
Abstract
Two characteristics that make convex decomposition algorithms attractive are simplicity of operations and generation of parallelizable structures. In principle, these schemes require that all coordinates update at the same time, i.e., they are synchronous by construction. Introducing asynchronicity in the updates can resolve several issues that appear in the synchronous case, like load imbalances in the computations or failing communication links. However, and to the best of our knowledge, there are no instances of asynchronous versions of commonly known algorithms combined with inertial acceleration techniques. In this work, we propose an inertial asynchronous and parallel fixed-point iteration, from which several new versions of existing convex optimization algorithms emanate. Departing from the norm that the frequency of the coordinates’ updates should comply to some prior distribution, we propose a scheme, where the only requirement is that the coordinates update within a bounded interval. We prove convergence of the sequence of iterates generated by the scheme at a linear rate. One instance of the proposed scheme is implemented to solve a distributed optimization load sharing problem in a smart grid setting, and its superiority with respect to the nonaccelerated version is illustrated.






Similar content being viewed by others
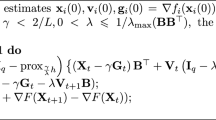

Notes
For two nonnegative real numbers x and y, it holds that \(xy\le \frac{\delta x^2}{2}+\frac{y^2}{2\delta }\) for every \(\delta >0\).
References
Combettes, P.L., Vũ, B.C.: Variable metric forward–backward splitting with applications to monotone inclusions in duality. Optimization 63(9), 1289–1318 (2014)
Alvarez, F., Attouch, H.: An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Anal. 9(1), 3–11 (2001)
Liu, J., Wright, S.J.: Asynchronous stochastic coordinate descent: parallelism and convergence properties. SIAM J. Optim. 25(1), 351–376 (2015)
Peng, Z., Xu, Y., Yan, M., Yin, W.: ARock: an algorithmic framework for asynchronous parallel coordinate updates. SIAM J. Sci. Comput. 38(5), A2851–A2879 (2016)
Bertsekas, D.P., Tsitsiklis, J.N.: Parallel and Distributed Computation. Prentice Hall Inc., New Jersey (1989)
Wright, S.J.: Coordinate descent algorithms. Math. Program. 151(1), 3–34 (2015)
Bauschke, H., Combettes, P.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer, New York (2011)
Ruy, E., Boyd, S.: A primer on monotone operator methods. Appl. Comput. Math. 15(1), 3–43 (2016)
Polyak, B.: Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 4(5), 1–17 (1987)
Ochs, P., Brox, T., Pock, T.: iPiasco: inertial proximal algorithm for strongly convex optimization. J. Math. Imaging Vis. 53(2), 171–181 (2015)
Gurbuzbalaban, M., Ozdaglar, A., Parrilo, P.: On the convergence rate of incremental aggregated gradient algorithms. SIAM J. Optim. 27(2), 1035–1048 (2017)
Polyak, B.: Introduction to Optimization. Optimization Software Inc., Publication Division, New York (1987)
Ghadimi, E., Feyzmahdavian, H.R., Johansson, M.: Global convergence of the heavy-ball method for convex optimization. In: 2015 European Control Conference (ECC), pp. 310–315. IEEE (2015)
Moudafi, A., Oliny, M.: Convergence of a splitting inertial proximal method for monotone operators. J. Comput. Appl. Math. 155(2), 447–454 (2003)
Krasnosel’skiĭ, A.: Two remarks on the method of successive approximations. Uspekhi Matematicheskikh Nauk 10(1), 123–127 (1955)
Mann, R.: Mean value methods in iteration. Proc. Am. Math. Soc. 4(3), 506–510 (1953)
Liang, J., Fadili, J., Peyré, G.: Convergence rates with inexact non-expansive operators. Math. Program. 159, 1–32 (2014)
Alvarez, F.: Weak convergence of a relaxed and inertial hybrid projection-proximal point algorithm for maximal monotone operators in Hilbert space. SIAM J. Optim. 14(3), 773–782 (2004)
Maingé, P.E.: Convergence theorems for inertial KM-type algorithms. J. Comput. Appl. Math. 219(1), 223–236 (2008)
Iutzeler, F., Hendrickx, M.J.: A Generic Linear Rate Acceleration of Optimization algorithms via Relaxation and Inertia. arXiv preprint arXiv:1603.05398v2 (2016)
