
Abstract
We propose an algorithm for solving the surrogate dual of a mixed integer program. The algorithm uses a trust region method based on a piecewise affine model of the dual surrogate value function. A new and much more flexible way of updating bounds on the surrogate dual’s value is proposed, in which numerical experiments prove to be advantageous. A proof of convergence is given and numerical tests show that the method performance is better than a state of the art subgradient solver. Incorporation of the surrogate dual value as a cut added to the integer program is shown to greatly reduce solution times of a standard commercial solver on a specific class of problems.

Similar content being viewed by others
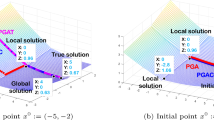
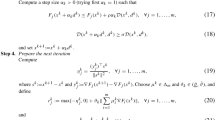
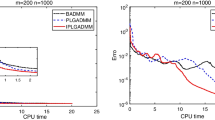
References
Greenberg, H.J., Pierskalla, W.P.: Surrogate mathematical programming. Oper. Res. 18, 924–939 (1970)
Karwan, M., Rardin, R.: Surrogate dual multiplier search procedures in integer programming. Oper. Res. 32, 52–69 (1984)
Karwan, M., Rardin, R.: Some relationships between Lagrangian and surrogate duality in integer programming. Math. Progr. 17, 320–334 (1979)
Kim, S.-L., Kim, S.: Exact algorithm for the surrogate dual of an integer programming problem: subgradient method approach. J. Optim. Theory Appl. 96, 363–375 (1998)
Sarin, S., Karwan, M., Rardin, R.: Surrogate duality in a branch-and-bound procedure for integer programming. Euro. J. Oper. Res. 33, 326–333 (1988)
Li, D., Sun, X.: Nonlinear Integer Programming. International Series in Operations Research & Management, Springer (2006)
Noll, D.: Bundle method for non-convex minimization with inexact subgradients and function values. Comput. Anal. Math. 50, 555–592 (2013)
Linderoth, J., Wright, S.: Decomposition algorithms for stochastic programming on a computational grid. Comput. Opt. Appl. 24, 207–250 (2003)
Hiriart-Urruty, J.-B., Lemaréchal, C.: Convex Analysis and Minimization Algorithms II: Advanced Theory and Bundle Methods. Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences] 306. Springer-Verlag, Berlin (1993)
Boland N, Eberhard A, Tsoukalas A (2014) A trust region method for the solution of the surrogate dual in integer programming. Optim. Online. http://www.optimization-online.org/DB_HTML/2014/02/4249.html
Frangioni, A.: Generalized bundle methods. SIAM J. Optim. 13, 117–156 (2002)
Han, B., Leblet, J., Simon, G.: Hard multidimensional multiple choice knapsack problems: an empirical study. Comput. Oper. Res. 37, 172–181 (2010)
Rockafellar, R.T., Wets, R.J.-B.: Variational Analysis. A series of comprehensive studies in mathematics. Springer, Berlin (1998)
Acknowledgments
We thank two anonymous referees, whose constructive comments improved the paper. This research was supported by the ARC Discovery Grant No. DP0987445.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
In the following, we will denote the support functions to a closed convex set \(A\) by \(\delta ^{*}\left( A\right) \left( u\right) :=\sup \left\{ au : a\in A\right\} .\) We use epi-limits and Attouch’s theorem for which the reader may consult [14] for details.
Proof
(of Lemma 4.1) Suppose \(V_{\alpha }(u+\gamma d) < V_{\alpha }(u) <+\infty \), for some sufficiently small \(\gamma >0\) and \(x\in \arg \max \left\{ u\left( Ax^{\prime }-b\right) : x^{\prime }\in X\left( \alpha \right) \right\} \). Then, \(x\in X\left( \alpha \right) \) and so
implying \(d\left( Ax-b\right) <0\) holds for all \(x\in \arg \max \left\{ u\left( Ax^{\prime }-b\right) : x^{\prime }\in X\left( \alpha \right) \right\} \). Consequently, this is also true for all \(s\) defined as in (5).
