
Abstract
The LASSO problem has been explored extensively for CT image reconstruction, the most useful algorithm to solve the LASSO problem is the FISTA. In this paper, we prove that FISTA has a better linear convergence rate than ISTA. Besides, we observe that the convergence rate of FISTA is closely related to the acceleration parameters used in the algorithm. Based on this finding, an acceleration parameter setting strategy is proposed. Moreover, we adopt the function restart scheme on FISTA to reconstruct CT images. A series of numerical experiments is carried out to show the superiority of FISTA over ISTA on signal processing and CT image reconstruction. The numerical experiments consistently demonstrate our theoretical results.
Similar content being viewed by others
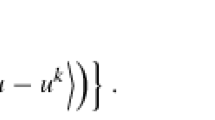

1 Introduction
LASSO (least absolute shrinkage and selection operator) is a regression analysis method that has been explored extensively for computed tomography (CT) image reconstruction, due to the potential of acquiring CT scans with lower X-ray dose while maintaining image quality. The LASSO problem, i.e. \(L_1\) norm regularized least squares problem is:
where \(A\in \mathbb {R}^{M\times N}\) is a measurement matrix, \(\varvec{b}\in \mathbb {R}^{M}\) is an observation, \(\Vert \cdot \Vert \) denotes the Euclidean norm, \(\Vert \varvec{x}\Vert _{1}=\sum _{i=1}^{n}|x_{i}|\) is the \(L_{1}\) norm and \(\lambda >0\) is a regularization parameter. It is well known that the LASSO problem is a convex optimization problem. Hence, there exist many exclusive and efficient algorithms, for instance, interior-point method Chen et al. (2001), least angle regression Efron et al. (2004), augmented lagrangian method (ALM) Yang et al. (2013) and iterative shrinkage thresholding algorithm (ISTA) Donoho (1995).
Due to the increasing demand for solving large-scale convex optimization problems, the accelerated gradient algorithm Nesterov (1983) has attracted much attention. By introducing the idea of accelerated gradient algorithm to ISTA, Beck and Teboulle have proposed a fast iterative shrinkage–thresholding algorithm Beck and Teboulle (2009) to solve the following problem:
where f is a smooth convex function and g is a continuous function but possibly nonsmooth. It is clear that (2) includes the LASSO problem as a special case.
It is well known that FISTA provides a global convergence rate of \(\mathcal {O}(1/k^2)\) compared to the rate of \(\mathcal {O}(1/k)\) by ISTA, where k is the iteration number Beck and Teboulle (2009). Recently, Tao et al. (2016) have established local linear convergence rates for both ISTA and FISTA on the LASSO problem under the assumption that the problem has a unique solution satisfying strict complementarity. Johnstone and Moulin (2015) have also shown that the sequence generated by FISTA is locally linearly convergent when applied to LASSO problem for a particular choice of acceleration parameters.
Although FISTA is superior to ISTA both on theoretical results and numerical performance, a common observation when running FISTA is the appearance of ripples or bumps in the trace of objective value near the optimal solution. Using a spectral analysis, Tao et al. (2016) have shown that FISTA slows down compared to ISTA when close enough to the optimal solution. To improve the convergence rate of FISTA, they switch to ISTA toward the end of the iteration process. On the other hand, O’Donoghue and Candès (2015) have proposed restart schemes for FISTA to avoid rippling behaviors. Moreover, Wen et al. (2017) have obtained a linear convergence rate of the sequence generated by FISTA with a fixed restart.
In contrast to the theoretical superiority on the global convergence rate, there is no result on the local convergence behavior demonstrating that FISTA is superior to ISTA. In this paper, utilizing the structure of measurement matrix A on the LASSO problem, we prove that FISTA has a better linear convergence rate than ISTA. We further observe that the convergence rate of FISTA is closely related to the acceleration parameters. Then the acceleration and regularization parameter setting strategies are proposed. A series of numerical experiments including signal processing and CT image reconstruction is carried out to compare ISTA with FISTA under different acceleration and regularization parameters. Moreover, we adopt the function restart scheme on FISTA to reconstruct CT images. The numerical experiments are consistent with our theoretical results.
The rest of this paper is organized as follows. In Sect. 2, some basic preliminaries are given. Then we prove a faster linear convergence rate of FISTA compared to ISTA in Sect. 3. Furthermore, in Sect. 4, we present some useful parameter setting strategies of FISTA. In Sect. 5, a series of numerical experiments are carried out, including signal recovery and CT image reconstruction, to show the effectiveness of FISTA. We conclude this paper in Sect. 6.
2 Preliminaries
In this section, we review the optimality conditions of the LASSO problem and the corresponding ISTA and FISTA, which then serve as the basis of further analysis in the following sections.
The first-order KKT optimality conditions for the LASSO problem are
where each component of \(\nu \) satisfies:
Here the “sign” function is defined as:
In the following, we review the basic iterations of ISTA and FISTA for the LASSO problem. The basic step of ISTA can be reduced to
where
and L is the given constant which is greater than or equal to \(\Vert A^{\top }A\Vert \).

