
Abstract
In medical systems for patient’s authentication, keeping biometric data secure is a general problem. Many studies have presented various ways of protecting biometric data especially finger vein biometric data. Thus, It is needs to find better ways of securing this data by applying the three principles of information security aforementioned, and creating a robust verification system with high levels of reliability, privacy and security. Moreover, it is very difficult to replace biometric information and any leakage of biometrics information leads to earnest risks for example replay attacks using the robbed biometric data. In this paper presented criticism and analysis to all attempts as revealed in the literature review and discussion the proposes a novel verification secure framework based confidentiality, integrity and availability (CIA) standard in triplex blockchain-particle swarm optimization (PSO)-advanced encryption standard (AES) techniques for medical systems patient’s authentication. Three stages are performed on discussion. Firstly, proposes a new hybrid model pattern in order to increase the randomization based on radio frequency identification (RFID) and finger vein biometrics. To achieve this, proposed a new merge algorithm to combine the RFID features and finger vein features in one hybrid and random pattern. Secondly, how the propose verification secure framework are followed the CIA standard for telemedicine authentication by combination of AES encryption technique, blockchain and PSO in steganography technique based on proposed pattern model. Finally, discussed the validation and evaluation of the proposed verification secure framework.
Similar content being viewed by others


Introduction
Nowadays, the word ‘telemedicine’ has become equivalent to the use of telecommunication technology for the provision of medical information and services for various purposes, such as disease diagnosis, transfer of medical data and records, monitoring of therapy or treatment processes and even for surgical operations [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]. The architecture of telemedicine comprises a three-tier pervasive telemedicine system based on a wireless body area network (WBAN) that enables real-time and continuous healthcare monitoring [18,19,20,21,22]. Vital signs can be obtained by patients through tiny intelligent wireless sensors in Tier 1 [23,21,25]. These signals are then sent to Tier 2, which is a personal gateway (e.g. handheld devices, personal digital assistants and laptops), through small area network protocols (e.g. Bluetooth and Zigbee) and WBAN [26,27,28]. Afterwards, these data are sent from Tier 2 to Tier 3, which is the healthcare provider in medical institutions (MIs), through wide area wireless communication protocols or Internet services [29,30,31]. The client side is represented by Tiers 1 and 2, whereas the server side is represented by Tier 3 [4,5,6,7]. The low-cost handheld telecommunication systems and customised patient monitoring devices that are currently available ensure that the numerous advantages of telemedicine can be assessed directly from the patient’s home via systems connected with different types of wired or wireless networks. However, these networks remain susceptible to attacks, thereby exposing all telemedicine systems to security breaches.
To safely access these services, authentication between both parties is vital [32,33,34,35]. The server requires authentication to protect records from unauthorised persons and should guarantee the confidentiality of the patient’s information (client side). Achieving patient authentication is important to prevent any impersonations from the server side [32, 36, 37]. An area of interest within this proof-of-concept is addressing emergency situations during distress or emergency cases, in which a patient arrives at the hospital unconscious; the problem is how to access information without requiring the patient to provide an authorisation key. This challenge needs to be addressed using secure biometric identity solutions, such as palm vein and iris [38,39,40]. The biometric technology authentication system has become popular because it provides high levels of security, usability and reliability for patient authentication [39]. For example, the finger vein (FV) biometric has substantial security features. Most authentication systems available today store biometric patterns in a database system. These data are then extracted as biological biometrics through an authentication process. A secure biometric authentication framework for telemedicine architecture with FV will have better resistance to any security breaches and impersonation attempts. The human FV is a physiological biometric used for identification via the physical characteristics and other properties of the blood veins. It is a relatively new technology in security systems and has been applied in numerous fields, such as medicine, finance, commerce and law, for the identification of individuals and criminals (in legal cases) and for other applications that require high levels of security and privacy [41,42,43,44,45,46,47,48,49,50,51,52]. This new technology is more accurate than other biometric systems [53].
In this study, a secure framework of the FV biometric verification system for telemedicine architecture is proposed. For this purpose, three phases are performed. In the first phase, a new hybrid model design for the client side is developed to achieve randomisation by proposing a new algorithm that merges the RFID and FV features in one hybrid and random pattern. In the second phase, encryption is developed by creating a blockchain and steganography technique for the server side based on a hybrid pattern model to secure the FV biometric verification system during the authentication process. In the third phase, the validation and evaluation of the proposed framework is presented. The rest of this article consists of four sections: Section “Finger vein research problem based medical systems for patient’s authentication” illustrates the FV biometric research problem and the proposed solution. Section “Methodology” presents the methodological aspects of the proposed work. Section “Discussion” describes the discussion of the proposed methodology based on three divergent and successive phases. Section “Conclusion” provides the conclusion.
Finger vein research problem based medical systems for patient’s authentication
We aim to develop and design a new secure framework for telemedicine authentication systems based on FVs, which ensures the accuracy of verification results with low levels of cost, time and error rates. However, an investigation of previous studies indicates that a critical drawback exists with regard to the utility of FV biometrics. Securing the FV data inside the verification system is challenging, because with this type of technology, any security breaches or leakage of the biometric data could lead to serious security risks. A good example would be replay attacks using stolen biometric data [54]. This problem affects the reliability of the verification system and therefore prevents stakeholders from using the system. As described above, biometric data are open to attacks from numerous sources either during an individual’s enrolment step when the user attempts to access services from cloud computing or IoT [55] during data transmission between client and server or inside the database, where the biometric data is stored. Therefore, a solution to this problem must be found because these biometrics are constant [56] and changing these biometrics is impossible after it is stolen. Many researchers have made attempts to secure FV biometrics in different ways by using uni- (FV biometric) or multi-biometrics, which includes FV biometrics as a part of the verification system. These methods presented in our literature review are applied in two steps, which are described below:
In terms of protecting FV patterns, the researchers’ attempts include extracting reliable features from FVs, which is a unique form of individual identification. These features that are collected from the FV intersection points and the angles that are bounded between veins are considered exclusive information, which is in turn used to generate a unique key (biokey). Data patterns are then encrypted based on this key [55, 57]. The observation matrix is used to extract the patterns and features, and a random key is used to encrypt this information [54]. To enhance pre-existing features, some researchers used multi-biometrics to obtain more features. These features have been used in the identification of individuals (FV, retina and fingerprint). The features are then extracted from the biometrics, and an encryption algorithm is used to secure patterns and information [58]. Some systems use more than three biometrics, whilst some use four. Examples include FV, fingerprints and knuckle and finger shapes. A random key for encrypting pattern information is also used [59]. Some systems used multimodal biometric systems (such as FV and signature image) to obtain unique features from individuals. In this case, cryptography is used to secure these data [53]; however, all these attempts utilised multi- or single biometrics (pure finger biometric).
The challenge of securing the information of the FVs
As outlined in the research problem, the FV biometric system is susceptible to security issues. Securing the extracted data is challenging, because unlike other types of security information, such as passwords, information that has been extracted from biological attributes is impossible to change or modify after being stolen. Moreover, the responsibility to protect FV biometric information rests solely on the company or organisation using the system, because the user does not know what that information is but only keeps it as a biological attribute; these attributes are invisible to other people and the user himself. The findings of these studies are briefly described in Table 1. An analysis of these works is provided whist attempting to prove that these systems still need more efficient methods to secure FV biometric information.
The processing of FV biometric verification system in terms of protecting FV information can generally be divided into two parts: feature extraction and protecting biometric information.
Feature extraction
Reference [53] developed a new extraction method that combines FV biometrics and signature to enhance result accuracy and security. In this study, features from the FV biometrics used maximum curvature point method and thinning processing to decrease the thickness of the vein line to one pixel per the width of vein lines, which are present in the centre of these lines. With regard to extraction features from the signature image, mini-max normalisation method and segmentation were implemented. The signature image was then converted into a binary image by implementing the binarisation method. All these processes were performed to enhance image quality and capture vital information from FV and signature. Extracting features from the FV utilises the CN method and the PCA method. Reference [57] proposed an algorithm to extract features from FV images by determining the location of the veins’ intersection point and measuring the angles between those veins to enhance image quality and smoothen the region of interest (ROI) using the Gaussian filter. Unwanted backgrounds were removed by using Otsu’s segmentation algorithm and then applying guided filtering, followed by Gabor filtering. Finally, a thinning algorithm was implemented by drawing a circle around each intersection point and then calculating the Euclidean distance between them. Reference [55] presented a new framework for cloud computing authentication using FV biometrics, which provides the user a convenient and secure authentication process. The first step after FV image acquisition is preprocessing, which applies image segmentation, filtering and denoising, refinement, deblurring and other operations. Afterwards, feature extraction, which consists of biokey generation, was performed using manifold learning. Reference [54] proposed a secure biometric authentication scheme, which aimed to secure biometric information during biometric image capturing to extract the features from FV using compressive sensing (CS) and compressive imaging (CI) systems, which contain a digital micromirror device (DMD) for generating random intensity patterns
Reference [58] used multimodal biometric authentication systems, which combined fingerprint, retina and FV biometrics to enhance verification accuracy and security against spoofing. Fingerprint extraction utilised termination and bifurcation methods; retinal extraction used a template using thresholding techniques based on eight different orientations and extracted features from FV biometrics using the repeated line tracking method and maximum curvature. Reference [59] proposed a finger multi-biometric cryptosystem (fingerprint, FV, finger knuckle and finger shape) to achieve security and recognition accuracy. The features were extracted from four finger biometrics and then gathered into new feature factors. After this step, the factors were converted into a binary representation, which will be the input for the next step, that is, data security. Reference [60] proposed a general framework for multi-biometrics, in which all the inputted biometric features are assembled during enrolment. Many biometric features are created, and the templates of biometrics based on the collected features are then protected
Analysis of previous studies on biometric feature extraction, such as uni-biometric (only FV) or multi-biometric (including FV), revealed that researchers used pure FV features. In many cases, other types of biometric features are used along with FV to enhance verification accuracy. Therefore, we need to produce a new FV pattern with more randomisation features to protect FV pattern information to prevent intruders from using this pattern in case it is successfully captured during transmission from the client to the server.
Protecting biometric information
According to Reference [53], at the fusion level, the extracted features are retrieved from a combination of FV and signature images. A visual cryptography scheme is then implemented to protect this information. In Reference [54], a CS system was used to encrypt biometric data by using an observation matrix as a cipher key. In the CI system, the observation matrix describes the series of random intensity patterns produced by a DMD. In this case, data encryption is applied in the sensor device, and the matching operation occurs at the authentication server. Data encryption is applied to the electronic information during image capture, and the raw vein images are stored in the authentication server. Reference [57] used the extracted features to generate an encryption key and then used the DES algorithm to encrypt the biometric information. Reference [58] implemented cryptosystem using RSA algorithm to protect biometric information (fingerprint, retina and FV). Reference [55] presented a framework for cloud computing authentication using FV biometrics. After preprocessing FV images and extracting its features, a biokey was generated from the features by extracting two images for each finger during preprocessing to generate a biokey with a length of 0–256, because the number of feature points was not enough to generate a biokey with sufficient length. The biokey was then combined with a cloud computing service URL to produce a unique string, which can be used for identity authentication. In this study, according to Reference [59], the fuzzy commitment scheme (FCS) was used to secure the biometric templates and to protect the biometrics information. This procedure combined the error correcting code (ECC) with a cryptographic hash function in the enrolment and verification phases. The collected features retrieved from multi-biometrics were then converted into a binary string with a length of 512 bits (Reference [60]). The encryption algorithms that were used to encrypt the sensitive information in previous studies are the RSA and DES algorithms. Both cryptography techniques will be discussed in the following subsections. The performance of these algorithms will be evaluated to determine and propose a more secure alternative in our recommendations.
Cryptography
Cryptography refers to the use of mathematics for data encryption and decryption to make these data unreadable from unauthorised parties and to protect these data during transmission between sender and receiver [61,62,63,64]. It comes from the Greek word ‘kryptós’ and ‘gràphin’, which means ‘hidden’ and ‘writing’, respectively. Cryptosystem consists of some terms, such as plaintext, encryption and decryption algorithms, Cipher text, and Key [65,66,67,68,69]. Moreover, cryptosystem has two types: the symmetric type, in which the sender and receiver use one key for encryption and decryption, and the asymmetric type, which uses two keys, one for encryption and the other for decryption [70,71,72,73,74]. The most famous algorithm encryptions used in the literature review are the RSA and DES algorithms. Asymmetric cryptography uses the RSA algorithm to protect the pattern stored in the database, which increases genuine acceptance rate and reduces false acceptance rate [18]. The DES algorithm uses fast symmetric cryptography, when the sender and receiver use private and public keys; in this case, the cryptography system is called asymmetric cryptography system. [68]. The RSA algorithm uses two different but mathematically related keys: a public key and a private key. During the process, the public key can be shared between the sender and the receiver, but the private key must be kept secret.
Other types of cryptography algorithms have levels of security that are based on the protection level presented by the key used to cipher and decipher the data. The DES algorithm uses 64 binary bits for the key; 56 bits from the key are used in the algorithm, whilst the other eight bits are used for error detection [75]. This key bit distribution creates a DES inherent weakness, which allows attackers to take advantage [76]. DES uses a constant length of string of plaintext bits and then transform it via a series of complicated operations into another cipher text bit string with similar length. Table 2 compares the RSA and DES algorithms, as well as the most modern advanced encryption standard (AES) methods, by using 18 factors to determine the more suitable and applicable cryptography algorithm to use in our proposed solution [77].
The comparison above shows that each algorithm has its strengths and weaknesses, such as the speed of encryption and decryption, the level of security (which is the most important shortcoming to be wary of) and a lack of proficiency in the implementation of both system components (hardware and software). To use the more suitable cryptography algorithm in our verification system, we need to evaluate the performance and strength and weaknesses of the algorithms. After evaluating these algorithms based on the 18 factors in the table, AES scored the highest; therefore, this algorithm can be used in our proposed solution, because confidentiality is the top priority [78].
Advanced encryption standard (AES) algorithm
This algorithm is a symmetric block cipher that has been used by the US government to secure information [79]. It can be applied in software and hardware to encrypt information. This algorithm supports a data block of 128 bits and possesses a variable key length of 128, 192 and 256 bits that have an iteration cycle number of 10, 12 and 14 rounds, respectively [80]. Moreover, it is suitable for encrypting relatively long plaintexts. The AES has three distinct properties: round change, turns and key expansion [81]. More details are provided in Section “Discussion”.
Criticism of data security techniques used
In Reference [53], using a signature along with FV biometrics to improve the accuracy in individuals authentication process yielded good results. However, signature usage is not devoid of its own shortcomings. For example, people do not have consistent signatures all the time, especially in situations when they are in a hurry, tired, or under distress. As a result, the features extracted from the signature images are not stable during enrolment in the authentication system, thereby affecting accuracy. Eventually, the entire authentication system will be affected. Moreover, signature usage during each enrolment is not user-friendly. The criticism of the cryptography technique will clarify this issue in this section, as well as the features of signature separated from the FV features. In this case, if an attacker gains access to these features, then he will be sure that one group of features belongs to the signature, and the other feature group belongs to the FV. Reference [60] proposed a general framework using a multi-biometric authentication system (FV biometrics and other biometrics) without stating what type of biometrics can be used with FV biometrics. Each type of biometric should be applied and evaluated, because they have different features and methods of extraction after considering the processing time, accuracy and usability and overall effect on system performance. Moreover, this framework used the fuzzy commitment scheme cryptosystem to protect biometric information. The downside is that cryptosystems based on fuzzy commitment scheme (FCS) do not guarantee high levels of privacy security. In addition, the servers and the generated key are usually short and unstable, because the servers require biometric templates or their converted information to be stored first in making this type of encryption scheme unsecure in network environments. Reference [57] used vein intersection points to calculate the angles and distances between them. Afterwards, features were extracted from FV images. However, it is not a foolproof method, because some individuals do not have enough vein intersection points in their finger, thereby decreasing biometric features and reducing the encryption key length, which eventually affect the performance of the entire system. Reference [58] used a multimodal biometric authentication system (fingerprint, retina and F.V), which makes the system time consuming and complicated, especially when the retina is exposed directly to infrared light, which may cause side effects. The fingerprint is also not stable for long periods and can be affected by skin diseases. It is also easy to copy and prone to external distortion [59]. In this study, Reference used FCS to secure biometric information in the database, but this study needs more security analysis because of many security loopholes and FCS is not yet proven to be the best method for ensuring high security and privacy (Reference [54]). This method can be vulnerable to security attacks, because the raw images of the FV biometrics are stored in the server, making it easy for a hacker to gain access and retrieve the images. This drawback is a serious security risk because this kind of information is sensitive and can be used to attack the individuals who own the data and the organisations that run and maintain the database. Reference [55] proposed a framework for cloud computing authentication using FV biometrics, which extract features from two FV images from the same finger. Using the same algorithm in this case, the generated biokey will be symmetrical in terms of feature extraction, which is a good way to secure any biometric information; however, the security of this framework still needs to be enhanced.
All the previous studies used cryptography to solve the general problem of securing biometric information against different threats. However, this technique still has drawbacks. When an attacker finds unreadable data upon gaining access through a point of vulnerability, he will assume (rightly) that more sensitive information is probably available, because cryptography simply hides the content and meaning of the data. The attacker can transfer this unknown data to another system or location and then decrypt the cipher text using modern programs and techniques.
According to international standards (ISO/IEC 27002, 2005), information security is defined as the keeping of the confidentiality, integrity and availability of information, also known as the confidentiality, integrity and availability (CIA) triangle [82]. This triangle is considered the industry standard for computer security based on the three characteristics of information as shown in Fig. 1. Previous research studies have not discussed these standards extensively when proposing solutions for the FV pattern information security problem. The characteristics [83] are defined as follows:

CIA triangle
-
Confidentiality refers to the features that ensure data privacy, that is, only authorised persons can read or gain data access.
-
Data integrity means that information cannot be modified during transmission from sender to receiver. This term includes authenticity and nonrepudiation.
-
Availability means that information is available for authorised persons at any time.
-
Data confidentiality can however be achieved by using cryptography, although this method can be inadequate in some cases [84]. Therefore, other techniques need to be used to enhance data confidentiality. We will recommend another technique that will better ensure data integrity and availability.
Recommended solution based on the conceptual framework
In all authentication systems, keeping biometric data secure is a general problem. Many studies have presented various ways of protecting biometric data, especially FV biometric data, which is our focus in this study. In Subsection “Criticism of data security techniques used”, we criticised and analysed all attempts, as revealed in the literature review. We need to find better ways of securing data by applying the three principles of information security and by creating a robust verification system with high levels of reliability, privacy and security, because replacing biometric information is difficult, and any leakage of such information leads to risks, such as replay attacks using the stolen biometric data. On the basis of the details discussed in the comprehensive review, the recommended solution can be divided into two steps. The first step is to create a hybrid and random FV pattern using radio frequency identification (RFID) technology, and the second step is to secure the FV patterns by boosting the confidentiality, integrity and availability in the verification system. These three steps are described in detail in Section “Discussion”.
Hybrid and random biometric pattern
This pattern is the first part of our recommended solution for creating hybrid and random FV patterns using RFID technology together with FV biometric information to achieve randomisation requirements.
Radio frequency identification
RFID is a fast-growing technology that has been used in various applications and can automate identification using radio waves. As illustrated in Fig. 2, RFID components can be divided into three: a tag or label, a reader and antenna and a host computer (controller) with a suitable application software. The RFID technology has been used in many fields in industry and government agencies to enhance system security. It can also be applied in healthcare systems to save people’s lives.

RFID component communication
RF tag
The components of an RFID tag include tiny microchips, memory and an antenna coil. When the tag receives radio signals from the reader, it responds by transmitting its unique ID code. The information that is stored in this tag will be sent back to the interrogator by using radio wave energy. This type of tag contains a small battery.
RFID readers
Also called interrogators, RFID readers are used to send and receive radio signals from the tag to obtain identification, location and other information, which are embedded in the tag through the antenna. This operation uses low power consumption by the microchip. Two types of RFID readers exist.
RFID read-only readers: These devices can only read information from a nearby RFID tag. These devices are used in stationary applications and handheld varieties.
RFID read-write readers: This type of RFID reader can be used in writing and programming information into a blank RFID tag, because this type has the ability to read and write; it is also referred to as an encoder.
RFID tags consist of unique identifiers of objects and an individualised serial number. Thus, they can be used for identification. Tags can be read and written from a distance through camouflaging materials. The RFID information system can also record the location and capture time, enabling it to create a history of the work profile [85]. The serial number is stored in a chip located inside the tag. The antenna can read the tag information when this tag is within the readable range. The reader will then receive the information, which is redirected back to radio frequency waves, which are then converted to digital information and passed to the software system [86].
Types of RFID
RFID can be useful in many areas and has been applied in many fields that require automated identification using radio waves. Three types of RFID are shown in Fig. 3.

Types of RFID with properties
In the last decade, RFID has grown in popularity because of its application in real-life situations, especially in the fields of human identification, tracking, monitoring, security control measures and healthcare applications. The RFID tag consists of microchips, which can be read–write, read only and write once read many (WORM). With the read-and-write tag, whenever the tag is within the range of the reader, information can be written over existing information. These types of tags have a serial number that cannot be overwritten.
The tags also have space for additional data. Read-only tags contain only manufacturer information and cannot be changed. WORM tags can have a serial number written by the manufacturer. In this case, the data cannot be overwritten in the future. Depending on the vendor and type of application, the amount of data that can be stored in the tag could range between no more than 2 KB of data and only 96 or 128 bits for the serial number. Conversely, data transmission between the tag and reader is considered an unsecure channel; thus, data, including user information, can easily be interrupted and stolen [87]. Many researchers have attempted to solve security problems they faced with the RFID by encrypting the information during communication. To achieve this, they needed to use the UHF type to store large amounts of data of around 4–8 KB for long distance communication. This amount of data is not needed for our work; therefore, we use a high-frequency RFID smart card ticket, in which the required distance between the tag and reader is not more than 30 cm (near contact up), ensuring that the information contained in the RFID cannot be read from a long distance. The RFID serial number requires 128–512 bits. In the proposed framework, a combination of the serial number of the RFID smart card and the FV biometric is used. When one attempts to use the RFID alone, the reader will send a code or bin as a kill command at the point of usage, which will render the tag unusable [88].
Increasing information security requirements
As pointed out in Subsection “Criticism of data security techniques used”, we should increase the security standard requirements (CIA triangle) to enhance information security. In the following subsections, we describe the techniques used in our proposed solution according to the definition of information security requirements.
Blockchain technology
In accordance with the CIA triangle, we use steganography in this study. To enhance result integrity and availability (including authenticity and nonrepudiation), blockchain technology, which is the most modern way to achieve the goal, must be used. For integrity, blockchain technology has been designed to store information that cannot be altered (or difficult and costly to implement) once it is stored [89]. Availability can be achieved in a most straightforward manner by blockchain, which depends on distributed systems that allow them to keep working even when some nodes are under attack [90]. To realise the full potential for a secure verification system, we must deal effectively with threats and ensure the security and privacy of the information collected from sensor devices (FV imaging devices).
Since 2009, when Bitcoin first emerged in the world of technology, blockchain was the underlying technique for securing transaction information. Its promising application prospects have attracted considerable attention in the fields of academy and industry. Blockchain has been applied in various areas, such as medicine, economics, IOT and software engineering. [91]. It helps us build a decentralised mechanism system, because it does not need any authorisation from a third party (trusted authority) to maintain the reliability and consistency of data. Blockchain can be used to ensure that the information comes from a trusted source by creating a record of the device configuration state. This record is then used to verify whether the given device is genuine and that its software and settings have not been breached. This characteristic indicates that the device has immunity against IP spoofing attacks; this immunity exists because only the authorised device can connect to other devices or services. Moreover, the management systems based on blockchain technology have a strong protection against attacks, such as IP spoofing or IP address forgery. Therefore, modifying blockchains is difficult; nodes cannot connect to a network by themselves via injecting forge signatures into the record as camouflage [92]. Blockchain is applied in cryptocurrency contracts, voting, intellectual property rights and smart properties, amongst others. Therefore, we propose the use of blockchain to solve the problem of information credibility and integrity in an FV verification system. The principle of blockchain technology is proposed as a technical scheme of the data, which achieve secure transmission, eliminate centralised authentication and overcome the failure problems that occur in one-network nodes. This scheme creates blocks through any number of nodes in the system by using cryptography. It is essentially a chain of blocks with separate blocks containing the data of all transactions within a definite period in the system. These blocks are linked linearly in chronological order, with every block containing a hash of the previous block [93]. A digital fingerprint could be created and can also be used to verify the validity of the information and connect with the next block in the blockchain.
Hashing
Hashing can be defined as a manner of producing an unreadable string with a fixed size, according to the hashing algorithm type, to secure information against any alterations during transmission. The hashing function is used in blockchain to encrypt information inside the data block. Numerous hashing functions, such as SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224 and SHA-512/256, produces a fixed size string regardless of the size of string input; for example, if we have two strings with different sizes and we use the MD5 hashing function, then the output hashing will have the same size, according to the MD5 hashing design, as shown in the following example:

As shown above, the input string has a different size, but the output has the same size. Section “Discussion” provides more details about this phenomenon.
Blockchain technology uses hashing to add the hashes inside the data block, which needs to be transferred from side to side. This chain is added to the transactions to secure the data; therefore, modifying the blockchain is mathematically impossible. Any change requires regenerating all successors and redoing the work they contain [94]. In traditional cryptography, a single point of truth could be a certified authority. Moreover, attackers can masquerade as many users by using their own keys instead of the stored keys.
Steganography
According to the CIA triangle, the well-known techniques used to enhance confidentiality are cryptography and steganography [83, 95,96,97,98,99]. From the analysis of the literature, no study has used a combination of steganography and cryptography in the FV verification system. Using this combination ensures that sensitive information would be rendered unreadable with cryptography, whereas steganography conceals the data completely [100]. Steganography originated from the Greek word ‘steganós’, which means ‘covered’, and ‘graptos’, which means ‘writing’. The combined literal translation means ‘cover writing’. In general, steganography is also known as ‘invisible’ communication. Steganography refers to the process of concealing messages in another medium, such as audio, video, image and other forms of communication [101,102,103,104,105,106,107]. Steganography does not modify the structure or layout of the secret message but conceals it inside a cover object (carrier object) [108,109,110,111,112,113]. After this process, the cover object and stego-object (the object with the hidden information) are similar [114,115,116,117,118,119]. Thus, steganography (hiding information) and cryptography (protecting information) are different from each other [73, 120,121,122,123]. Recovering information without using steganalysis (the process of detecting steganography procedures) is difficult due to invisibility or the hidden factor [124,125,126,127,128,129]. In many steganography methods, binary data are usually hidden in the last significant bits (LSB) of the cover image pixel [130,131,132]. Ex-hide information in the special domain of greyscale images use a pixel differencing method [133, 134].
Terminologies of steganography technology
Some terminologies used in steganography are shown below.

As shown in Fig. 4, steganography is the process of embedding a secret message within the cover image by using a stego key to conceal data; the resulting image is called stego image [112, 114, 135,136,137]. The reverse of this operation is steganalysis, in which a stego key is used to extract the secret message from the stego image [138]. This operation can be performed without a stego key depending on the algorithm used to embed the data in the image.

Basic image steganography diagram
Types of steganography
Different approaches to steganography include spatial (direct manipulation of image intensities), frequency (indirect manipulation of the image through various transforms, such as DFT, DCT and DWT) and compression (substitution) domains [139].
The three approaches of steganography are as follows:
-
1)
Pure steganography: It uses steganography without combining other methods and hides information within a cover carrier.
-
2)
Secret key steganography: This method uses secret key cryptography technique via a secret key and the steganography approach to embed the secret message inside the cover.
-
3)
Public key steganography: This method combines public key cryptography and steganography to encrypt a secret message by using a public key and then embeds the message inside the cover.
As outlined above, steganography has different approaches that have the following specifications: The spatial domain approach provides high-capacity embedding for secret information and good visual quality for stego images but low resistance against statistical steganalysis. Compression domain techniques perform better in statistical steganalysis; however, this type of steganography has less embedding capacity and lower visual quality for stego images. Frequency domain methods are usually utilised in watermarking applications due to their immunity against image distortion attacks. Although numerous methods have been proposed for image steganography, limited studies have focused on metaheuristic-based image steganography [139]. Therefore, spatial domain steganography is the best way to hide a large-sized secret information inside the cover image. This technique, however, must be optimised using metaheuristic algorithms.
Basic LSB steganography method
In the cover image, the least significant bit in some or all of the bytes is changed with a bit of the secret information (message) [83]. For example, we have 3 pixels of an 8-bit cover image, which is illustrated as follows:
Suppose the secret message is number 5. When this number is converted into a binary representation, the result will be 101. Each bit from the message can be concealed inside the least significant bits. Thus, the output will be
Various types of steganography algorithms, such as object-based embedding, pixel value differencing and hiding data considering visual quality of image, are available.
Image steganography based on metaheuristic algorithm
Numerous methods described in the literature review cannot prevent visual degradation or provide a large embedding capacity. In this study, a tuneable visual image quality and data lossless method in the spatial domain based on particle swarm optimization (PSO) is recommended. Although many approaches have been proposed to conceal a secret message, only a few studies focused on metaheuristic-based image steganography. In [140], a secure JPEG steganography method based on genetic algorithm (GA) was proposed. This method is based on Out Guess, which has proven to be the least vulnerable steganographic system [141]. In this study, a steganography method was proposed based on the optimal pixel adjustment process and genetic algorithm. This approach modifies secret bits to have more compatibility during information hiding in the cover image. A steganography method that uses sessions and depends on the stego key and GA was proposed in [142]. This method is similar to other types of methods in terms of the use of encrypted secret data. The encryption operation can be divided into two steps: the first one uses the same processes, which have been applied by other methods, and the second one performs encryption optimised by GA. In [143], a GA-based steganography method that is secure against RS attacks was presented. In the first step, secret bits are concealed in the cover image, which is similar to the simple LSB. The second step involves modifying pixel values to place stego image RS parameters in secure parts. Reference [144] presented a GA-dependent steganography approach by separating the cover image into segments and then looking for the best sequence of these segments, which can be used for concealing. In study [139], a tuneable visual image quality and data lossless method in the spatial domain was proposed based on GA. The main idea of the proposed technique is to model the steganography problem as a search and optimisation problem.
To hide large amounts of data (FV features) successfully, we propose a new method of steganography based on metaheuristics using PSO algorithm with a new way of nonsequential embedding in the cover image. The results of the proposed methods are evaluated in detail in Section “Discussion”.
-
Particle swarm optimization
PSO is a computation mechanism that was developed in 1995 by Kennedy and Eberhart. This algorithm is ideal because it uses only a minimum number of parameters and can be used in many types of applications that have certain requirements [145, 146].
As a metaheuristic, PSO makes few or no assumptions about the problem being optimised and can search large spaces for candidate solutions [147, 148]. However, it does not guarantee an optimal solution. In addition, PSO does not use the gradient of the problem being optimised, which means that optimisation problems do not have to be differentiable unlike what is required by classic optimisation methods, such as gradient descent and quasi-Newton methods. In general, let f: ℝn → ℝ be the cost of the function where we need to minimise. The function holds a candidate solution as an argument in the form of a vector of real numbers and produces a real number as output. This output then indicates the objective function value of the given candidate solution. The gradient of (f) is not known. The goal is to determine a solution (a) for which f(a) ≤ f(b) for all (b) in the search space, which would mean a is the global minimum. Maximisation can be performed by considering the function h = −f instead.
Methodology
In this section, we present a detailed explanation of the proposed methodology for securing FV information within the FV biometric verification system.
Proposed new method: FV and RFID hybrid pattern integrated with blockchain technology (FV and RF hybrid pattern with blockchain)
Following the proposal on which this study is based, two stages are performed to ensure a secure framework for the FV biometric verification system. Stage one proposes a new hybrid model pattern to increase the randomisation based on RFID and FV biometrics. To achieve this goal, a new merge algorithm is proposed to combine the RFID features and FV features in one hybrid and random pattern. In the second stage, a new secure framework for telemedicine authentication uses a combination of encryption, blockchain and steganography techniques based on the hybrid pattern model proposed in the first phase to ensure that the FV biometric verification system remains secure during authentication. All the steps described above and the processes in the client and the server according to the proposed method are illustrated below:
Proposed method
Client side:
-
1.
FV images are preprocessed.
-
2.
FV features are extracted and converted into a binary string.
-
3.
RFID binary features extract and convert data into a binary string.
-
4.
Tow binary strings (FV binary and RFID binary) are merged in one string with random distribution using our proposed merge algorithm to produce a hybrid random pattern.
-
5.
Hashing function is implemented on a copy of the hybrid pattern. Hashing is sent to the server side to achieve information integrity. This hash will transform in the server side through the blockchain technique.
-
6.
Another copy of the hybrid pattern is encrypted and sent to the server as a blockchain. This pattern is used during matching operation and decision making to check if the patient is authorised or not (authentication process).
Server side:
-
1.
An encrypted copy of the hybrid pattern is already stored in the server data base prior to the receipt of the client request. The pattern is concealed using our proposed steganography method.
-
2.
Upon receipt of the client request (encrypted pattern and hashing), the hashing in the blockchain is verified by matching the hashing with the ledger. This ledger is used to store the patient’s hashing one by one in the server side. Matching hashing operation is performed for all patients except the first user (genesis user) to ensure that the information is from a trusted source and that information has not been modified by unauthorised persons.
-
3.
If the matching of hashing result is true, then (go to next step) the hybrid pattern is decrypted, and other processes commence. Otherwise, the system is attacked, that is, patient information has been altered or information was sent from an unauthorised location.
-
4.
A split operation is performed to split the FV features from RFID features using the proposed merge algorithm in reverse.
Simultaneously, the process in the server background is as follows:
-
5.
The hybrid pattern from the cover (stego image), which exists in the server through steganalysis, is extracted, and then the encrypted hybrid pattern information is decrypted into plain text (binary).
-
6.
A split operation is performed to split the FV features from RFID features by using the proposed merge algorithm in reverse.
-
7.
Two matching operations are performed between the FV feature from the client side and the FV feature extracted from the server database; the same operation is performed for RFID features.
-
8.
The patient is identified and verified if authorised or unauthorised.
All the processes in the client and server sides are illustrated in Fig. 5.

Client and server processes according to the proposed algorithm
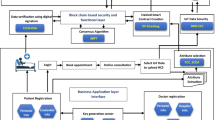
FV biometric verification system architecture
The FV biometric verification system comprises two parts: a client and more than one server. The client side performs the enrolment operation of the patients based on the FV biometrics and RFID to create a new hybrid and random FV biometric pattern model. A hash function is performed to produce hashing, which is used in blockchain technology to achieve integrity and authenticity. The hybrid pattern is encrypted using the AES algorithm to make the pattern information unreadable, thereby achieving confidentiality, according to the CIA triangle definition. Next, the patient (encrypted hybrid pattern and hashing) is sent to the server side based on blockchain technology. The first step in the server side is verification of the coming data block via blockchain technology to check data integrity and location authenticity. This process is described in detail in Subsection “Identification Phase”. In the server part, a copy of the encrypted hybrid biometric is stored in the server database using our proposed steganography method. Therefore, when the server receives the request from client side, and if the result of matching is true between the hash sent from the client with the hash in the ledger, then steganalysis is performed in the server background to extract the hybrid pattern from the cove image (stego image), and then this pattern is decrypted to split the RFID features from FV features. Finally, the RFID features sent from the client side are matched against a copy of the RFID features stored in the server side. If both sets of data match, then the FV features sent from the client side are matched against a copy of the FV features stored in the server side to check if the patient is genuine or an impostor. Before FV matching, if the RFID is mismatched, then a kill command is sent from the RFID reader to the tag to kill this tag. The architecture of the proposed framework is shown in Fig. 6.