Conversely, for all \(x_{\gamma }\in M\left( \gamma \right) :=\arg \max \left\{ \left( u+\gamma d\right) \left( Ax^{\prime }-b\right) : x^{\prime }\in X\left( \alpha \right) \right\} ,\)
Note that since \(M(0) \) is bounded and \(g_{\gamma }( x) := (u+\gamma d) (Ax-b) +\delta _{X(\alpha ) }(x) \) is a sequence of level set bounded, proper convex functions, epi-converging to \(g(x) := u( Ax-b) +\delta _{X( \alpha ) }(x) \), we may invoke [14], Exercise 7.32 (c) and Theorem 7.33 to deduce \(\limsup _{\gamma \downarrow 0}M(\gamma ) \subseteq M( 0)\). When we assume \(d(Ax-b) <0\) for all \(x\in M(0) \), we have \(d( Ax_{\gamma }-b) <0\) for \(\gamma \) sufficiently small. If we assume otherwise, (i.e., assuming there exists \(x_{\gamma _{m}}\in M(\gamma _{m}) \) for \(\gamma _{m}\downarrow 0\) with \(d(Ax_{\gamma _{m}}-b) \ge 0\)), the following contradiction follows. As \(V_{\alpha }(\cdot ) \) is a finite, convex function, it is locally Lipschitz and so \(\partial V_{\alpha }(\cdot ) \) is locally, uniformly bounded, implying local boundedness of \(s_{\gamma }:= \,( Ax_{\gamma }-b)\). This in turn implies local boundedness of \(\{ x_{\gamma _{m}}\} \), and on taking any convergent subsequence \(x_{\gamma _{m_{k}}}\rightarrow x\in M(0) \), we find that the assumption \(d(Ax_{\gamma _{m_{k}} }-b) \ge 0\) implies the contradiction \(d(Ax-b) \ge 0\) for some \(x\in M(0) \). Thus, \(d( Ax_{\gamma }-b) <0\) and \( V_{ \alpha }(u+\gamma d ) \le V_{\alpha } (u) +\gamma d(Ax_{\gamma }-b) < V_{\alpha }(u) \), for \(\gamma \) small. If there exists a sequence \(x_{\gamma _{m}}\in M(\gamma _{m}) \) such that \(x_{\gamma _{m} }\rightarrow x\in M( 0) \) with \(d(Ax-b) <0\), then the same argument implies \(d\) is a descent direction. Indeed, the presumption that there exists a further subsequence such that \(d( Ax_{\gamma _{m_{k}}}-b) \ge 0\) for all \(k\), implies the contradiction \(d(Ax-b) \ge 0\). Thus, \(\gamma _{m}d(Ax_{\gamma _{m} }-b) <0\), for \(m\) large, implying \(V_{ \alpha }( u+\gamma _{m}d ) < V_{\alpha }(u) \).
Finally, when \(x_{\gamma }\in M( \gamma ) \) we have \(s_{\gamma }:= ( Ax_{\gamma }-b) \in \partial V_{\alpha } ( u+\gamma d)\), and as \(V_{\alpha }(\cdot ) \) is a finite, convex function, it is also semi-smooth. Consequently, any convergent subsequence \(s_{\gamma _{m}}:= ( Ax_{\gamma _{m}}-b) \rightarrow s= ( Ax-b) \in \partial _{d} V_{\alpha } (u)\), for some \(x\in M(0) \). Assuming that \(d( Ax-b) <0\) for \(s= (Ax-b) \in \partial _{d} V_{\alpha } (u) \), we may argue as above that for \(\gamma \) sufficiently small that \(d(Ax_{\gamma }-b) <0\). Hence \(V_{\alpha }(u+\gamma d) < V_{\alpha }(u) \). \(\square \)
Proof
(of Lemma 5.1) We assume we have a sequence of trust regions of diameter \(\Delta _{k}\downarrow 0\), and an associated sequence of \(u_{k+1}\), generated in the evaluation of \(V_{\alpha _{k}} (u_{k+1} ) \) when calculating \(\rho _{k+1}\). In Step 3 of Algorithm SDTR, we add some \(s_{k+1}\in \partial V_{\alpha _{k}} \left( u_{k+1}\right) \) by choosing \(s_{k+1}=Az_{k+1}-b\).