As for FISTA, the difference from ISTA is that the shrinkage operator is not employed on the previous point \(\varvec{x}^{n-1}\) but another point \(\varvec{y}^{n}\), which uses a very specified linear combination of the previous two points \(\{\varvec{x}^{n-1}, \varvec{x}^{n-2}\}\). The procedure of FISTA is presented as below.

For simplicity, \(\Vert \cdot \Vert \) denotes the Euclidean norm. The support of \(\varvec{x}\in \mathbb {R}^{n}\) is \(\text {supp}(\varvec{x}):=\{i: |x_{i}|\ne 0, i=1, 2, \ldots ,n\}\). For any symmetric matrix \(B\in \mathbb {R}^{n\times n}\), we denote its maximum and minimum eigenvalues respectively as \(\sigma _{\text {max}}(B)\) and \(\sigma _{\text {min}}(B)\). I is the identity matrix. For any matrix \(A, B\in \mathbb {R}^{n\times n}\), \(A\succeq B\) if and only if \(A-B\) is a positive semidefinite matrix. For any index set S, we denote \(B_{S}\) as the submatrix of B with the columns restricted to S and \(\varvec{x}_{S}\) as the subvector consisting of only the components \(x_{i}, i\in S\). \(S^{c}\) represents the complementary set of S.
3 The improved linear convergence rate of FISTA
In this section, we establish the improved convergence rate of FISTA for LASSO problem.
For simplicity, \(\mu \) denotes 1 / L, i.e. \(0<\mu \le \Vert A\Vert ^{-2}\). Let
We define the following partition of all indices \(\{1, 2, \ldots , N\}\) into L and E.
Definition 1
Let \(\varvec{x}^{*}\) be the optimal solution of the LASSO problem. Define
It is clear that \(L\cup E=\{1, 2, \ldots , N\}\),
The basic Step 3 of ISTA can be written as
while the fixed point of this operator is the optimal solution of the LASSO problem. As we all know, the sequence generated by ISTA for the LASSO problem has a local linear convergence rate Hale et al. (2008).
Lemma 1
Let \(\{\varvec{x}^{n}\}\) be the sequence generated by ISTA for the LASSO problem and \(\varvec{x}^{*}\) be the optimal solution. If \(\sigma _{\text {min}}(A_{E}^{\top }A_{E})>0\), then
where \(\rho =1-\mu \sigma _{\text {min}}(A_{E}^{\top }A_{E}), \rho \in (0,1)\).
The basic Step 4 of FISTA for the LASSO problem can be written as
Before establishing the improved linear convergence rate of FISTA, we present an important property first.
Lemma 2
Assume that the sequence \(\{\varvec{x}^{n}\}\) generated by FISTA for the LASSO problem converges to \(\varvec{x}^{*}\). Then, there exists an \(n_{0}\) such that whenever \(n\ge n_{0}\), for any \(i\in L\)
and for any \(i\in E\)
Proof
By the continuity of \(B_{\mu }(\varvec{x})\), \(\forall \epsilon >0\), \(\exists \delta >0\), s.t. \(\left\| B_{\mu }(\varvec{x})-B_{\mu }(\varvec{x^{*}})\right\| < \epsilon \) if \(\Vert x-x^{*}\Vert <\delta \). By the assumption that \(\{\varvec{x}^{n}\}\) generated by FISTA converges to \(\varvec{x}^{*}\), for \(\delta \), there exists an \(n_{0}\) such that whenever \(n\ge n_{0}+2\),
As
\(\{\varvec{y}^{n}\}\) converges to \(\varvec{x}^{*}\) and
First, we prove by contradiction that for \(i\in L\), \(x^{n}_{i}=x^{*}_{i}=0\) whenever \(n\ge n_{0}+2\). Assuming it doesn’t hold, there exists an \(i\in L\), a subsequence \(\{n_k\}\) with \(n_k>n_0\) such that \(x^{n_k+1}_{i}\ne 0\). Hence
where \(|[B_{\mu }(\varvec{x}^{*})]_{i}|<\lambda \mu \). It contradicts to the fact that \(\left\{ B_{\mu }(\varvec{x}^{n})\right\} \) converges to \(B_{\mu }(\varvec{x}^{*})\). Following the same procedure, we can prove for \(i\in L\), \(y^{n}_{i}=x^{*}_{i}=0\) whenever \(n\ge n_{0}+2\). Therefore, \(y^{n}_{i}=x^{n}_{i}=x^{*}_{i}=0,~\forall i\in L\).
