runs on the processor core while the FLASH memory executes the erase process. We have collected the different erase times on a large set of DUTs and the different power consumptions during the execution of different programs. Then, the electrical characteristics of the BI drivers have been evaluated to figure out the available power supply capabilities.
Finally, the time required for traditional sector-based and the proposed policies have been evaluated. The model performs an analysis between the Sector Policy and On-Line Scheduling.
Figure 9 shows the distribution of test time during the FLASH erase cycling after a considerable number of simulations with the previous and the proposed methodologies. It is possible to observe that the proposed BI ATE adaptive schema considerably reduces the test duration. The average test duration for Sector Policy is 13.45 h while for the On-Line Scheduling Policy is 9.83 h leading to a remarkable 25% reduction in test time. In addition, Table 2 compares traditional scheduling metrics for all the tests using the sector and the on-line policies:
-
Waiting Time: the sum of the wait time for all the test instances
-
Turnaround Time: time between ready state and end of all the test instances
-
Response Time: time between ready state and first instance of the test

Compares the Test Time Distributions of Sector and On-Line Scheduling Policies
The On-Line policy reduces the value of the Turnaround Time metric for all test allowing to decrease the required time for all tests. The On-Line scheduling policy reduce the Wait Time only for the test with a strong current consumption that are scheduled as soon as possible avoiding a bottle neck. The On-line scheduling shows a worse response time compared Sector scheduling due to the round robin characteristics of Sector policy.
5 Conclusion
This paper introduces two new approaches to perform an adaptive management of functional stress and test run in parallel with the FLASH erase cycling phase of the BI flow. At chip level the adaptiveness is implemented by means of an on-chip scheduler that makes use of the available time in an optimal way given that the FLASH erase time varies along time; at ATE level the adaptive solution employs a new architecture which is aware of the power demand in this highly parallelized scenario and it is able to schedule the right test at every given time.
Along the paper, a possible solution for optimizing the stress phase at chip level and a parallelization of tests by sharing the power resources are investigated. The approach at chip level allows to perform the stress process by predicting the FLASH erase duration with an error of 3.13% and trying to minimize the time between one erase and another. The approach at ATE level exploits a novel architecture that allows performing the BI phase in less time, with a reduction of 25% with respect to the current duration, trying to minimize the risk of power hazards for both the tester and the DUTs.
References
Aghaee N, Peng Z, Eles P (2014) An efficient temperature-gradient based burn-in technique for 3D stacked ICs, in Proc. design, automation and test in Europe conference and exhibition (DATE), 1–4
Appello D, Bernardi P, Cagliesi R, Giancarlini M, Grosso M (2008) An innovative and low-cost industrial flow for reliability characterization of SoCs, in Proc. 13th European test symposium, Verbania, 140-145
Appello D, Bernardi P, Giacopelli G, Motta A, Pagani A, Pollaccia G, Rabbi C, Restifo M, Ruberg P, Sanchez E, Villa CM, Venini F (2017) A comprehensive methodology for stress procedures evaluation and comparison for burn-in of automotive SoC, in proc. Design Automation & Test in Europe, 2017. Lausanne, 646-649
Appello D, Bernardi P, Bugeja C, Cantoro R, Pollaccia G, Restifo M, Sanchez E, Venini F (in press) An optimized test during burn-in for automotive SoC. in IEEE Design & Test of computers
Bahukudumbi S, Chakrabarty K, Kacprowicz R (2008) Test scheduling for wafer-level test-during-burn-in of Core-based SoCs, in Proc. design, automation and test in Europe, 1103–1106
Benso A, Bosio A, Carlo SD, Natale GD, Prinetto P. (2006) ATPG for dynamic burn-in test in full-scan circuits, in Proc. 15th Asian test symposium, Fukuoka, 75-82
Bernardi P. et al. (2017) A DMA and CACHE-based stress schema for burn-in of automotive microcontroller, in Proc. 18th IEEE Latin American test symposium (LATS), Bogota, 1-6
Birolini A (1999) Reliability engineering, theory and practice, SpringerVerlag, 3rd edition
Carulli JM, Anderson TJ (2006) The impact of multiple failure modes on estimating product field reliability. IEEE Des Test Comput 23(2):118–126
Fayrushin A, Kwang Soo S, Jong Hoon N, Sung Hoi H, Jung Dal C, Kinam K (2009) The new program/erase cycling degradation mechanism of NAND flash memory devices, in Proc. International Electron Devices Meeting (IEDM), Baltimore, MD, 1–4
Pouget J. et al. (2003) An efficient approach to SoC wrapper design, TAM configuration and test scheduling, in Proc. 8th IEEE European Test Workshop, 51-56
Sarson P, Schatzberger G, Leisenberger F (2017) Fast bit screening of automotive grade EEPROMs - continuous improvement exercise, IEEE Transactions on VLSI Systems 25(4):1250-1260
Silberschatz A, Galvin P, Gagne G. Operating system concepts, John Wiley & Sons. Inc
Zakaria MF, Kassim Z, Ooi MPL, Demidenko S (2006) Reducing burn-in time through high-voltage stress test and Weibull statistical analysis. IEEE Des Test Comput 23(2):88–98
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: S. Demidenko
Rights and permissions
About this article

Cite this article
Appello, D., Bernardi, P., Bugeja, C. et al. Adaptive Management Techniques for Optimized Burn-in of Safety-Critical SoC. J Electron Test 34, 43–52 (2018). https://doi.org/10.1007/s10836-018-5705-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10836-018-5705-1