By assumption, \(\left\| u_{k+1}-u_{k}\right\| _{\infty }\downarrow 0\). As \(u_{k}\rightarrow u\), we have \(\left\| u_{k+1}-u\right\| _{\infty }\rightarrow 0\). Also by assumption, there exists a subsequence of \(\left\{ u_{k}\right\} _{k=0}^{\infty }\), denoted by \(\left\{ u_{p}\right\} _{p=0}^{\infty }\), with \(u_{p} \rightarrow _dd\) such that \(v^{\prime }(P(\alpha ,\cdot )) ( u,d) <0\). Denote \(t_{p}:=\left\| u_{k_{p}+1}-u_{k_{p}}\right\| _{\infty }\). Then \(u_{k_{p}+1}-u_{k_{p}}=t_{p}d_{p}\). Note that in Step 3(b), just before returning to do Step 3 again, we add \(z_{k_{p}+1}\in \arg \max \left\{ u_{k_{p}+1}\left( Ax-b\right) : x\in X\left( \alpha _{k_{p}}\right) \right\} \) found while calculating \(\rho _{{k_p}+1}\). This implies \(\left( Az_{k_{p}+1}-b\right) \) must satisfy the following:
Take \(y_{p}\in X\left( \alpha _{k_{p}}\right) \) satisfying \(\beta _{k_{p} +1}=u_{k_{p}+1}\left( Ay_{p}-b\right) \) in the problem (3) from which we obtain \(\left( u_{k_{p}+1},\beta _{k_{p}+1}\right) \). Due to (10) and \(y_{p}\in X_{k_{p}}( \alpha _{k_{p}})\), we have
When (7) holds, we have \(0> V_{\alpha _{k_{p}}} ( u_{k_{p}+1} ) - V_{\alpha _{k_{p}}} ( u_{k_{p}} )\ge \beta _{k_{p}+1}- V_{\alpha _{k_{p}}} ( u_{k_{p} } )\) and so \(\rho _{k_{p}+1}\le 1\) . Note that (7) holds in either of the cases: \(\beta _{k+1}<0\) or \(\beta _{k+1}< \underline{V}_k ( u_{k}) \).
Now we wish to invoke Attouch’s theorem, ([14], Theorem 12.35), which states that an epi-convergent family of convex functions has their subdifferentials graphically converging. First we note that as \(\alpha _{k_{p}}\downarrow \alpha \), and \(X( \alpha _{k_{p}}) \) are eventually bounded, the finite sequence of convex functions \(V_{\alpha _{k_{p}}} (\cdot )\) is monotonically non-increasing, pointwise convergent and consequently also epi-converges to \(V_{\alpha } ( \cdot ) \). Thus, \(\partial V_{\alpha _{k_{p}}} ( \cdot )\) graphically converges to \(\partial V_{\alpha } (\cdot ) \).