Similarly, we can prove (6) by contradiction. Assuming it doesn’t hold, there exists an \(i\in E\), a subsequence \(\{n_k\}\) with \(n_k>n_0+2\) such that \(\text {sign}([B_{\mu }(\varvec{x}^{n_k})]_{i})\ne \text {sign}([B_{\mu }(\varvec{x}^{*})]_{i})\). Hence,
contradicting again to the fact that \(\left\{ B_{\mu }(\varvec{x}^{n})\right\} \) converges to \(B_{\mu }(\varvec{x}^{*})\). We can also prove \(\text {sign}([B_{\mu }(\varvec{y}^{n})]_{i})=\text {sign}([B_{\mu }(\varvec{x}^{*})]_{i}\) when \(n\ge n_{0}+2\), in the same way. As a result, (6) holds.
This completes the proof. \(\square \)
We are now ready to prove the promised improved linear convergence rate of FISTA for the LASSO problem.
Theorem 1
Assume that the sequence \(\{\varvec{x}^{n}\}\) generated by FISTA for the LASSO problem converges to \(\varvec{x}^{*}\). If
and \(\sigma _{\text {min}}(A_{E}^{\top }A_{E})>0\), then
where \(\beta _{1}=0\) and \(\beta _{k}\in [0, \alpha ], k\ge 2\).
Proof
By Lemma 2, we have \(y^{n}_{i}=x^{n}_{i}=x^{*}_{i}=0,~ \forall i\in L\) and \(\text {sign}\left( \left[ B_{\mu }(\varvec{y}^{n})\right] _{i}\right) =\text {sign}\left( \left[ B_{\mu }(\varvec{x}^{n})\right] _{i}\right) =\text {sign}\left( \left[ B_{\mu }(\varvec{x}^{*})\right] _{i}\right) ,~ \forall i\in E\) when \(n\ge n_{0}+2\). Then \(\left\| \varvec{h}_{L}^{n}\right\| =0\) and \(\left\| \varvec{h}^{n}\right\| =\left\| \varvec{h}_{E}^{n}\right\| \) when \(n\ge n_{0}+2\), where \(\varvec{h}^n=\varvec{x}^{n}-\varvec{x}^{*}\). For simplicity, we assume that \(n\ge n_{0}+2\) always holds.
For any \(i\in E\), the following equation holds
where
Denoting
it follows that
The mathematical induction is used to prove
First we have
as \(\beta _{1}=0\).
Next, we prove \(P\succeq 0\). Since \(0<\mu \Vert A\Vert ^2<1-4\alpha /(1+\alpha )^{2}\), we have \(0<\mu \Vert A_{E}\Vert ^2<1-4\alpha /(1+\alpha )^{2}\). Therefore,
As \(0<\alpha <1\), it follows
Second, assuming
we shall prove that
Since
we have
On the other hand,
where the inequality is due to the fact that
To show
we only need to prove
i.e.
Since
and
Eq. (8) holds.
In conclusion, (7) holds. By (7), we obtain
where
This completes the proof. \(\square \)
Remark 1
From the proof of Theorem 1, for any \(k\ge 1\), we have \(0\le \beta _{k}\le \alpha \), \(\rho <1\). Thus, \(\rho -\beta _{k}\left( 1-\rho \right) <\rho \). On the other hand, for any \(k\ge 1\)
So we have \(\left[ \rho -\beta _{k}\left( 1-\rho \right) \right] >0\), indicating that the convergence rate of FISTA for the LASSO probelm is better than that of ISTA.
4 Parameter setting strategies
In this section, we will discuss some setting strategies for the acceleration and regularization parameters.
4.1 Acceleration parameter
From Theorem 1, we can observe that the linear convergence rate of FISTA is closely related to the acceleration parameters \(\beta _{n}\). If \(\{\beta _{n}^{1}\}\) and \(\{\beta _{n}^2\}\) are two increasing sequences with values in the range of \((0,\alpha )\) and \(\beta _{n}^{1}<\beta _{n}^2\), FISTA with acceleration parameter \(\{\beta _{n}^2\}\) is converging faster to the optimal solution compared to that with \(\{\beta _{n}^1\}\).
Beck and Teboulle (2009) have proposed the following choice of acceleration parameters for FISTA, with
while Tseng (2008) has proposed a FISTA with acceleration parameters
In the section of numerical experiments, we will compare the convergence rates of FISTA with different \(\{\beta _{n}\}\) to demonstrate the theoretical results.