Framework architecture
Discussion
The proposed methodology involves three phases. Each phase corresponds to one objective, as outlined in the research objectives. The first phase is the identification phase, in which FV biometric verification operation requirements, such as the proposed study case, data set and feature extraction for a new secure biometric model, are identified. This process is explained in detail in Subsection “Identification Phase”. The second phase is the development phase, which involves developing a secure new framework for an FV biometric verification system based on the identified new biometric model, as discussed in Subsection “Development phase”. The third phase describes the methods used to validate and evaluate the performance of the proposed steganography method and the whole proposed framework, as covered in Subsection “Validation and evaluation phase”. The phases of the methodology are shown in Fig. 7 and are explained below.

Research methodology phases
Identification Phase
In this study, a systematic review protocol of FV biometric individual verification was proposed. This protocol was applied during the literature review. A critical analysis was then performed to identify the research gap/gaps, highlights and challenges faced by developers and researchers. This phase aims to identify FV biometric verification operation requirements, that is, the study case, dataset, feature extraction and information security requirement standards, to achieve the new pattern model. In situations where FV features can be extracted using descriptor techniques, the authentication system architecture consists of two parts (client and server). In the client part, the features are extracted. The data is then sent to the server for authentication. In addition to the case studies, the blockchain technique is used to produce the hashing from biometric information to secure this information during data transmission. The existing FV features were analysed to determine the best way to enhance these features and produce a more secure pattern.
On the basis of the literature review, a new biometric pattern model for an FV biometric verification system was proposed to produce a hybrid biometric pattern (a combination of RFID binary string and FV binary features) and increase the randomisation in that hybrid biometric to enhance security levels in the client side. The sections below describe in detail the steps to achieving the results proposed in this phase.
Dataset
According to the literature review, the most suitable FV dataset used in this research is the MMCBNU_6000 database, which was created in the Multimedia Lab of the Chonbuk National University in South Korea and offered to scientific research. To test our proposed framework, we used this dataset with the university’s permission. The MMCBNU_6000 database was created between 29 January to 20 February 2013 and became ready to use in 2014. All FV patterns were collected from 100 volunteers from two different countries with different nationalities, gender and skin colour. The volunteers were aged between 16 and 72 years with blood groups of A, O, AB and B, with 10% unknown. The samples were collected from three fingers of each hand, with 10 images for each finger. The images were saved in BMP format, with an appendix containing ROI for all FV images [149, 150]. The image quality was high with a larger value of contrast, entropy value and grey value compared with other FV database images.
Preprocessing and feature extraction of FV images
FV is extracted from ROI, but other features extracted from nonvein regions are noisy. This result affects the verification performance, in which the ratio of the veins in the ROI is relatively small, e.g. approximately 41.05% in the MLA database and 44.32% in the PolyU Database [151]. This noise leads to more storage space and processing time, because the features are extracted from the entire pattern instead of the ROI. This issue is discussed in the next subsections. In our experiment, we use FV images from the MMCBNU_6000 database, as explained in the previous section. Preprocessing was applied on the FV image to obtain the ROI, and filters were used to remove the noise in preparation for feature extraction from the images, as described below.
Preprocessing
We use one FV image (left index finger) for each person. The original FV image is always low in contrast due to background noise, environment brightness and intensity fluctuations. Low-quality FV images have a negative impact on FV feature extraction. Image preprocessing should adjust the contrast to make the edges of the finger and the veins appear clearly. The next stage is detecting the vein ROI.
The preprocessing steps are explained in the following:

The images used in our experiment contain shaded areas in both ends (horizontal direction), leading to low detection. Thus, the FV can be aligned horizontally through the guiding bar, and the shaded areas can be extracted with predefined pixel sizes at both ends. As shown in Fig. 4.5, the finger region is brighter than the background region, because infrared light passes through the human skin. To determine the region of FV image, we use the masks shown in Figs. 8, a and b. The values of this mask are calculated in the Y direction for each X position, and the position at which the masking value becomes larger in value is determined as the boundary position between the finger and the background in the Y direction [152].

Masks used for localising the finger regions of the captured images: a Mask for detecting the upper region of the finger; b Mask for detecting the lower region of the finger
Figure 9 shows the result of localising the finger region with masks and the stretch operation performed on the FV image in the direction of the X and Y axes. The results is a 150 × 60 pixel image, as shown in Fig. 10. To enhance the time consumption, the stretched image is subsampled to 50 × 20 pixels by averaging the grey values for every 3 × 3 pixel block. The FV code has immunity against noise factors. The size of the block (3 × 3 pixels) was determined based on the width of the thinnest vein in the stretched image, which was measured as 3 pixels.

Result of localising the finger region with masks

Stretched images
FV feature extraction
Firstly, a vein detection algorithm is implemented and the maximum curvature method (MCM) is used. Afterwards, the feature extraction method is applied by using the histogram of oriented gradient (HOG) descriptors to obtain the features from the image.
Maximum curvature method (MCM)
In this method, the first step is to determine the cross-sectional profile of the FV image to extract the vein centreline with different widths and brightness, where the blood veins appear as a dark line, as shown in Fig. 11. The concave curves have large curvatures to extract high-quality features without affected by vein width turn the focusing should be on positions of the centre lines of veins. This score becomes larger when the cavity is deep or wide. The local maximum curvatures in the cross-sectional profile can be calculated [153].

Cross-sectional profile of veins
F is a finger image, and F(x, y) is the intensity of pixel (x, y). We define Pf(z) as a cross-sectional profile acquired from F(x, y) at any direction and position, where z is a position in a profile. For instance, Pf(z) is acquired from F(x, z) in the vertical direction, as shown in Fig. 4.8. To relate a position of Pf(z) to that of F(x, y), the mapping function Trs is defined as F(x, y) =Trs(Pf(z) ).
The curvature,  (z) can be represented as shown in Eq. (1)
(z) can be represented as shown in Eq. (1)

A profile is classified as concave or convex based on whether  (z) is positive or negative. If
(z) is positive or negative. If  (z) is positive, then the profile Pf(z) is a dent (concave).
(z) is positive, then the profile Pf(z) is a dent (concave).
In this step, the local maxima of  (z) in each concave area are calculated. These points indicate the centre positions of the veins. The position of these points is defined as\( {z}_i^{\prime } \), where i = 0, 1, 2 … . , N − 1, and N is the number of local maximum points in the profile.
(z) in each concave area are calculated. These points indicate the centre positions of the veins. The position of these points is defined as\( {z}_i^{\prime } \), where i = 0, 1, 2 … . , N − 1, and N is the number of local maximum points in the profile.
Next, the scores that refer to the possibility of determining the centre positions of veins can be determined for each centre position. A score, Scr(z), is defined in Eq. (2).

where Wr(i) is the width of the region where the curvature is positive, as demonstrated in Fig. 12.

Relationship amongst profile, curvature and probability score of veins
IfWr(i), which illustrates the width of a vein, is large, which may indicate that a vein is also large. Furthermore, the curvature will be large in the centre of the veins when the imaging is clear; therefore, the width and the curvature of regions are considered in their scores. Scores are assigned to a plane, V, which is a result of the emphasis of the veins, that is,
where \( \left({x}_i^{\prime },{y}_i^{\prime}\right) \) represents the points defined by \( F\left({x}_i^{\prime },{y}_i^{\prime}\right) \) =\( {T}_{rs}\left({P}_f\left({z}_i^{\prime}\right)\ \right) \).
All the profiles in a direction are analysed to obtain the vein pattern distributed in an entire image. To obtain the vein pattern distributed in all directions, all profiles in the four directions need to be analysed, The used directions are horizontal, vertical and the two oblique directions intersecting the horizontal and vertical at 45°. Consequently, the centre positions of the blood vein images are recognised by determining the local maximum curvatures.
Next, all the vein centres are connected, and noise is eliminated. Filters are used to check the determined twin pixels on the right and left sides of pixel (x, y). The following equation illustrates this operation.
The operation is applied to all pixels for each of the four directions in the same way, then Cd2, Cd3 and Cd4 are obtained.
Finally, a final image, G(x, y), is obtained by selecting the maxima of Cd1, Cd2, Cd3 and Cd4 for each pixel.
The last step is converting G into a binary image using a threshold. This algorithm in practice is shown in Fig. 13.

MCM Output
Histogram of oriented gradient (HOG) descriptors
HOG is a gradient-based feature descriptor originally developed for human detection [154]. One of the advantages of deploying this technique is that HOG can capture the gradient structure, which can characterise the local shape effectively. Such operations are performed in a local representation with a controllable degree of invariance to local geometric and photometric transformations. That is, if translations or rotations are much smaller than the local spatial or orientation bin size, it will only make a little difference, which is helpful for vein detection, because most FV images are prone to great variance in terms of finger position, translations or rotations, which result in small variations if they are much smaller than the local spatial or orientation bin size. The image is divided into m number of non-overlapping cells, where rectangular cells are used. Each cell contains h bins. The cells do not overlap, thereby reducing the dimension of the descriptor; thus, the resulting descriptor is an m ∗ h dimensional feature vector. In this study, the resulting image that contains the detected vein is 64 × 128 pixels. The selected cell size is 8 × 16 (\( \boldsymbol{m}=\left(\frac{\mathbf{64}}{\mathbf{8}}\ast \frac{\mathbf{128}}{\mathbf{16}}\right)=\mathbf{64}\Big), \)and the number of bins is 12, (h = 12). Resulting in a 768-dimensional feature vector, each one being a single number between 0 and 1, the features are then converted into a binary format. Each single number is converted into a 16-bit binary number. Therefore, the total size of FV features is 32 × 768 = 24,576 bits.
RFID binary string extraction and conversion into binary matrix
We use passive high-frequency RFID, as expressed in the literature review. This type of RFID possesses near contact of up to 30 cm and a tag that consists of microchips that can read and write. With this tag, we can overwrite existing data when the tag is within the range of the reader even though these tags have a serial number that cannot be overwritten. Despite this condition, these tags have space for additional data unlike read-only tags that have the information from the manufacturers that cannot be changed. WORM tags have serial numbers from the manufacturers that cannot be overwritten. The amount of data stored inside the tag depends on the vendor and type of application, generally with no more than 2 KB of data and only 96 or 128 bits for the serial number. However, data transmission between the tag and reader is not a secure channel because of the high risk of interruption and theft from unauthorised persons [87].
To overcome this challenge, we use a high-frequency RFID smart card ticket, which requires a distance between the tag and reader of not more than 30 cm (near contact up), thereby ensuring that the information contained in the RFID cannot be accessed from a long distance. To achieve this requirement, they needed to use UHF type to store large amounts of data of approximately 4–8 KB for long-distance communication. This amount of data is not needed in this study because the RFID serial number requires 128–512 bits. In the proposed model, we use the serial number of the RFID smart card together with the FV biometrics; if anyone attempts to use the RFID alone or with different FV features, then the reader will send a code or bin as a kill command at the point of usage to make the tag unusable. The RFID used in this study is 38 binary bits and contains the chaotic function ID and manipulation choices for the merging process.
RFID format
The first 32 bits are a unique binary pattern. The next 2 bits are for manipulation instructions, as shown in Fig. 14.

RFID Format
The last 4 bits are for K of the chaotic function, which indicate a value between 8 and 15. For example, 1011 equals 11. This value is used in Eq. (5). Table 3 shows the possible values for pole and direction.
To merge the FV biometric binary string with the RFID binary string, we propose a merge algorithm to produce a hybrid biometric, which is a combination of FV and RFID features as one-dimensional binary string with random distribution, to make this hybrid pattern ambiguous and more secure in case attacks occur during transmission between client and server.
Proposed merge algorithm
The merge algorithm is proposed to secure the pattern during enrolment, thereby preventing attackers from discerning which data set is the biometric binary string. This algorithm uses the RFID binary string and biometric binary string in a random matrix, which is extracted from the FV. This algorithm works properly when the RFID is changed in the future for any reason. To merge the RFID data with FV features, three steps are involved. The first step is a simple concatenation. In the second step, depending on the information from the RFID bits, some manipulation is implemented on the binary data. In the third step, a chaotic function is implemented on the data with the equation given in (5) and (6), where K is the chaos degree. In our application, it is derived from the RFID bit that brings the number to between 8 and 15.
This chaotic function is called the standard map, which is also known as the Chirikov–Taylor map or the Chirikov standard map. The following is a pseudo code that demonstrates the proposed merging method.
Merging method:

Hashing and producing data as blockchain
To secure the hybrid biometric pattern that is produced as a one-dimensional binary string, two copies of the hybrid pattern are produced. Cryptography is then implemented using the AES encryption algorithm on one copy of the pattern to send data to the server side. As shown in Fig. 15, the hashing function is implemented on the other copy of the hybrid pattern by sending this hashing from the client to the server side to use it as hashing in blockchain technology and for hashing generation.