We need to estimate the magnitude of
As \(z_{k_{p}}\) was added to the model in Step 3(b) at iteration \(k_{p}-1\), and by assumption is not dropped, we have \(z_{k_{p}}\in X_{k_{p}}\left( \alpha _{k_{p}}\right) \) when solving (3) at iteration \(k_{p}\). Thus, at the iteration \(k_p\), a subgradient \(s_{k_{p}}:=Az_{k_{p}}-b\) satisfies \(V_{\alpha _{k_{p}-1}} \left( u_{k_{p}}\right) =u_{k_{p}}\left( Az_{k_{p} }-b\right) \). As \(z_{k_{p}}\in X_{k_{p}}\left( \alpha _{k_{p}}\right) \), it follows that \(\beta _{k_{p}+1}\ge u_{k_{p}+1}s_{k_{p}}=s_{k_{p}}\left( u_{k_{p} }+t_{p}d_{l_{p}}\right) \). Since \(s_{k_{p}}\in \partial V_{\alpha _{k_{p}-1}} \left( u_{k_{p}}\right) \), taking a further subsequence, on re-numbering, we may assume we have such a sequence of subgradients with \(s_{k_{p}}\rightarrow s = (Ax-b) \in \partial V_{\alpha } (\bar{u}) \), for some \(x\in X(\alpha ) \). (Note that local Lipshitzness of \(u\mapsto V_{\alpha } (u) \) ensures \(\partial V_{\alpha }( \bar{u}) \) is bounded. Then by the graphical convergence of subdifferentials, the sequence \(\{ s_{p}\} \) is locally bounded, see [14] Exercise 5.34(b)). As (7) holds for all \(p\), we have
using (11) and monotonicity. The last equality holds as \(s_{k_{p}}\in \partial V_{\alpha _{k_{p}-1}} \left( u_{k_{p}}\right) \) implies \(V_{\alpha _{k_{p}-1}} ( u_{k_{p}} ) =s_{k_{p}}u_{k_{p}}\). Due to Attouch’s theorem, \(s_{k_{p}}\rightarrow s\in \partial V_{\alpha } \left( u\right) \), and so \(s_{k_{p}}d_{p}\rightarrow sd\le V^{\prime }_{\alpha } \left( u,d\right) \).
As graphical convergence of sets implies the epi-convergence of the associated support functions, (see [14], Corollary 11.36), we have for all \(w_p \rightarrow u\),
Uniform–local Lipschitzness of \(d^{\prime }\mapsto \delta ^{*} ( \partial V_{\alpha _{k_{p}}} ( w_{p}) ) ( d^{\prime }) \) follows from the locally uniform boundedness of \(\partial V_{\alpha _{k_{p}}} \left( w_{p}\right) \). Hence
Consequently, for \(p\) large we have \(V^{\prime }_{\alpha _{k_{p}}} \left( w_{p},d\right) <0\), for any \(w_{p}\rightarrow u\).
By the mean value theorem for convex functions there exists \(\gamma _{p}\in ]0,1[\) such that \(V^{\prime }_{\alpha _{k_{p}}} \left( u_{k_{p}}+t_{p}\gamma _{p}d,d\right) \ge v_{p}d_{p}=\frac{V_{\alpha _{k_{p}}} \left( u_{k_{p}}+t_{p}d\right) -V_{\alpha _{k_{p}}} \left( u_{k_{p}}\right) }{t_{p}}\), for some element \(v_{p}\in \partial V_{\alpha _{k_{p}}} \left( u_{k_{p}}+t_{p}\gamma _{p}d_{p}\right) \). Hence, for \(p\) large, \(V^{\prime }_{\alpha _{k_{p}}} \left( u_{k_{p}}+t_{p}\gamma _{p}d,d\right) <0\). Using (12), and observing both quantities in the quotient for \(\rho _{k_{p}+1}\) are negative, gives, using the Lipschitzness of \(V_{\alpha _{k_{p}}} \left( \cdot \right) \), a lower bound on \(\limsup _{p\rightarrow \infty }\rho _{k_{p}+1} \) of
Thus \(\limsup _{k\rightarrow \infty }\rho _{k+1}\ge V^{\prime }_{\alpha } \left( u,d\right) \times \left( sd\right) ^{-1}\ge 1\). \(\square \)
Proof
(of Lemma 5.2) The argument given above, in the proof of Lemma 5.1, may be applied with \(\alpha _{k}\) fixed. Take a subsequence \( \{d_{l_p} \}_{p=0}^\infty \) of \(\{ d_{l} := \frac{u_{k,l} - u_k}{\Vert u_{k,l} - u_k \Vert }\}_{p=0}^\infty \) converging to \(d\). With the subsequence \(u_{k,l_{p}}\rightarrow u_{k}\), we may associate a subsequence of diameters \(\Delta _{k,l_{p}}\downarrow 0\). Place \(u_{k,l_{p}}=u_{k}+t_{p}d_{l_{p}}\), and note that we continue to reject an update of \(u_{k}\). As \(u\mapsto V_{\alpha _{k}} \left( u\right) \) is convex, it is also semi-smooth, and so we may assume \(s_{l_{p}}\rightarrow s \in \partial _{d} V_{\alpha _{k}} \left( u_{k}\right) :=\left\{ s^{\prime }\in \partial V_{\alpha _{k}} \left( u_{k}\right) : s^{\prime }\cdot d=V^{\prime }_{\alpha _{k}} \left( u_{k} ,d \right) \right\} \). As \(z_{k,l_{p}}\) is added to \(X_{k,l_{p}}\left( \alpha _{k}\right) \) and retained, we have \(z_{k,l_{p-1}}\in X_{k,l_{p-1}}\left( \alpha _{k}\right) \) when solving (3) at iteration \((k,l_{p})\) (and \(\alpha _{k}\) is never updated).