4.2 Regularization parameter
It is well known that the solution quality of LASSO problem is closely related to the regularization parameter \(\lambda \). However, to set a proper value of regularization parameter is a very hard problem. Nevertheless, when some prior information (e.g., sparsity) is known, it is realistic to set the regularization parameter more reasonably and intelligently Xu et al. (2012).
Similar to the setting strategies in Xu et al. (2012), we set \(\lambda \) as follows. Assume \(\varvec{x}^{*}\) is the optimal solution of the LASSO problem with k-sparsity. Without loss of generality, assume \(\left[ B_{\mu }(\varvec{x}^{*})\right] _{1}\ge \left[ B_{\mu }(\varvec{x}^{*})\right] _{2}\ge \cdots \ge \left[ B_{\mu }(\varvec{x}^{*})\right] _{N}\). Then,
which implies
Instead of the optimal solution, we may use any known approximations of \(\varvec{x}^{*}\), say, we can take
in applications.
4.3 FISTA with restart scheme
A common observation when running FISTA is the appearance of ripples or bumps in the trace of the objective value near the optimal solution. To improve the convergence rate of the FISTA, O’Donoghue and Candès (2015) proposed two restart schemes:
-
Function scheme: restart whenever
$$\begin{aligned} F(\varvec{x}^{k})>F(\varvec{x}^{k-1}). \end{aligned}$$ -
Gradient scheme: restart whenever
$$\begin{aligned} \nabla F(\varvec{y}^{n})(\varvec{x}^{n}-\varvec{x}^{n-1})>0. \end{aligned}$$
Here, we will use function restart scheme to improve the FISTA, named as IMFISTA. If \(F(\varvec{x}^{n})>F(\varvec{x}^{n-1})\), we reset the acceleration parameter \(\beta _{n}=0\).
5 Numerical experiments
In this section, we conduct a series of numerical experiments to demonstrate the validity of the theoretical analysis on the convergence of ISTA and FISTA. Furthermore, to demonstrate the parameter setting strategies, FISTA with different acceleration parameters are also tested. The sparse signal and CT image reconstruction problems are considered in this section.
The numerical experiments are carried out using MATLAB 2012(b) and running on a PC with 2.50 GHZ CPU processor and 8 GB of RAM. The error precision \(\epsilon \) is set to \(10^{-6}\). The iteration bounds for algorithms in signal and image recovery are set to be 3000 and 1000, respectively.
5.1 Signal recovery
The sparse signal recovery problem has attracted a considerable amount of attention in the past decade Donoho (2006). This can be modeled as the LASSO problem. Here we consider a real-valued N-length (\(N=2000\)) signal \(\varvec{x}\) without noise, where \(\varvec{x}\) is K-sparse with \(K=20\).
The experiment then aims to recover a signal \(\varvec{x}\in \mathbb {R}^{2000}\) from \(M=200\) measurements by \(\varvec{y}=A\varvec{x}\). The measurement matrix A is taken as the Gaussian random matrix, as suggested in Donoho (2006). The recovery precision is evaluated by the relative error (RE), defined as \(\text {RE}=\Vert \varvec{x}-\varvec{x}^{*}\Vert /\Vert \varvec{x}^{*}\Vert \), where \(\varvec{x}\) and \(\varvec{x}^{*}\) represent the recovered and original signal respectively.
We test ISTA, FISTA and IMFISTA with \(\beta _{n}=(t^{n-1}-1)/t^n\) and \(\beta _{n}=(n-2)/(n+1)\), when \(\lambda =0.0001\) and \(\lambda =\lambda ^{*}\). For each case, the REs, the CPU times and the iteration numbers for all the algorithms are recorded. Some of the numerical results are listed in Table 1.