Blockchain hashing generation
Using hashing, the arbitrary amount can be obtained from the input data and the generated fixed size of output data called hash. The input can be any number of bits that can represent characters of any size, whereas the output is of a fixed size depending on our selection. For example, for the (256,512) bit size in this research, we use the MD5 hashing function.
Nowadays, a hash is commonly used as a fingerprint file and as a check to verify whether the file has not been modified in any way that is not intended by the author.
-
How does blockchain make use of hashing?
Hashes are used in blockchain to represent the current state. As a result, the input represents the state of the blockchain (all transactions that have taken place so far), whereas the output of the hash represents the current state of the blockchain.
-
How these hashes are calculated
The hash of the first data block is calculated, that is, the genesis block (hybrid pattern for the first patient) using the MD5 hash function. This pattern is then sent to the server side for storage in the ledger (record for all user hashing). The operation is repeated for the second user and so on. When the data block from the second patient reaches the server (i.e. the data block containing the encrypted hybrid pattern and the current and previous patient hashing as shown in Fig. 15), the first operation is to check the hash for the previous patient (these data are already stored in the ledger) against the hash of the current to verify if the source can be trusted or not.
This system of hashing guarantees that the data cannot be modified, because once a single part changes, the hash of the entire block will also change, making the detection of any changes easy.
Development phase
The general problem in FV biometric verification systems is how to protect biometric information from leakage, because the data cannot be replaced if it is stolen. Therefore, this phase aims to present the complete framework of patient authentication. A new secure framework for FV biometric verification system based on identifying a new biometric model (produced in Phase 2) is developed. The proposed secure framework performs two layers of protection in the server on pattern information. The first layer is already defined in the client (cryptography) on the new hybrid pattern. However, this protection for pattern information is not sufficient, because the pattern information is still visible in spite of the encryption. This aspect is covered in detail in Section “Proposed new method: FV and RFID hybrid pattern integrated with blockchain technology (FV and RF hybrid pattern with blockchain)”. The second layer (steganography) must be applied to reinforce information security further by concealing the pattern information. During this phase, the matching algorithm is implemented, enhancing accuracy in matching and determining whether or not the patient is authorised.
Decryption using the AES algorithm
As outlined in Subsection (2.1.2.1) of the literature review, the most suitable encryption algorithm is AES, which is a symmetric key encryption standard that is used to secure data. This algorithm can encrypt long plain texts with high efficiency [81]. This algorithm supports a data block of 128 bits with a variable key size of 128, 192 and 256 bits [80]. It obtains satisfactory results for speed in software and hardware implementation. It can also be used in different platforms, especially in small devices [77]. The AES algorithm process is as follows:
-
i.
The algorithm procedure steps are as follows:

-
ii.
Usual round: Execute the following operations:

-
iii.
Final round: Execute the following operations:

-
iv.
Encryption: Each round consists of the following four steps:

The aforementioned steps represent the key schedule; the last round for encryption does not contain the ‘Mix columns’ step.
-
v.
Decryption consists of all steps of encryption but in reverse, such as

To increase the efficiency of data encryption using AES, this process must be implemented with a key size of 192 bits and with 12 rounds of iteration unlike the basic AES model, which has 128 bits and 10 rounds of iterations [81].
LSB-based steganography
The LSB method is one of the spatial domain steganography methods and involves replacing the LSB in the cover image by one bit from the encrypted data. This method is a simple approach to embedding encrypted data within the cover image. When using a 24-bit cover image, one bit each of the red, green and blue colour components can be used, because they are each represented by a byte. This process has two algorithms: one for embedding encrypted data within the cover image and the other for retrieving the data from the cover image. The algorithm for embedding the hybrid-encrypted pattern binary information is as follows:

The algorithm to retrieve the hybrid-encrypted pattern binary information is as follows:

PSO algorithm
The concept of this algorithm is produced from a simulation of a simplified social system. PSO primarily aims to simulate the graceful but unpredictable movements of a flock of birds graphically. Some updates have been implemented to match ancillary variable elimination and multidimensional search and acceleration by distance. Developing this algorithm proves that the conceptual model is an optimiser. This algorithm is similar to a GA, because the system is initialised with a population of random solutions. Unlike a GA, however, each potential solution is also assigned a randomised velocity. The potential solutions, called particles, are then ‘flown’ through the problem space. Each particle tracks its coordinates in the problem space, which are associated with the best solution (fitness) it has achieved. The fitness value called a ‘pbest’ is also stored. The global version of the particle swarm optimiser tracks another ‘best’ value. This value is the overall best value and its location is obtained by any particle in the population in real time. This location is called ‘gbest’. At each step, the particle swarm optimisation concept consists of changing the velocity (accelerating) of each particle towards its ‘pbest’ and ‘gbest’ locations (global version of PSO). Acceleration is weighted by a random term, with separate random numbers being generated for acceleration towards ‘pbest’ and ‘gbest’ locations.
Proposed steganography method based on PSO algorithm
In this study [139], a method for hiding message bits inside an image called a host image is proposed using GA. Hiding a message in an image in different places is possible, although each place will cause a different distortion in the image. GA has been used to determine the best place for hiding data in the host image. The best place refers to a location where a message could be hidden with the least possible distortion. This method determines the start pixel, the number of least used significant bits in each pixel and the sequence of scanning image pixels to hide message bits.
The raster order of pixels in the LSB substitution method is the order of pixels in the cover image. The scan of these pixels starts from left to right and from the first row to the last row for all rows in the cover image. If we have an image with a dimension of 5 × 5, then the raster order is as shown in Fig. 16.

Raster order
The general idea of this approach is to convert the steganography problem as a search and optimisation problem. In other words, the order shown in Figs. 17 and 18 perhaps presents a better order than the raster order. Consequently, various orders and positions in the cover image can be used to embed the secret message, which produces various PSNRs. Therefore, the problem of the direction of pixel scanning has 16 possible solutions. If we design the new method for checking all possible orders to identify the best order for the cover image, then the result can be improved from basic LSB steganography.

Pixel scanning order 1

Pixel scanning order 2
The mentioned study uses sequential method in scanning image pixels (columns from right to left or reverse and rows from up to down or reverse) in the whole image, thereby making the determination of the best place to hide the message challenging, because scanning inside a window from the image is better than scanning inside the whole image.
To enhance the ability of the mentioned method, the sequential scanning inside the whole image was replaced by sequential scanning inside a window from the image with a suitable size for the message. As a result, the old method becomes a special case from our proposed method, and the new method is a generalisation of the old method.
Moreover, GA was replaced by PSO.
In the proposed technique, the particle has the following variables:

The proposed method contains nine particles, which are indicated in Table 4.
Table 5 indicates all possible cases of scanning.
Furthermore, two constraints must be satisfied.

In the last row of the cover image, the particle bits are embedded for extraction during steganalysis. The scanning direction in the cover image pixels has 16 possible cases; in our proposed method, the particle representation has a length of 4 bits. The beginning of scanning point can be represented as two particles, including X-offset and Y-offset, with a length of 8 bits for each. To define LSB planes in the cover image pixels used (Bit-Planes) particles, all the possible values for Bit-Planes are shown in Table 6.
To determine the secret Bits-Pole used (SB-Pole), SB-Dire is used to define the direction of message bits (secret information), and the last particle is BP-Dire, which shows the direction of LSB planes. Table 7 illustrates the last three particles. Consequently, in our proposed method, the particles can be classified into two sets: the first set consists of the particles that pointed out insertion of the secret bits in the cover image, and the second set consists of particles used to make changes in secret message information (Hybrid pattern) to increase adaptability with the cover image.
The proposed update directs the algorithm to determine the best window that can maximise the value of PSNR between the original (cover image) and the stego image. To obtain even better results, a new idea is to split the secret message and the cover image into four blocks, as shown in Fig. 19, and to apply the proposed algorithm on each block. In this manner, each block will be treated as a separate image, and in the end, they will be combined.

Proposed algorithm with four blocks
Validation and evaluation phase
Securing FV biometric information is a crucial task that has presented a considerable challenge to researchers and developers. In this phase, the proposed framework is evaluated to determine if the goals of this research are achieved. The validation seeks to determine whether or not the proposed framework is appropriate for this purpose and if the framework overcomes the identified limitations to perform as expected.
Validation
Security analysis is performed to validate the proposed framework. The FV biometric verification system is prone to two types of attacks: spoofing and brute-force attacks [55].
Evaluation
During this stage, two types of evaluations are implemented. The first one considers our steganography proposed method using histogram and calculates the PSNR value between cover and stego images, and the second evaluation regards the performance of the proposed framework.
Fifty subjects from the dataset (index finger from left hand) are used to check the matching result using the MATLAB application. We use the following metrics for biometric system evaluation:
False acceptance rate (FAR) and false rejection rate (FRR)
To evaluate the matching score in any biometric system and recognise if a user is authorised, the operation is dependent on the security requirements and the number of thresholds (if the threshold is too low, genuine users will be rejected, and if the threshold is too high, then impostors could enter the system). The FAR and FRR metrics can be defined as follows:
FAR and FRR are dependent on the threshold; by increasing the threshold,
Equal error rate (EER)
As mentioned previously, when decreasing the threshold, more authorised individuals will be rejected and a fewer number of unauthorised individuals will be accepted simultaneously. At some point during the process, the FAR and FRR become equal. This point of equilibrium is known as the EER. EER does not give any information about the values of FAR and FRR at different thresholds; however, it can be used to compare different biometric systems.
According to the equations above, the FAR and FRR values must be calculated for all users in our experiment. The FAR is calculated as a fraction of impostor scores exceeding the threshold, whereas the FRR is calculated as a fraction of genuine scores falling below the threshold. We have the features extracted from the message and from the steganalysis. To determine if it is a match, the Euclidean distance is used. For each threshold, FAR and FRR can be calculated using the definition stated above.
The following pseudo codes present how we calculated the FAR and FRR:

Receiver Operating Characteristic Curve
An ROC was used to explain the relationship between the FAR and FRR, in which the x-axis represents the FAR, and the y-axis represents the FRR to show the impostor rate. This curve helped simplify the performance of biometric systems. In Fig. 20, the basic ROC curves are shown, and FAR and FRR are functions of a threshold T and can be shown as follows:

Sample ROC Curves
As seen in the equation above, FAR and FRR are opposites of each other. As one increases, the other decreases.
Conclusion
Studies related to telemedicine application security have several limitations that remain unaddressed. The interconnected parts of telemedicine architecture need to be more secure, starting from the client to the server side. This work mainly contributes a comprehensive review for studies related to the topic. Our study provides a multilayer, comprehensive overview to propose a secure new framework for an FV biometric verification system for telemedicine architecture. Articles were analysed to highlight the open issues and challenges and address the research gaps related to enhancing security levels and establishing a secure verification method for real-time monitoring systems for the authentication of patients and other individuals who use telemedicine systems. Primary challenges were found in securing information from the FVs, such as feature extraction and how to create a hybrid patient biometric pattern, that is, protecting biometric information in terms of information security standards (CIA). Other issues related to these challenges included authenticity of patient location, securing biometric information in a communication channel and protecting biometric templates in the server. Studies that attempted to address these issues were criticised to identify the gaps in their approaches and to produce the best solution. These studies also summarised and outlined the methodological aspects of protecting FV information within the FV biometric verification system. The present research identified the research problem and main objectives, listed the major steps of the identification process and proposed a new authentication method based on FV and RFID. This pattern was integrated with the concept of blockchain technology, encryption and steganography. The recommended solution was to identify a hybrid and random biometric pattern via the proposed merged algorithm. An improved method for increasing information security requirements was identified based on blockchain technology and was addressed in detail. In addition, PSO algorithm-based steganography was proposed as an important factor in the proposed framework. The methodological aspects were presented based on three main phases. Each phase corresponded to a major distinct step in producing the anticipated output. The proposed framework enables telemedicine architecture in patient and healthcare staff authentication whilst enhancing security levels by protecting FV features in the client and server sides and in the communication channel during real-time authentication. The proposed framework will be simulated and implemented in our next study to serve as a guide for guaranteeing security in telemedicine architecture.
References
Poon, C. C. Y., and Zhang, Y.-T.-D. B., A Novel Biometrics Method to Secure Wireless Body Area Sensor Networks for Telemedicine and M-Health Networks for Telemedicine and M-Health. IEEE Commun. Mag. 44:73–81, 2006.
Kiah, M. L. M., Zaidan, B. B., Zaidan, A. A., Nabi, M., and Ibraheem, R., MIRASS: Medical Informatics Research Activity Support System Using Information Mashup Network. J. Med. Syst. 38(4):37, 2014.
Zaidan, B. B., Haiqi, A., Zaidan, A. A., Abdulnabi, M., Kiah, M. L. M., and Muzamel, H., A Security Framework for Nationwide Health Information Exchange based on Telehealth Strategy. J. Med. Syst. 39(5):51, 2015.
Mat Kiah, M. L., Al-Bakri, S. H., Zaidan, A. A., Zaidan, B. B., and Hussain, M., Design and Develop a Video Conferencing Framework for Real-Time Telemedicine Applications Using Secure Group-Based Communication Architecture. J. Med. Syst. 38(10):133, 2014.
Alsalem, M. A. et al., Systematic Review of an Automated Multiclass Detection and Classification System for Acute Leukaemia in Terms of Evaluation and Benchmarking, Open Challenges, Issues and Methodological Aspects. J. Med. Syst. 42(11):204, 2018.
Abdulnabi, M., Al-Haiqi, A., Kiah, M. L. M., Zaidan, A. A., Zaidan, B. B., and Hussain, M., A distributed framework for health information exchange using smartphone technologies. J. Biomed. Inform. 69:230–250, 2017.
Alsalem, M. A. et al., A review of the automated detection and classification of acute leukaemia: Coherent taxonomy, datasets, validation and performance measurements, motivation, open challenges and recommendations. Comput. Methods Prog. Biomed. 158:93–112, 2018.
Enaizan, O., et al., Electronic medical record systems: decision support examination framework for individual, security and privacy concerns using multi-perspective analysis. Health Technol. (Berl). 1–28, 2018.
Zaidan, A. A., Zaidan, B. B., Al-Haiqi, A., Kiah, M. L. M., Hussain, M., and Abdulnabi, M., Evaluation and selection of open-source EMR software packages based on integrated AHP and TOPSIS. J. Biomed. Inform. 53:390–404, 2015.
Kiah, M. L. M., Haiqi, A., Zaidan, B. B., and Zaidan, A. A., Open source EMR software: profiling, insights and hands-on analysis. Comput. Methods Prog. Biomed. 117(2):360–382, 2014.
Zaidan, A. A., Zaidan, B. B., Hussain, M., Haiqi, A., Mat Kiah, M. L., and Abdulnabi, M., Multi-criteria analysis for OS-EMR software selection problem: A comparative study. Decis. Support. Syst. 78:15–27, 2015.
Zaidan, A. A., Zaidan, B. B., Kadhem, Z., Larbani, M., Lakulu, M. B., and Hashim, M., Challenges, Alternatives, and Paths to Sustainability: Better Public Health Promotion Using Social Networking Pages as Key Tools. J. Med. Syst. 39(2):7, 2015.
Hussain, M. et al., The landscape of research on smartphone medical apps: Coherent taxonomy, motivations, open challenges and recommendations. Comput. Methods Prog. Biomed. 122(3):393–408, 2015.
Zaidan, A. A. et al., A review on smartphone skin cancer diagnosis apps in evaluation and benchmarking: coherent taxonomy, open issues and recommendation pathway solution. Health Technol. (Berl). 8(4):223–238, 2018.
Alanazi, H. O., Zaidan, A. A., Zaidan, B. B., Kiah, M. L. M., and Al-Bakri, S. H., Meeting the Security Requirements of Electronic Medical Records in the ERA of High-Speed Computing. J. Med. Syst. 39(1):165, 2015.
Nidhal, S., Ali, M. A. M., Zaidan, A. A., Zaidan, B. B., and Najah, H., Computerized algorithm for fetal heart rate baseline and baseline variability estimation based on distance between signal average and alpha value. Int. J. Pharmacol. 7(2):228–237, 2011.
Yas, Q. M., Zaidan, A. A., Zaidan, B. B., Hashim, M., and Lim, C. K., A systematic review on smartphone skin cancer apps: Coherent taxonomy, motivations, open challenges and recommendations, and new research direction. J. Circuits, Syst. Comput. 1830003, 2017.
Rajan, S. P., Review and investigations on future research directions of mobile based telecare system for cardiac surveillance. Journal of Applied Research and Technology 13(4. Universidad Nacional Autónoma de México, Centro de Ciencias Aplicadas y Desarrollo Tecnológico.):454–460, 2015.
Negra, R., Jemili, I., and Belghith, A., Wireless Body Area Networks: Applications and Technologies. Procedia Comput. Sci. 83:1274–1281, 2016.
Albahri, A. S., Zaidan, A. A., Albahri, O. S., Zaidan, B. B., and Alsalem, M. A., Real-Time Fault-Tolerant mHealth System: Comprehensive Review of Healthcare Services, Opens Issues, Challenges and Methodological Aspects. J. Med. Syst., 2018.
Albahri, O. S. et al., Systematic Review of Real-time Remote Health Monitoring System in Triage and Priority-Based Sensor Technology: Taxonomy, Open Challenges, Motivation and Recommendations. J. Med. Syst. 42(5), 2018.
Albahri, O. S., Zaidan, A. A., Zaidan, B. B., Hashim, M., Albahri, A. S., and Alsalem, M. A., Real-Time Remote Health-Monitoring Systems in a Medical Centre: A Review of the Provision of Healthcare Services-Based Body Sensor Information, Open Challenges and Methodological Aspects. J. Med. Syst. 42(9):164, 2018.
Salman, O. H., Zaidan, A. A., Zaidan, B. B., Kalid, N., and Hashim, M., Novel Methodology for Triage and Prioritizing Using ‘Big Data’ Patients with Chronic Heart Diseases Through Telemedicine Environmental. Int. J. Inf. Technol. Decis. Mak. 16(05):1211–1245, 2017.
Albahri, A. S., Zaidan, A. A., Albahri, O. S., Zaidan, B. B., and Alsalem, M. A., Real-Time Fault-Tolerant mHealth System: Comprehensive Review of Healthcare Services, Opens Issues, Challenges and Methodological Aspects. J. Med. Syst. 42(8. Springer US):137, 2018.
Shuwandy, M. L., Zaidan, B. B., Zaidan, A. A., and Albahri, A. S., Sensor-Based mHealth Authentication for Real-Time Remote Healthcare Monitoring System: A Multilayer Systematic Review. J. Med. Syst. 43(2):33, 2019.
Talal, M. et al., Smart Home-based IoT for Real-time and Secure Remote Health Monitoring of Triage and Priority System using Body Sensors: Multi-driven Systematic Review. J. Med. Syst. 43(3):42, 2019.
Albahri, A. S., et al., Fault-Tolerant mHealth Framework in the Context of IoT Based Real-Time Wearable Health Data Sensor. IEEE Access, 2019.
Albahri, O. S., et al., Based multiple heterogeneous wearable sensors: a smart real-time health-monitoring structured for hospitals distributor. IEEE Access. 1, 2019.
Kalid, N. et al., Based on Real Time Remote Health Monitoring Systems: A New Approach for Prioritization ‘Large Scales Data’ Patients with Chronic Heart Diseases Using Body Sensors and Communication Technology. J. Med. Syst. 42(4), 2018.
Mohsin, A. H. et al., Real-Time Remote Health Monitoring Systems Using Body Sensor Information and Finger Vein Biometric Verification: A Multi-Layer Systematic Review. J. Med. Syst. 42(12):238, 2018.
Kalid, N., Zaidan, A. A., Zaidan, B. B., Salman, O. H., Hashim, M., and Muzammil, H., Based Real Time Remote Health Monitoring Systems: A Review on Patients Prioritization and Related" Big Data" Using Body Sensors information and Communication Technology. J. Med. Syst. 42(2):30, 2018.
Mishra, D., and Mukhopadhyay, S., Security Enhancement of Biometric Authentication Scheme for Telecare Medicine Information Systems with Nonce. J. Med. Syst. 37(5):1–24, 2013.
Nabi, M. S., Kiah, M. L. M., Zaidan, A. A., and Zaidan, B. B., Suitability of adopting S/MIME and OpenPGP email messages protocol to secure electronic medical records. In: Second International Conference on Future Generation Communication Technologies (FGCT 2013), pp. 93–97, 2013.
Iqbal, S., et al., Real-time-based E-health systems: design and implementation of a lightweight key management protocol for securing sensitive information of patients,” Health Technol. (Berl)., pp. 1–19, 2018.
Zaidan, B. B., Zaidan, A. A., and Mat Kiah, M. L., Impact of data privacy and confidentiality on developing telemedicine applications: A review participates opinion and expert concerns. Int. J. Pharmacol. 7(3):382–387, 2011.
Hameed, S. A., Zaidan, B. B., Zaidan, A. A., Naji, A. W., and Tawfiq, O. F., An accurate method to obtain bio-metric measurements for three dimensional skull. J. Appl. Sci. 10(2):145–150, 2010.
Shihab, A. H., Zaidan, B. B., Zaidan, A. A., Naji, A. W., and Omar, F., Accurate Method to Measure Three Dimensional Skull Bio-Metric. J. Appl. Sci. 10(2):145–150, 2010.
Brogan, J., Baskaran, I., and Ramachandran, N., Authenticating Health Activity Data Using Distributed Ledger Technologies. Comput. Struct. Biotechnol. J. 16:257–266, 2018.
Hameed, S. A., Zaidan, B. B., Zaidan, A. A., Naji, A. W., and Faroq, O., Novel Simulation Framework of Three-Dimensional Skull Bio-Metric Measurement. International J. Comput. Sci. Eng. 1(3):269–274, 2009.