Consequently, \(\beta _{k,l_{p}}\ge u_{k,l_{p}}\cdot s_{l_{p}-1}=s_{l_{p}-1}\cdot \left( u_{k}+t_{p}d_{p}\right) \). Using (11) replacing \(\alpha _{k_{p}}=\alpha _{k}\), and applying (7) to each problem in this sequence yields
as \(s_{l_{p}-1}\in \partial V_{\alpha _{k}} \left( u_{k}+t_{p-1}d_{p-1}\right) \). First suppose that there exists a subsequence so that \(\left\{ \frac{t_{p_{m}-1}}{t_{p_{m}}}\right\} \rightarrow \lambda \ge 0\). By semi-smoothness, we have the limiting values \(s_{l_{p}-1}\cdot d_{p}\rightarrow s\cdot d=V^{\prime }_{\alpha _{k}} \left( u_{k},d\right) \) and \(s_{p-1}\cdot d_{p-1}\rightarrow V^{\prime }_{\alpha _{k}} \left( u_{k},d\right) \), so (14) converges to the weighted sum \( \left[ 1-\lambda \right] V^{\prime }_{\alpha _{k}} \left( u_{k},d\right) +\lambda V^{\prime }_{\alpha _{k}} \left( u_{k},d\right) =V^{\prime }_{\alpha _{k}} \left( u_{k},d\right) \). Hence, using (12) and noting both quantities in the quotient are negative, we obtain
In the alternative case, \(\left\{ \frac{t_{p-1}}{t_{p}}\right\} \) is unbounded (and \(\Delta _{k,l_{p}+1}=\gamma \Delta _{k},_{l_{p}}\) using a \(\gamma \in ]0,1[\)). Then \(u_{k}+t_{p-1}d_{_{p-1}}\in \mathrm{int }B_{k,l_{p}}\), placing us in Step 3(a), as described in Lemma 4.2, resulting in an update of \(u_{k}\), contrary to assumption. \(\square \)
Proof
(of Corollary 5.1) We have \(\liminf _{k\rightarrow \infty }\rho _{k+1}\) given by
For part 1, apply Lemma 5.2 to \(\left\{ \rho _{k_{m}+1}\right\} _{m=0}^{\infty }\) to obtain \(\left\{ \rho _{k_{p}+1}\right\} _{p=0}^{\infty }\) with
For part 2, we use \(\rho _{k+1}\ge \xi \), and so
As \(u_{k}\rightarrow u\) \(\notin \arg \min \left\{ V_{\alpha } \left( w \right) : w\in S^{n}\right\} \), for \(k\) large, there exists a descent direction for \(V_{\alpha } \left( \cdot \right) \) at \(u_{k}\). As \(\underline{V}_{k}\left( u_{k}\right) = V_{\alpha } \left( u_{k} \right) \) and \( \underline{V}_{k}\left( \cdot \right) \) minorizes \(V_{\alpha } \left( \cdot \right) \), there must exist a greater descent in the same direction for \(\underline{V}_{k}\left( \cdot \right) \) at \(u_{k}\). As \(u_{k_{p}+1}\) solves (3), we have \(d_{k_{p}}:=\frac{u_{k_{p} +1}-u_{k_{p}}}{ \Vert u_{k_{p}+1}-u_{k_{p}} \Vert }\) in the direction of maximal descent of \(\underline{V}_{k_{p}}\left( \cdot \right) \) at \(u_{k_{p}}\), and so there exists \(\delta >0\) such that we have \( \underline{V}_{k_{p}+1}\left( u_{k_{p}}+t_{p}d_{p}\right) - \underline{V}_{k_{p}}\left( u_{k_{p}}\right) \le -\delta t_{p} \), for \(p\) sufficiently large. Using (16) and the subgradient inequality for \(V_{\alpha _{k_{p}}} \left( \cdot \right) \) at \(u_{k_{p}}\) gives (for \(p\) large)