FISTA and IMFISTA with \(\lambda =0.0001\)
FISTA and IMFISTA with \(\beta _{n}=(t^{n-1}-1)/t^n\) are denoted by \(\text {FISTA}_{1}\) and \(\text {IMFISTA}_{1}\), respectively. FISTA and IMFISTA with \(\beta _{n}=(n-2)/(n+1)\) are denoted by \(\text {FISTA}_{2}\) and \(\text {IMFISTA}_{2}\), respectively. It can be seen from Table 1 that \(\text {IMFISTA}_{1}\) and \(\text {IMFISTA}_{2}\) perform best in all the five algorithms, no matter \(\lambda =0.0001\) or \(\lambda =\lambda ^{*}\).

FISTA and IMFISTA with \(\lambda =\lambda ^{*}\)
For a clearer illustration, Figs. 1 and 2 show how the REs vary with the iterations, highlighting that the IMFISTA has a faster convergence rate than the FISTA.

FISTA with different \(\beta _{n}\)
Moreover, to demonstrate the theoretical results of the linear convergence rate of FISTA, we test FISTA with different multiples of \(\beta _{n}=(n-2)/(n+1)\). Letting \(\beta _{n}^{1}=0.2\beta _{n}\), \(\beta _{n}^{2}=0.4\beta _{n}\), \(\beta _{n}^{3}=0.6\beta _{n}\), \(\beta _{n}^{4}=0.8\beta _{n}\), and \(\beta _{n}^{5}=\beta _{n}\), we also illustrate numerical results in Fig. 3. As shown, FISTA with \(\beta _{n}^{4}\) is converging fastest.
5.2 CT image recovery
We consider the problem of recovering the head phantom image (\(256 \times 256\)) (Fig. 4). The image can be expressed as a 65,536-dimensional vector \(\varvec{x}\). It has a wavelet coefficient sequence \(\varvec{\alpha }\) that is compressible Devore and Jawerth (1992), where \(\varvec{x}=W^{\top }\varvec{\alpha }\), W is the discrete orthogonal wavelet transform matrix. We select Fourier matrix as the measurement matrix A.

Original and compressed CT image
The experiment aims to recover the wavelet coefficient sequence \(\varvec{\alpha }\) through the following model:
where \(\varvec{\alpha }\) is the wavelet coefficient sequence of the image \(\varvec{x}\), \(\lambda >0\) is a regularization parameter, \(A\in \mathbb {R}^{M\times N}\) is a Fourier matrix, \(W\in \mathbb {R}^{N\times N}\) is a discrete orthogonal wavelet transform matrix and \(\varvec{y}\) is an observation.

FISTA and IMFISTA with \(\lambda =0.001\)

FISTA and IMFISTA with \(\lambda =\lambda ^{*}\)
We compare the performances of the ISTA, FISTA and IMFISTA on recovering these two images. The performance of each algorithm is measured in terms of signal-to-noise ratio (SNR), which is defined as
where \(\varvec{x}\) is the original image and \(\overline{\varvec{x}}\) is the image recovered from the measurements by an algorithm.
First, we recovery the head phantom image generated by MATLAB. The sampling rate is measured as \(M/N=0.39\). The detailed results of image recovery under different algorithms are listed in Table 2. Obviously, FISTA and IMFISTA with \(\beta _{n}=(n-2)/(n+1)\) are faster than that with \(\beta _{n}=(t^{n-1}-1)/t^n\), while IMFISTA is faster than FISTA.