Zaidan, B. B., Zaidan, A. A., and Mwafak, H., New Comprehensive Study to Assess Comparatively the QKD, XKMS, KDM in the PKI encryption algorithms. Int. J. Comput. Sci. Eng. 1(3):263–268, 2009.
Talib, Y. Y. A., Zaidan, B. B., Zaidan, A. A., and Naji, A. W., Optimizing security and flexibility by designing a high security system for E-government servers. ICOCI09, Univ. Utara Malaysia, 2009.
Hussain, M. et al., Conceptual framework for the security of mobile health applications on Android platform. Telemat. Informatics 35(5):1335–1354, 2018.
Hussain, M. et al., A security framework for mHealth apps on Android platform. Comput. Secur. 75:191–217, 2018.
Watari, M. A., Zaidan, A. A., and Zaidan, B. B., Securing m-Government Transmission Based on Symmetric and Asymmetric Algorithms: A review. Asian J. Sci. Research 8:80–94, 2013.
Alanazi, H., Noor, R. M., Zaidan, B. B., and Zaidan, A. A., Intrusion detection system: overview. arXiv Prepr. arXiv1002.4047, 2010.
Raad, M., Yeassen, N. M., Alam, G. M., Zaidan, B. B., and Zaidan, A. A., Impact of spam advertisement through e-mail: A study to assess the influence of the anti-spam on the e-mail marketing. Afr. J. Bus. Manag. 4(11):2362–2367, 2010.
Medani, A., Gani, A., Zakaria, O., Zaidan, A. A., and Zaidan, B. B., Review of mobile short message service security issues and techniques towards the solution. Sci. Res. Essays 6(6):1147–1165, 2011.
Naji, A. W., Housain, A. S., Zaidan, B. B., Zaidan, A. A., and Hameed, S. A., Security improvement of credit card online purchasing system. Sci. Res. Essays 6(16):3357–3370, 2011.
Hussain, M. et al., The rise of keyloggers on smartphones: A survey and insight into motion-based tap inference attacks. Pervasive Mob. Comput. 25:1–25, 2016.
Alanazi, H. O., Mat Kiah, M. L., Zaidan, A. A., Zaidan, B. B., and Alam, G. M., Secure topology for electronic medical record transmissions. Int. J. Pharmacol. 6(6):954–958, 2010.
Hamdan, O. A., Gazi, M. A., Zaidan, B. B., and Zaidan, A. A., Securing electronic medical records transmissions over unsecured communications: An overview for better medical governance. J. Med. Plant Res. 4(19):2059–2074, 2010.
Nabi, M. S. A., Kiah, M. L. M., Zaidan, B. B., Zaidan, A. A., and Alam, G. M., Suitability of Using SOAP Protocol to Secure Electronic Medical Record Databases Transmission. Int. J. Pharmacol. 6(6):959–964, 2010.
Nandhinipreetha, A., and Radha, N., Multimodal biometric template authentication of finger vein and signature using visual cryptography. 2016 Int. Conf. Comput. Commun. Informatics, ICCCI 2016, pp. 7–10, 2016.
Suzuki, H., Suzuki, M., Urabe, T., and Obi, T., Secure biometric image sensor and authentication scheme based on compressed sensing. Appl. Opt. 52(33):8161–8168, 2013.
Wu, Z., Tian, L., Li, P., Wu, T., Jiang, M., and Wu, C., Generating stable biometric keys for flexible cloud computing authentication using finger vein. Inf. Sci. (Ny).:1–17, 2016.
Cheng, Y., Chen, H., and Cheng, B., Special point representations for reducing data space requirements of finger-vein recognition applications. Multimed. Tools Appl. 76(278), 2016.
Chavez-Galaviz, J., Ruiz-Rojas, J., and Garcia-Gonzalez, A., Embedded biometric cryptosystem based on finger vein patterns. 2015 12th Int. Conf. Electr. Eng. Comput. Sci. Autom. Control. CCE 2015, pp. 1–6, 2015.
Jagadiswary, D., and Saraswady, D., Biometric Authentication using Fused Multimodal Biometric. Procedia - Procedia Comput. Sci. 85(CMS):109–116, 2016.
Jialiang Peng, X. N., Li, Q., and Abd El-Latif, A. A., Finger multibiometric cryptosystems: fusion strategy and template security. J. Biomed. Opt. 19(2):020901, 2014.
Murakami, T., Ohki, T., and Takahashi, K., Optimal sequential fusion for multibiometric cryptosystems. Inf. Fusion 32:93–108, 2016.
Alanazi, H. O., Using the features of mosaic image and AES cryptosystem to implement an extremely high rate and high secure data hidden : Analytical study. Sci. Res. Essays 5(21):3254–3260, 2010.
Zaidan, A. A., Zaidan, B. B., Taqa, Y. A., Sami, M. K., Alam, G. M., and Jalab, A. H., Novel multi-cover steganography using remote sensing image and general recursion neural cryptosystem. Academic Journals 5(11), 2010.
Zaidan, B. B., Zaidan, A. A., Taqa, A., Alam, G. M., Kiah, M. L. M., and Jalab, H., StegoMos: A secure novel approach of high rate data hidden using mosaic image and ANN-BMP cryptosystem. Int. J. Phys. Sci. 5(11):1796–1806, 2010.
Naji, A. W., Zaidan, A. A., Zaidan, B. B., and Muhamadi, I. A. S., Novel approach for cover file of hidden data in the unused area two within EXE file using distortion techniques and advance encryption standard. Proceeding World Acad. Sci. Eng. Technol. 56(5):498–502, 2010.
Naji, A. W., Hameed, S. A., Al-khateeb, W. F., Khalifa, O. O., and Gunawan, T. S., Novel Framework for Hidden Data in the Image Page within Executable File Using Computation between Advanced Encryption Standard and Distortion Techniques. Int. J. Comput. Sci. Inf. Secur. 3(1):1–6, 2009.
Abomhara, M., Zakaria, O., Khalifa, O. O., Zaidan, A. A., and Zaidan, B. B., Enhancing Selective Encryption for H. 264/AVCUsing Advanced Encryption Standard. Int. J. Comput. Electr. Eng. 2(2):223, 2010.
Abomhara, M., Khalifa, O. O., Zakaria, O., Zaidan, A. A., Zaidan, B. B., and Alanazi, H. O., Suitability of using symmetric key to secure multimedia data: An overview. J. Appl. Sci. 10(15):1656–1661, 2010.
Alanazi, H., Zaidan, B. B., Zaidan, A. A., Jalab, H. A., Shabbir, M., and Al-Nabhani, Y., New comparative study between DES, 3DES and AES within nine factors. arXiv Prepr. arXiv1003.4085, 2010.
Salem, Y., Abomhara, M., Khalifa, O. O., Zaidan, A. A., and Zaidan, B. B., A review on multimedia communications cryptography. Res. J. Inf. Technol. 3:146–152, 2011.
Zaidan, B. B., Zaidan, A. A., Al-Frajatand, A. K., and Jalab, H. A., On the differences between hiding information and cryptography techniques: An overview. J. Appl. Sci. 10(15):1650–1655, 2010.
Al-Bakri, S. H., Mat Kiah, M. L., Zaidan, A. A., Zaidan, B. B., and Alam, G. M., Securing peer-to-peer mobile communications using public key cryptography: New security strategy. Int. J. Phys. Sci. 6(4):930–938, 2011.
Abomhara, M., Khalifa, O. O., Zaidan, A. A., Zaidan, B. B., Zakaria, O., and Gani, A., An experiment of scalable video security solution using H. 264/AVC and advanced encryption standard (AES): Selective cryptography. Int. J. Phys. Sci. 6(16):4053–4063, 2011.
Zaidan, A. A., Othman, F., Zaidan, B. B., Raji, R. Z., Hasan, A. K., and Naji, A. W., Securing Cover-File Without Limitation of Hidden Data Size Using Computation Between Cryptography and Steganography. Proceedings of the World Congress on Engineering I, 2009.
Kiah, M. L. M., Nabi, M. S., Zaidan, B. B., and Zaidan, A. A., An Enhanced Security Solution for Electronic Medical Records Based on AES Hybrid Technique with SOAP/XML and SHA-1. J. Med. Syst. 37(5):9971, 2013.
Yang, X., Li, Z., Wang, A., and Wen, S., Design research of the des against power analysis attacks based on FPGA. Microprocess. Microsyst. 35(1):18–22, 2011.
Yun-Peng, Z., Digital image encryption algorithm based on chaos and improved DES. pp. 480–485, 2009.
Singh, G., A Study of Encryption Algorithms (RSA, DES, 3DES and AES) for Information Security. Int. J. Comput. Appl. 67(19):975–8887, 2013.
Patil, P., Narayankar, P., Narayan, D. G., and Meena, S. M., A Comprehensive Evaluation of Cryptographic Algorithms: DES, 3DES, AES, RSA and Blowfish. Procedia Comput. Sci. 78:617–624, 2016.
Zaidan, A. A., Majeed, A., and Zaidan, B. B., High Securing Cover-File of Hidden Data Using Statistical Technique and AES Encryption Algorithm. World Acad. Sci. Eng. Technol. 54:463–474, 2009.
Kundi, D. S., Aziz, A., and Ikram, N., A high performance ST-Box based unified AES encryption/decryption architecture on FPGA. Microprocess. Microsyst. 41:37–46, 2016.
Mathur, N., and Bansode, R., AES Based Text Encryption Using 12 Rounds with Dynamic Key Selection. Procedia Comput. Sci. 79:1036–1043, 2016.
Von Solms, R., and Van Niekerk, J., From information security to cyber security. Comput. Secur. 38:97–102, 2013.
Nassar, S. S. et al., Secure Wireless Image Communication Using LSB Steganography and Chaotic Baker Ciphering. Wirel. Pers. Commun. 91(3):1023–1049, 2016.
Skillen, A., and Mannan, M., Mobiflage: Deniable storage encryption for mobile devices. IEEE Trans. Dependable Secur. Comput. 11(3):224–237, 2014.
Rahman, F., Bhuiyan, M. Z. A., and Ahamed, S. I., A privacy preserving framework for RFID based healthcare systems. Futur. Gener. Comput. Syst. 72:339–352, 2017.
Joseph, S. A., and Joby, N. J., Analyzing RFID Tags in a Distributed Environment. Procedia Technol. 24:1483–1490, 2016.
Shen, H., Shen, J., Khan, M. K., and Lee, J.-H., Efficient RFID Authentication Using Elliptic Curve Cryptography for the Internet of Things. Wirel. Pers. Commun. 96(4):5253–5266, 2017.
Williamson, A., Tsay, L.-S., Kateeb, I. A., and Burton, L., Solutions for RFID Smart Tagged Card Security Vulnerabilities. AASRI Procedia 4:282–287, 2013.
Mohsin, A. H. et al., Blockchain authentication of network applications: Taxonomy, classification, capabilities, open challenges, motivations, recommendations and future directions. Comput. Stand. Interfaces, 2018.
Fernández-Caramés, T. M., and Member, S., A review on the use of blockchain for the internet of things. 3536(c): 1–23, 2018.
Li, X., Jiang, P., Chen, T., Luo, X., and Wen, Q., A survey on the security of blockchain systems. Futur. Gener. Comput. Syst, 2017.
Kshetri, N., Blockchain’s roles in strengthening cybersecurity and protecting privacy. Telecommun. Policy 41(10):1027–1038, 2017.
Tian, F., An Agri-food supply chain traceability system for China based on RFID & blockchain Technology. 2016 13th Int. Conf. Serv. Syst. Serv. Manag., pp. 1–6, 2016.
B. Cresitello-Dittmar, “Application of the Blockchain For Authentication and Verification of Identity,” 2016.
Zaidan, B. B., Zaidan, A. A., and Othman, F., Enhancement of the amount of hidden data and the quality of image. Kuala Lumpur: Fac. Comput. Sci. Inf. Technol. Univ. Malaya, 2008.
Zaidan, A. A., and Zaidan, B. B., Novel approach for high secure data hidden in MPEG video using public key infrastructure. Int. J. Comput. Netw. Secur. 1(1):1553–1985, 2009.
Naji, A. W., Zaidan, A. A., and Zaidan, B. B., Challenges of hidden data in the unused area two within executable files. J. Comput. Sci. 5(11):890–897, 2009.
Yahya, A.-N., Zaidan, A. A., Zaidan, B. B., Jalab, H. A., and Alanazi, H. O., A new system for hidden data within header space for EXE-File using object oriented technique. In: 2010 3rd International Conference on Computer Science and Information Technology, vol. 7, pp. 9–13, 2010.
Hmood, A. K., Kasirun, Z. M., Jalab, H. A., Alam, G. M., Zaidan, A. A., and Zaidan, B. B., On the accuracy of hiding information metrics: Counterfeit protection for education and important certificates. Int. J. Phys. Sci. 5(7):1054–1062, 2010.
Jalab, H. A., Zaidan, A. A., and Zaidan, B. B., New design for information hiding with in steganography using Distortion Techniques. ijetch.org , vol. 2, no. 1, 2010.
Majeed, A., Kiah, L. M., Madhloom, H. T., Zaidan, B. B., and Zaidan, A. A., Novel approach for high secure and high rate data hidden in the image using image texture analysis. eprints.um.edu.my, vol. 1, no. 2, pp. 63–69, 2009.
Zaidan, B. B., Zaidan, A. A., Taqa, A. Y., and Othman, F., An empirical study for impact of the increment the size of hidden data on the image texture. ICFCC09, 2009.