Using (13), we have \(V^{\prime }_{\alpha } \left( u,d\right) =\limsup _{p} V^{\prime }_{\alpha _{k_{p}}}\left( u_{k_{p}},d_{p}\right) -\xi \delta <0.\) We may now apply Lemma 5.1 to get (15) again. \(\square \)
Proof
(of Proposition 5.1) In all cases, we have \(V_{\alpha _{k}} \left( u_{k}\right) \ge 0\). Suppose that \(\rho _{k,l}<\xi \) for all \(l\). Then, applying Lemma 5.4 recursively, we have indices \(l_{p}\) with
When \(u_{k}\notin S_{\alpha _{k}}\), we have some \(\varepsilon >0\) such that \(\left\| u_{k}-p_{\alpha _{k}}\left( u_{k}\right) \right\| _{\infty }\ge \varepsilon \) and \( V_{\alpha _{k}} \left( u_{k}\right) -v_{k}^{*}\ge \) \(\varepsilon \). By (8), \(\min \left( \frac{\Delta _{k,l_{p}}}{ \Vert u_{k}-p_{\alpha _{k}}\left( u_{k}\right) \Vert _{\infty }},1 \right) \left( V_{\alpha _{k}} \left( u_{k}\right) -v_{k}^{*}\right) \rightarrow _{p\rightarrow \infty }0\) implying \(\Delta _{k,l_{p}}\rightarrow 0\). Apply Corollary 5.1, part 1 to get a subsequence of \(\left\{ \rho _{k,l_{p}}\right\} _{p=0}^{\infty }\) that tends to \(1\). Thus, there exists a \(p\) with \(\rho _{k,l_{p}}\ge \xi >0\), a contradiction.
In the case that \(u_{k}\in S_{\alpha _{k}}\), there does not exist any descent for \( V_{\alpha _{k}} \left( \cdot \right) \) at \(u=u_{k}\). In particular, we have \(v_{k}^{*}= V_{\alpha _{k}} \left( u_{k}\right) \ge 0\). Consequently, (3) cannot generate a descent that passes the test \(\rho _{k}\ge \xi \). Using (17), we observe that
As we add a new subgradient each time when solving \(V_{\alpha _{k}} (u_{k,l}) \), to calculate \(\rho _{k,l}\), the model function \(u\mapsto \underline{V}_{k,l_{k}}(u) \) is monotonically increasing, and hence convergent to a finite, convex function. As the trust region size is monotonically non-increasing, we have \(\left\{ \underline{V}_{k,l_{k}}\left( u_{k,l_{k}}\right) \right\} _{k}\) monotonically non-decreasing. Consequently, using (18), we deduce that we have a subsequence converging to zero. So for the whole sequence, \(\underline{V}_{k,l_{k}}\left( u_{k,l_{k}}\right) \uparrow v_{k}^{*}\). When \(V_{\alpha _{k}} \left( u_{k}\right) =v_{k}^{*}>0\), (or equivalently \(v\left( SD\right) <\alpha _{k}\), the case \(v\left( SD\right) \ne \alpha _{k}\)), we find after a finite number of iterations that \(\beta _{k,l_{k}}= \underline{V}_{k,l_{k,p}}\left( u_{k,l_{k}}\right) >0\). Thus, we are in case 3(a), of Algorithm SDTR, after a finite number of iterations. Alternatively, \(V_{\alpha _{k}} \left( u_{k}\right) =v_{k}^{*}=0\), so \(\alpha _{k}=v\left( SD\right) \) and \(\underline{V}_{k,l_{k}}\left( u_{k,l_{k}}\right) \le 0\). This establishes part 2b of the proposition.