ISTA, FISTA and IMFISTA for CT image reconstruction

FISTA with different \(\beta _{n}\) for CT image reconstruction
Similarly, Figs. 5 and 6 show how the REs vary with the iterations, highlighting that the IMFISTA has a faster convergence rate than the FISTA.
Then, we recover the head phantom CT image Fig. 4. The sampling rate is measured as \(M/N=0.31\). We set \(\lambda =\lambda ^{*}\). Figure 7 shows how the REs vary with the iterations. We observe that FISTA is nearly the same as IMFISTA when RE is monotonically decreasing.
Moreover, we also demonstrate the theoretical results of the linear convergence rate of FISTA. Different acceleration parameters are tested, including \(\beta _{n}^{1}=0.2\beta _{n}\), \(\beta _{n}^{2}=0.4\beta _{n}\), \(\beta _{n}^{3}=0.6\beta _{n}\), \(\beta _{n}^{4}=0.8\beta _{n}\), and \(\beta _{n}^{5}=\beta _{n}\). As shown in Fig. 8, FISTA with \(\beta _{n}^{5}\) is converging fastest.
6 Conclusion
In this paper, we have proven that the FISTA has a better linear convergence rate than the ISTA. Besides, some useful insights for the acceleration and regularization parameter setting strategies have been derived from the theoretical result. Moreover, we have successfully implemented function restart scheme on the FISTA to reconstruct CT images. Both signal processing and CT image reconstruction are consistently demonstrating our theoretical results.
However, we have to point out that the local convergence rates of FISTA for general convex optimization is still unknown. The convergence rate of FISTA with restart schemes is also unknown, although it has been implemented on many applications, such as inpatient bed allocation Chang and Zhang (2019), healthcare facility layout Gai and Ji (2019) and the operation nurse problem Zhong and Bai (2019). These are interesting points for future research.
References
Beck A, Teboulle M (2009) A fast iterative shrinkage–thresholding algorithm for linear inverse problems. SIAM J Image Sci 2(1):183–202
Chang J, Zhang LJ (2019) Case Mix Index weighted multi-objective optimization of inpatient bed allocation in general hospital. J Comb Optim 37(1):1–19
Chen SS, Donoho DL, Saunders MA (2001) Atomic decomposition by basis pursuit. SIAM Rev 43(1):129–159
Devore R, Jawerth B (1992) Image compression through wavelet transform coding. IEEE Trans Inf Theory 38(2):719–746
Donoho DL (1995) De-noising by soft-thresholding. IEEE Trans Inf Theory 41(3):613–627
Donoho DL (2006) Compressed sensing. IEEE Trans Inf Theory 52(4):1289–1306
Efron B, Hastie T, Johnstone IM, Tibshirani R (2004) Least angle regression. Ann Stat 32(2):407–499
Gai L, Ji JD (2019) An integrated method to solve the healthcare facility layout problem under area constraints. J Comb Optim 37(1):95–113
Hale E, Yin W, Zhang Y (2008) A fixed-point continuation method for \(l_1\)-minimization: methodology and convergence. SIAM J Optim 19(3):1107–1130
Johnstone PR, Moulin P (2015) A Lyapunov analysis of FISTA with local linear convergence for sparse optimization. arXiv preprint arXiv:1502.02281
Nesterov Y (1983) A method for unconstrained convex minimization problem with the rate of convergence. Dokl AN SSSR 269:545–547
O’Donoghue B, Candès E (2015) Adaptive restart for accelerated gradient schemes. Found Comput Math 15(3):715–732
Tao SZ, Boley D, Zhang SZ (2016) Local linear convergence of ISTA and FISTA on the LASSO problem. SIAM J Optim 26(1):313–336
Tseng P (2008) On accelerated proximal gradient methods for convex-concave optimization. Manuscript. University of Washington. Seattle
Wen B, Chen XJ, Pong TK (2017) Linear convergence of proximal gradient algorithm with extrapolation for a class of nonconvex nonsmooth minimization problems. SIAM J Optim 27(1):124–145
Xu ZB, Chang XY, Xu FM, Zhang H (2012) \(L_{1/2}\) regularization: a thresholding representation theory and a fast solver. IEEE Trans Neural Netw Learn Syst 23(7):1013–1027
Yang AY, Zhou Z, Balasubramanian AG, Sastry S, Ma Y (2013) Fast \(L_{1}\)-minimization algorithms for robust face recognition. IEEE Trans Image Process 22(8):3234–3246
Zhong LW, Bai YQ (2019) Three-sided stable matching problem with two of them as cooperative partners. J Comb Optim 37(1):286–292
Acknowledgements
This research was supported by the National Natural Science Foundation of China (Grant No. 11901382).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, Q., Zhang, W. An improved linear convergence of FISTA for the LASSO problem with application to CT image reconstruction. J Comb Optim 42, 831–847 (2021). https://doi.org/10.1007/s10878-019-00453-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10878-019-00453-7