
Abstract
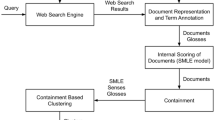
This paper details a modular, self-contained web search results clustering system that enhances search results by (i) performing clustering on lists of web documents returned by queries to search engines, and (ii) ranking the results and labeling the resulting clusters, by using a calculated relevance value as a degree of membership to clusters. In addition, we demonstrate an external evaluation method based on precision for comparing fuzzy clustering techniques, as well as internal measures suitable for working on non-training data. The built-in label generator uses the membership degrees and relevance values to weight the most relevant results more heavily. The membership degrees of documents to fuzzy clusters also facilitate effective detection and removal of overly similar clusters. To achieve this, our transduction-based clustering algorithm (TCA) and its fuzzy counterpart (FTCA) employ a transduction-based relevance model (TRM) to consider local relationships between each web document. Results from testing on five different real-world and synthetic datasets results show favorable results compared to established label-based clustering algorithms Suffix Tree Clustering (STC) and Lingo.























Similar content being viewed by others

References
Carpineto, C., Osinski, S., Romano, G., & Weiss, D. (2009). A survey of web clustering engines. ACM Computing Surveys, 41, 17:1–17:36.
Carpineto, C., & Romano, G. (2008). Odp239 test collection. Accessed Sept 2010. http://credo.fub.it/ambient.
Crabtree, D., Gao, X., & Andreae, P. (2005). Standardized evaluation method for web clustering results. In Proceedings of the 2005 IEEE/WIC/ACM international conference on web intelligence.
Cutting, D. R., Karger, D. R., Pedersen, J. O., & Tukey, J. W. (1992). Scatter/gather: A cluster-based approach to browsing large document collections. In Proceedings of the 15th annual international SIGIR conference on research and development in information retrieval.
Demartini, G., Chirita, P. A., Brunkhorst, I., & Nejdl, W. (2008). Ranking categories for web search. In Lecture notes in computer science 4956 (pp. 564–569). Springer.
Ferragina, P., & Gulli, A. (2005). A personalized search egnine based on web-snippet hierarchical clustering. In Special interest track and posters of the 14th international conference on World Wide Web.
Geraci, F., Pellegrini, M., Maggini, M., & Sebastiani, F. (2006). Cluster generation and cluster labelling for web snippets. In Lecture notes in computer science 4209 (pp. 25–36). Springer.
Hammouda, K., & Karray, F. (2000). A comparative study of data clustering techniques. Ph.D. thesis, University of Waterloo.
Hearst, M. A. (2006). Clustering versus faceted categories for information exploration. Communications of the ACM, 49(4), 59–61.
Janruang, J., & Kreesuradej, W. (2006). A new web search result clustering based on true common phrase label discovery. In Proceedings of the international conference on computational inteligence for modelling control and automation and international conference on intelligent agents web technologies and international commerce.
Kaki, M. (2005). Findex: Search result categories help users when document ranking fails. In Proceedings of the SIGCHI conference on human factors in computing systems.
Lewandowski, D. (2008). Search engine user behaviour: How can users be guided to quality content? Information Services and Use, 28(3/4), 261–268.
Lewis, D. D. (2004). (2004). Reuters-21578 text categorization test collection. Accessed Sept 2010. http://www.daviddlewis.com/resources/testcollections/reuters21578/.
Matsumoto, T., & Hung, E. (2010). Fuzzy clustering and relevance ranking of web search results with differentiating cluster label generation. In 2010 IEEE world conference on computational intelligence.
Mecca, G., Raunich, S., & Pappalardo, A. (2007). A new algorithm for clustering search results. Data and Knowledge Engineering, 62, 504–522.
Mendes, M. E. S., & Stacks, L. (2003). Evaluating fuzzy clustering for relevance-based information access. In Proceedings of the IEEE international conference on fuzzy systems.
Osinski, S., & Weiss, D. (2005). A concept-driven algorithm for clustering search results. IEEE Intelligent Systems, 20(3), 48–54.
Stefanowski, J., & Weiss, D. (2003). Carrot2 and language properties in web search results clustering. In Lecture notes in computer science 2663 (pp. 240–249). Springer.
van Rijsbergen, C. J. (1979). Information retrieval. Butterworth
Xiao, L., & Hung, E. (2008). Clustering web-search results using transduction-based relevance model. In IEEE 1st pacific-asia workshop on web mining and web-based application 2008.
Yager, R. R., & Filev, D. P. (1994). Approximate clustering via the mountain method. IEEE Transactions on Systems, Man and Cybernetics, 24, 1279–1284.
Zamir, O., & Etzioni, O. (1998). Web document clustering: A feasibility demonstration. In Proceedings of the 21st annual international sigir conference on research and development in information retrieval.
Zhang, G., Liu, Y., Tan, S., & Cheng, X. (2007). A novel method for hierarchical clustering of search results. In Proceedings of the 2007 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology—Workshops.
Zhu, X., & Ghahramani, Z. (2002). Learning from labeled and unlabeled data with label propagation. Tech. rep., Carnegie Mellon University.
Author information
Authors and Affiliations
Corresponding author
Additional information
The work described in this paper was partially supported by grants from the Research Grants Council of the Hong Kong Special Administrative Region, China (Project No. PolyU 5191/09E, PolyU 5182/08E, PolyU 5174/07E, PolyU 5181/06E, G-U524).
Rights and permissions
About this article
Cite this article
Matsumoto, T., Hung, E. A transduction-based approach to fuzzy clustering, relevance ranking and cluster label generation on web search results. J Intell Inf Syst 38, 419–448 (2012). https://doi.org/10.1007/s10844-011-0161-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10844-011-0161-8