
Abstract
Text search engines are inadequate for indexing and searching XML documents because they ignore metadata and aggregation structure implicit in the XML documents. On the other hand, the query languages supported by specialized XML search engines are very complex. In this paper, we present a simple yet flexible query language, and develop its semantics to enable intuitively appealing extraction of relevant fragments of information while simultaneously falling back on retrieval through plain text search if necessary. Our approach combines and generalizes several available techniques to obtain precise and coherent results.


Similar content being viewed by others


Notes
Note that extant search engines analyze only the content associated with the META-element, the TITLE-element, etc., and information implicit in the text fonts and anchor text (link analysis), for relevance ranking an HTML document (Brin and Page 1998).
Our use of the terms “precise” and “precision” is meant to capture the aspect of “compactness” or “minimal size complete coverage” or “specificity”, and should not be confused with the standard IR term “precision” meaning a fraction of retrieved documents (or XML fragments) that are relevant to the searcher.
Word adjacency information can be captured using phrases in the standard way, that is, delimited by double quotes. However, there is no explicit support for specifying proximity information or “window of separation” between two words, in the query language.
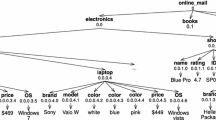
In this paper, a subtree is always rooted at an element node. The root node associated with a subtree of a tree (resp. a subelement of an element) is a descendant of the root node associated with the tree (resp. element).
From the perspective of specifying the query semantics, there is no harm in allowing internal links. These have been excluded here only because our implementation prematurely committed to tree structure, thereby requiring some duplication for testing with DAGs generated by IDREFs. An alternative implementation allowing multiple parents can enable querying of more general XML documents.
Ironically, the declarative specification of the completeness criteria seems complex. However, its purpose, as illustrated through the example, is clear and its implementation, as discussed later, is clean.
References
Antoniou, G., & van Harmelen, F. (2004). A Semantic web primer. The MIT Press
Bailey, J., Bry, F., Furche, T., & Schaffert, S. (2005). Web and semantic web query languages: A survey. In N. Eisinger & J. Maluszynski, (Eds.), Reasoning Web, First International Summer School 2005, LNCS 3564 (pp. 35–133).
Berger, S., Bry, F., Schaffert, S., & Wieser, C. (2003). Xcerpt and visXcerpt: from pattern-based to visual querying of XML and semistructured data. In Proceedings of 29th International Conference on Very Large Data Bases (pp. 1053–1056).
Brin, S., & Page, L. (1998). The anatomy of a large-scale hypertextual web search engine. In Proceedings of the seventh international conference on world wide web (pp. 107–117).
Carmel, D., Maarek, Y. S., Mass, Y., Efraty, N., & Landau, G. M. (2002). An extension of the vector space model for querying XML documents via XML fragment. The ACM SIGIR Second Workshop on XML and IR.
Catania, B., Maddalena, A., & Vakali, A. (2005). XML document indexes: A classification. In IEEE internet computing (pp. 64–70).
Chamberlin, D., Robie, J., & Florescu, D. (2000). Quilt: An XML query language for heterogeneous data sources. In Proceedings of WebDB 2000 Conference, Lecture Notes in Computer Science (Vol. 1997, 2000, pp. 1–25).
Cohen, S., Kanza, Y., Kimelfeld B., & Sagiv, Y. (2005). Interconnection semantics for keyword search in XML. In The 2005 ACM international conference on information and knowledge management (CIKM) (pp. 389–396). Bermen (Germany).
Cohen, S., Mamou, J., Kanza, Y., & Sagiv, Y. (2003). XSEarch: A semantic search engine for XML. In The 29th international conference on very large databases (VLDB) (pp. 45–56).
Deutsch, A., Fernandez, M., Florescu, D., Levy, A., & Suciu, D. (1998). XML-QL: A query language for XML. In Proceedings of the 8th WWW conference, http://www.w3.org/TR/1998/NOTE-xml-ql-19980819/, Retrieved 10/2007.
Fensel, D., Hendler, J., Lieberman, H., & Wahlster, W. (Eds.) (2003). Spinning the semantic web: Bringing the world wide web to its full potential. The MIT Press.
Florescu, D., Kossmann D., & Manolescu, I. (2000). Integrating keyword search into XML query processing. Computer Networks: The International Journal of Computer and Telecommunications Networking, 33(1–6), 119–135, June.
Fuhr, N., & Grojohann, K. (2001). XIRQL: A query language for information retrieval in XML documents. In Proceedings of the 24th ACM SIGIR Conference (pp. 172–180).
Grabs, T., & Schek, H. (2002). Generating vector spaces on-the-fly for flexible XML retrieval. In The ACM SIGIR Second Workshop on XML and IR.
Guo, L., Shao, F., Botev C., & Shanmugasundaram, J. (2003). XRANK: Ranked keyword search over XML documents. In Proceedings of ACM SIGMOD (pp. 16–27).
Lalmas, M., & Tombros, A. (2007). Evaluating XML retrieval effectiveness at INEX. ACM SIGIR Forum, 41(1), 40–57, June.
Li, Y., Yu, C., & Jagadish, H. V. (2004). Schema-Free XQuery. In Proceedings of the VLDB conference (pp. 72–83).
Manning, C. D., Raghavan, P., & Schtze, H. (2007). Introduction to information retrieval, http://informationretrieval.org/, Retrieved 10/2007.
Meyer, H., Bruder, I., Weber, G., & Heuer, A. (2003). The Xircus Search Engine.
Schlieder, T., & Meuss, H. (2002). Querying and ranking XML documents. Journal of the American Society for Information Science and Technology, 53(6), 489–503.
Scott, M. L. (2006). Programming language pragmatics. Morgan Kaufmann Publishers, 2nd Edn.
Theobald, A., & Weikum, G. (2002). The index-based XXL search engine for querying XML data with relevance ranking. In 8th International Conference on Extending Database Technology (EDBT), LNCS 2287 (pp. 477–495).
Thirunarayan, K., & Immaneni, T. (2006). Flexible querying of XML documents. In F. Esposito & Z. Ras (Eds.), Proceedings of the 16th international symposium on methodologies for intelligent systems, (LNAI/LNCS) (Vol. 4203, pp. 198–207), September.
Acknowledgements
We thank the referees for their valuable feedback.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Thirunarayan, K., Immaneni, T. A coherent query language for XML. J Intell Inf Syst 32, 139–162 (2009). https://doi.org/10.1007/s10844-007-0051-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-007-0051-2