Suppose we have a pure IP and we add a new subgradient each time when solving \(V_{\alpha _{k}} \left( u_{k,l}\right) \) when calculating \(\rho _{k,l}\). As \(u\mapsto V_{\alpha _{k}} \left( u\right) \) is polyhedral, (\(X\left( \alpha _{k}\right) \) contains a finite set of points), we add all extremal subgradients after a finite number of iterations \(l\). As \(u_{k}\in S_{\alpha _{k}}\) we have \(0\in \partial V_{\alpha _{k}} \left( u_{k}\right) \), or equivalently, \(0 \in \mathrm{co }\left\{ u_{k}\left( Ax_{j}-b\right) :x_{j}\in X_{k,l}\right\} \). But \(\underline{V}_{k,l}\left( u\right) =\max \left\{ u\left( Ax_{j}-b\right) : x_{j}\in X_{k,l}\right\} \), so we also have \(0\in \partial \underline{V}_{k,l} \left( u_{k}\right) =\mathrm{co }\left\{ u_{k}\left( Ax_{j}-b\right) : x_{j}\in X_{k,l}\right\} ,\) showing that \(u_{k}\) is a local (and hence global) minimum of \(u\mapsto \underline{V}_{k,l}\left( u\right) \). Then we have the inequalities \(0\le \underline{V}_{k,l}\left( u_{k}\right) =u_{k}\left( Ax_{k}-b\right) \le \min _{u\in S^{n}\cap B} \underline{V}_{k,l}\left( u\right) =\beta _{k,l},\) using the inequality \(u_{k}\left( Ax_{k}-b\right) = V_{\alpha _{k}} \left( u_{k}\right) \ge 0\). Hence \( \underline{V}_{k,l}\left( u_{k}\right) =0\) finitely. \(\square \)
Proof
(of Theorem 5.1) Whenever \([\overline{\alpha },\underline{\alpha }]\) is updated, we decrease the length of this interval of uncertainty by at least a constant factor. Thus, finite termination is assured unless we have an infinite cycle in the trust region loop, with fixed interval \([\overline{\alpha },\underline{\alpha }]\). Proposition 5.1 indicates that this can only occur in two ways. Via a sequence of decreasing \(\left\{ \alpha _{k}\right\} \), and a sequence of acceptable descents (i.e. \(\rho _{k,l}\ge \xi )\) which does not terminate, or that for some \(k\) we have \(\alpha _{k}=v\left( SD\right) \) and \( \underline{V}_{k,l_{k}}\left( u_{k,l_{k}}\right) \rightarrow 0= V_{\alpha _{k}} \left( u_{k}\right) \), monotonically. This latter case cannot occur when we have a pure IP.