Zaidan, A. A., Zaidan, B. B., Abdulrazzaq, M. M., Raji, R. Z., and Mohammed, S. M., Implementation stage for high securing cover-file of hidden data using computation between cryptography and steganography. Int. Assoc. Comput. Sci. Inf. Technol. (IACSIT), Index. by Nielsen, Thomson ISI (ISTP), IACSIT Database, Br. Libr. EI Compend., vol. 20, 2009.
Zaidan, B. B., and Zaidan, A. A., Comparative study on the evaluation and benchmarking information hiding approaches based multi-measurement analysis using TOPSIS method with different normalisation, separation and context techniques. Measurement 117:277–294, 2018.
Zaidan, A. A., Naji, A. W., Hameed, S. A., Othman, F., and Zaidan, B. B., Approved undetectable-antivirus steganography for multimedia information in PE-file. In International Conference on IACSIT Spring Conference (IACSIT-SC09), Advanced Management Science (AMS), Listed in IEEE Xplore and be indexed by both EI (Compendex) and ISI Thomson (ISTP), Session, vol. 9, pp. 425–429, 2009.
Ahmed, M. A., Mat Kiah, M. L., Zaidan, B. B., and Zaidan, A. A., A Novel Embedding Method to Increase Capacity and Robustness of Low-bit Encoding Audio Steganography Technique Using Noise Gate Software Logic Algorithm. J. Appl. Sci. 10(1):59–64, 2010.
Al-Frajat, A. K., Jalab, H. A., Kasirun, Z. M., Zaidan, A. A., and Zaidan, B. B., Hiding Data in Video File: An Overview. J. Appl. Sci. 10(15):1644–1649, 2010.
Naji, A. W., Zaidan, A. A., Zaidan, B. B., and Muhamadi, I. A. S., New approach of hidden data in the portable executable file without change the size of carrier file using distortion techniques. Proceeding World Acad. Sci. Eng. Technol. 56:493–497, 2009.
Eltahir, M. E., Kiah, L. M., Zaidan, B. B., and Zaidan, A. A., High rate video streaming steganography. In 2009 International Conference on Information Management and Engineering, pp. 550–553, 2009.
Zaidan, B. B., Zaidan, A. A., Karim, H. A., and Ahmad, N. N., A new digital watermarking evaluation and benchmarking methodology using an external group of evaluators and multi-criteria analysis based on ‘large-scale data. Softw. Pract. Exp. 47(10):1365–1392, 2017.
Zaidan, B. B., and Zaidan, A. A., Software and Hardware FPGA-Based Digital Watermarking and Steganography Approaches: Toward New Methodology for Evaluation and Benchmarking Using Multi-Criteria Decision-Making Techniques. J. Circuits, Syst. Comput. 26(07):1750116, 2017.
Othman, F., Maktom, L., Taqa, A. Y., Zaidan, B. B., and Zaidan, A. A., An extensive empirical study for the impact of increasing data hidden on the images texture. In: 2009 International Conference on Future Computer and Communication, pp. 477–481, 2009.
Zaidan, A. A., Zaidan, B. B., Hamdan Alanazi, O., Gani, A., Zakaria, O., and Alam, G. M., Novel approach for high (secure and rate) data hidden within triplex space for executable file. Sci. Res. Essays 5(15), 1965.
Zaidan, B., Zaidan, A., Othman, F., Raji, R. Z., Mohammed, S., and Abdulrazzaq, M., Quality of Image vs. Quantity of Data Hidden in the Image. IPCV 6:343–350, 2009.
Naji, A. W., Gunawan, T. S., Hameed, S. A., Zaidan, B. B., and Zaidan, A. A., Stego-analysis chain, session one’ investigations on steganography weakness VS stego-analysis system for multimedia file. In 2009 International Association of Computer Science and Information Technology - Spring Conference, IACSIT-SC 2009, pp. 405–409, 2009.
Zaidan, B., Zaidan, A., Taqa, A., F. O.-I. J. Of, and U., Stego-image vs stego-analysis system. Citeseer 1(5):1793–8163, 2009.
Zaidan, A. A., Zaidan, B. B., Al-Frajat, A. K., and Jalab, H. A., Investigate the capability of applying hidden data in text file: An overview. J. Appl. Sci. 10(17):1916–1922, 2010.
Zaidan, B. B., Zaidan, A. A., Abdul Karim, H., and Ahmad, N. N., A New Approach based on Multi-Dimensional Evaluation and Benchmarking for Data Hiding Techniques. Int. J. Inf. Technol. Decis. Mak.:1–42, 2017.
Hmood, A. K., Zaidan, B. B., Zaidan, A. A., and Jalab, H. A., An Overview on Hiding Information Technique in Images. J. Appl. Sci. 10(18):2094–2100, 2010.
Khalifa, O. O., Naji, A. W., Zaidan, A. A., Zaidan, B. B., and Hameed, S. A., Novel approach of hidden data in the (unused area 2 within EXE file) using computation between cryptography and steganography. Int. J. Comput. Sci. Netw. Secur. 9(5):294–300, 2010.
Naji, A. W., Zaidan, A. A., Zaidan, B. B., Hameed, S. A., and Khalifa, O. O., Novel Approach for Secure Cover File of Hidden Data in the Unused Area within EXE File Using Computation between Cryptography and Steganography. J. Comput. Sci. 9(5):294–300, 2009.
Zaidan, A. A., Zaidan, B., and Othman, F., New Technique of Hidden Data in PE-File with in Unused Area One. Int. J. Comput. Electr. Eng. 1(5):642–650, 2009.
Hamdan, A., Jalab, H. A., Zaidan, A. A., and Zaidan, B. B., New frame work of hidden data with in non multimedia file. Int. J. Comput. Netw. Secur. 2(1):46–54, 2010.
Hussain, M., Abdul Wahab, A. W., Batool, I., and Arif, M., Secure password transmission for web applications over internet using cryptography and image steganography. Int. J. Secur. its Appl. 9(2):179–188, 2015.
Naji, A. W., Hameed, S. A., Islam, M. R., Zaidan, B. B., Gunawan, T. S., and Zaidan, A. A., Stego-analysis chain, session two’ novel approach of stego-analysis system for image file. In 2009 International Association of Computer Science and Information Technology-Spring Conference, pp. 410–413, 2009.
Mohsin, A. H. et al., Real-Time Medical Systems Based on Human Biometric Steganography: a Systematic Review. J. Med. Syst. 42(12):245, 2018.
Ali, A. H., George, L. E., Zaidan, A. A., and Mokhtar, M. R., High capacity, transparent and secure audio steganography model based on fractal coding and chaotic map in temporal domain. Multimed. Tools Appl., 2018.
Taqa, A., Zaidan, A. A., and Zaidan, B. B., New Framework for High Secure Data Hidden in the MPEG Using AES Encryption Algorithm. Citeseer 1(5):8163, 2009.
Hmood, A. K., Jalab, H. A., Kasirun, Z. M., Zaidan, B. B., and Zaidan, A. A., On the capacity and security of steganography approaches: An overview. J. Appl. Sci. 10(16):1825–1833, 2010.
Al-khateeb, W. F., and Hameed, S. A., New Approach of Hidden Data in the portable Executable File without Change the Size of Carrier File Using Statistical Technique. Int. J. Comput. Sci. Netw. Secur. 9(7):218–224, 2009.
Alanazi, H., Zaidan, A. A., Zaidan, B. B., Jalab, H. A., and Al-Ani, Z. K., New classification methods for hiding information into two parts: multimedia files and non multimedia files. arXiv Prepr. arXiv1003.4084, 2010.
Zaidan, A. A., and Zaidan, B., A New System for Hiding Data within (Unused Area Two + Image Page) of Portable Executable File using Statistical Technique and Advance Encryption Standared.
Elshoura, S. M., and Megherbi, D. B., A secure high capacity full-gray-scale-level multi-image information hiding and secret image authentication scheme via Tchebichef moments. Signal Process. Image Commun. 28(5):531–552, 2013.
Jalab, H. A., Zaidan, A. A., and Zaidan, B. B., Frame Selected Approach for Hiding Data within MPEG Video Using Bit Plane Complexity Segmentation. J. Comput. 1(1):108–113, 2009.
Elnajjar, M., Zaidan, A. A., Zaidan, B. B., Sharif, M. E. M., and Alanazi, H., Optimization digital image watermarking technique for patent protection. arXiv Prepr. arXiv1002.4049, 2010.
Al-Ani, Z. K., Zaidan, A. A., Zaidan, B. B., and Alanazi, H. O., Overview: Main Fundamentals for Steganography. undefined, 2010.
Naji, A. W., New System for Secure Cover File of Hidden Data in the Image Page within Executable File Using Statistical Steganography Techniques. Int. J. Comput. Sci. Inf. Secur. 7(1):273–279, 2009.
Kiah, M. L. M., Zaidan, B. B., Zaidan, A. A., Ahmed, A. M., and Al-Bakri, S. H., A review of audio based steganography and digital watermarking. Int. J. Phys. Sci. 6(16):3837–3850, 2011.
Kanan, H. R., and Nazeri, B., A novel image steganography scheme with high embedding capacity and tunable visual image quality based on a genetic algorithm. Expert Syst. Appl. 41(14):6123–6130, 2014.
Fard, A. M., and Varasteh A. F., A new genetic algorithm approach for secure JPEG steganography. 2006 IEEE Int. Conf. Eng. Intell. Syst., pp. 1–6, 2006.
Tseng, L. Y., Chan, Y. K., Ho, Y. A., and Chu, Y. P., “Image hiding with an improved genetic algorithm and an optimal pixel adjustment process,” Proc. - 8th Int. Conf. Intell. Syst. Des. Appl. ISDA 2008, vol. 3, pp. 320–325, 2008.
Bhattacharya, T., Bhowmik, S., and Chaudhuri, S. R. B., “A steganographic approach by using Session based Stego-Key, genetic algorithm and variable bit replacement technique,” Proc. 2008 Int. Conf. Comput. Electr. Eng. ICCEE 2008, pp. 51–55, 2008.
Wang, S., Yang, B., and Niu, X., A secure steganography method based on genetic algorithm. vol. 1, no. 1, pp. 28–35, 2010.
Ghasemi, E. and Shanbehzadeh, J., An imperceptible steganographic method based on Genetic Algorithm. 2010 5th Int. Symp. Telecommun., pp. 836–839, 2010.
Eberhart, R. C. and Shi, Y., Particle swarm optimization: developments, applications and resources. Proc. 2001 Congr. Evol. Comput. (IEEE Cat. No.01TH8546), vol. 1, pp. 81–86, 2001.
Sameer, F. O., Abu Bakar, M. R., Zaidan, A. A., and Zaidan, B. B., A new algorithm of modified binary particle swarm optimization based on the Gustafson-Kessel for credit risk assessment. Neural Comput. Appl., 2017.
Zaidan, A. A., Atiya B., Abu Bakar M. R., and Zaidan B. B., A new hybrid algorithm of simulated annealing and simplex downhill for solving multiple-objective aggregate production planning on fuzzy environment. Neural Comput. Appl., 2017.
Tariq, I. et al., MOGSABAT: a metaheuristic hybrid algorithm for solving multi-objective optimisation problems. Neural Comput. & Applic. 30:1–15, 2018.
Lu, Y., Xie, S. J., Yoon, S., Wang, Z., and Park, D. S., An available database for the research of finger vein recognition. Proc. 2013 6th Int. Congr. Image Signal Process. CISP 2013 1:410–415, 2013.
Lu, Y., Xie, S. J., Yoon, S., Yang, J., and Park, D. S., Robust finger vein ROI localization based on flexible segmentation. Sensors (Switzerland) 13(11):14339–14366, 2013.
Liu, F., Yang, G., Yin, Y., and Wang, S., Singular value decomposition based minutiae matching method for finger vein recognition. Neurocomputing 145:75–89, 2014.
Park, K. R., Lee, E. C., and Lee, H. C., Finger Vein Recognition Using Minutia-Based Alignment and Local Binary Pattern-Based Feature Extraction. Int. J. Imaging Syst. Technol. 19(3):179–186, 2009.
Naoto, M., Nagasaka, A., and Miyatake, T., Extraction of Finger-Vein Patterns Using Maximum Curvature Points in Image Profile. Conf. Mach. Vis. Appl. Tsukuba Sci. City, Japan 34(4):444–448, 2005.
Dalal, N. and Triggs B., Histograms of oriented gradients for human detection. Proc. - 2005 IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognition, CVPR 2005, vol. I, pp. 886–893, 2005.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Ethical approval
All procedures performed in studies with human participation were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all participants included in the study.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Systems-Level Quality Improvement
Rights and permissions
About this article

Cite this article
Mohsin, A.H., Zaidan, A.A., Zaidan, B.B. et al. Based Medical Systems for Patient’s Authentication: Towards a New Verification Secure Framework Using CIA Standard. J Med Syst 43, 192 (2019). https://doi.org/10.1007/s10916-019-1264-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10916-019-1264-y