Consider the first case of acceptable descents. Then there exists a sequence \(\left\{ l_{k}\right\} \) such that \(u_{k+1}=u_{k,l_{k}}\) and between iteration \(\left( k,1\right) \) and \(\left( k,l_{k}\right) \), we have \(\alpha _{k+l}=\alpha _{k}\) fixed. Thus, by Lemma 5.3,
where \(u_{k+1}=u_{k,l_{k}}\) and \( \underline{V}_{k+1,0}\left( u_{k+1}\right) = \underline{V}_{k,l_{k}}\left( u_{k,l_{k}}\right) \ge 0\) (as we are in Step 3 of STDR). The model function \( \underline{V}_{k,l_{k}}\left( \cdot \right) \) is not carried to the next stage, but \(\alpha _{k}\) is decreased to \(\alpha _{k+1}\), and we prune subgradients which decrease the new model function to the new initial model \(\underline{V}_{k+1,1}\). Hence, we have the inequality \(\underline{V}_{k,l_{k}}\left( u_{k,l_{k}}\right) - \underline{V}_{k+1,1}\left( u_{k+1}\right) \ge 0\). Thus \( \underline{V}_{k,1}\left( u_{k}\right) - \underline{V}_{k+1,1}\left( u_{k+1}\right) \) equals
For \(M=\sum _{k=0}^{K}l_{k}\), (as we remain in Step 3 of SDTR with \( \underline{V}_{K,1}\left( u_{K}\right) \ge 0\)),
where \(p_{\alpha _{j}}\left( u\right) \) denotes the projection of \(u\) onto the solution set \(S_{\alpha _{j}}\subseteq S^{n}\) of minimizers of \(u\mapsto V_{\alpha _{j}} \left( u\right) \) and \(v_{j}^{*} := \min _{u\in S^{n}} V_{\alpha _{j}} \left( u\right) \). The convergence of the series implies the terms in (19) converge to zero. Next, note that each time we accept a subgradient, (as we have obtained sufficient descent), we decrease the interval \([\underline{\alpha },\alpha _{k}].\) Thus, we have \(\alpha _{j}\downarrow \underline{\alpha }\) as \(j\rightarrow \infty \). As \(\min _{u\in S^{n}} V_{\underline{\alpha }} \left( u\right) <0\), and we assume we remain in Step 3 of SDTR, we have \( V_{\alpha _{j}} \left( u_{j}\right) \ge 0\) and hence: \(\left\| u_{j}-p_{\alpha _{j}}\left( u_{j}\right) \right\| _{\infty }\ge \delta >0\) for some \(\delta \). Thus, there is some \(\epsilon >0\) such that \( V_{\alpha _{j}} \left( u_{j}\right) -v_{j}^{*} \ge \epsilon >0\). Consequently, we must have \(\Delta _{j}\rightarrow 0.\)
Consider the first case when we have a MIP. Note that each time we accept a subgradient, (as we have obtained sufficient descent), we reduce the interval \([\underline{\alpha },\alpha _{k}].\) Thus, we have \(\alpha _{j}\downarrow \underline{\alpha }\) as \(j\rightarrow \infty \) and we may apply Corollary 5.1 to deduce that \(\liminf _{j}\rho _{j}\ge 1\). But this implies that there exists a \(J\) for which \(\rho _{j}\ge \frac{3}{4}\) for \(j\ge J\), forcing \(\Delta _{j+l}=\min \left\{ 2\Delta _{j+l-1},\overline{\Delta }\right\} \). Eventually, we must have \(\Delta _{j}=\overline{\Delta }>0\), a contradiction.
In the case of a pure IP, (no continuous variable), we note that as \(\alpha _{j}\downarrow 0\), and \(X\left( \alpha _{j}\right) :=\left\{ x\in X : cx\le \alpha _{j}\right\} \), for \(j\) sufficiently large, the discrete components of \(X\left( \alpha _{j}\right) \) do not change. As we have a pure IP, the function \( V_{\alpha _{j}} \left( \cdot \right) \) must be constant and equal to \(V_{\underline{\alpha }} \left( \cdot \right) \), for \(j\) sufficiently large. Hence for \(j\) sufficiently large \( V_{\alpha _{j}} \left( \cdot \right) = V_{\underline{\alpha }} \left( \cdot \right) \). We may now apply Corollary 5.1, with \(\alpha _{k}=\underline{\alpha }\) constant, to deduce that \(\liminf _{j}\rho _{j}\ge 1\).
Thus, we cannot have an infinite loop of acceptable descents without an update of a lower or upper bound. After a finite number of iteration, we must have \(\left| \overline{\alpha }-\underline{\alpha }\right| \le \varepsilon \). \(\square \)
Rights and permissions
About this article

Cite this article
Boland, N., Eberhard, A.C. & Tsoukalas, A. A Trust Region Method for the Solution of the Surrogate Dual in Integer Programming. J Optim Theory Appl 167, 558–584 (2015). https://doi.org/10.1007/s10957-014-0681-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-014-0681-9