Feyzmahdavian, H.R., Aytekin, A., Johansson, M.: A delayed proximal gradient method with linear convergence rate. In: IEEE International Workshop on Machine Learning for Signal Processing (MLSP), pp. 1–6 (2014)
Combettes, P.L., Eckstein, J.: Asynchronous block-iterative primal-dual decomposition methods for monotone inclusions. Math. Program. 168, 645–672 (2016)
Mishchenko, K., Iutzeler, F., Malick, J.: A Distributed Flexible Delay-tolerant Proximal Gradient Algorithm. arXiv preprint arXiv:1806.09429 (2018)
Raguet, H., Fadili, J., Peyré, G.: A generalized forward–backward splitting. SIAM J. Imaging Sci. 6(3), 1199–1226 (2013)
Raguet, H., Landrieu, L.: Preconditioning of a generalized forward–backward splitting and application to optimization on graphs. SIAM J. Imaging Sci. 8(4), 2706–2739 (2015)
Briceno-Arias, L.M.: Forward-Douglas-Rachford splitting and forward-partial inverse method for solving monotone inclusions. arXiv preprint arXiv:1212.5942 (2012)
Davis, D.: Convergence rate analysis of the forward-Douglas-Rachford splitting scheme. arXiv preprint arXiv:1410.2654 (2015)
Combettes, P.L., Condat, L., Pesquet, J.C., Vũ, B.C.: A forward–backward view of some primal-dual optimization methods in image recovery. In: The IEEE International Conference on Image Processing, pp. 4141–4145 (2014)
Dunning, I., Huchette, J., Lubin, M.: Jump: a modeling language for mathematical optimization. SIAM Rev. 59(2), 295–320 (2017)
Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 67, 301–320 (2005)
Fabietti, L., Gorecki, T.T., Namor, E., Sossan, F., Paolone, M., Jones, C.N.: Dispatching active distribution networks through electrochemical storage systems and demand side management (2017)
Gorecki, T.T., Qureshi, F.A., Jones, C.N.: Openbuild: an integrated simulation environment for building control (2015)
Swissgrid: Test for Secondary Control Capability. https://www.swissgrid.ch/dam/swissgrid/customers/topics/ancillary-services/prequalification/4/D171130-Test-for-secondary-control-capability-V3R0-EN.pdf (2003)
Acknowledgements
This project has received funding from the European Research Council (ERC) under the European Unions Horizon 2020 research and innovation programme (Grant Agreement No. 755445).
Author information
Authors and Affiliations
Corresponding author
Additional information
Alexandre Cabot.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
1.1 Proof of Lemma 5.1
Proof
Using Assumption 1 and Eq. (7), we can start by rewriting \(y_B=(T_B x^i_\mathrm {read})[i]\).
where \(d_k[i]=\gamma \left( (Bx_{k})[i]-(Bx^i_\mathrm {read})[i]\right) - a_k^i[i]\).
Similarly, we have from Eq. (7) that
Using the above relations, a coordinate update of iteration (6) can be expressed as
or, equivalently, as
with \(e_k[i] = T_{A_{i}}((T_Bx_k)[i] + d_k[i] + \beta (c_k^i[i]-b_k^i[i])) - T_{A_{i}}((T_Bx_k)[i])\), which concludes the proof. \(\square \)
1.2 Proof of Lemma 5.2
Proof
Squaring (9) we get:
Let us now analyze the second and third term in (22).
-
Bound \(-2\eta \langle x_k-x_*, Sx_k-e_k \rangle \): We will upper-bound the resulting inner product terms. In order to do so, we use both the cocoercivity and the quasi-strong monotonicity of S, the former proven in ‘Appendix A.6,’ and the latter holding from Assumption 1. Since S is 1 / 2-cocoercive, we have that
$$\begin{aligned} \langle x_k-x_*,Sx_k\rangle \ge \frac{1}{2}\Vert Sx_k\Vert ^2. \end{aligned}$$From the quasi-\(\nu \)-strong monotonicity of S, we have:
$$\begin{aligned} \langle x_k-x_*,Sx_k\rangle \ge \nu \Vert x_k-x_*\Vert ^2. \end{aligned}$$Putting these two together, we get that
$$\begin{aligned} -2\eta \langle x_k-x_*,Sx_k\rangle \le -\eta \nu {\mathbf {dist} }_k^2 -\frac{\eta }{2}\Vert Sx_k\Vert ^2. \end{aligned}$$(23)For the second inner product term involving the error, we can easily derive the bound
$$\begin{aligned} 2\eta \langle x_k-x_*,e_k\rangle \le 2\eta {\mathbf {dist} }_k\Vert e_k\Vert . \end{aligned}$$(24)Equations (23) and (24) result in the bound
$$\begin{aligned} -2\eta \langle x_k-x_*, Sx_k-e_k\rangle \le -\eta \nu {\mathbf {dist} }_k^2-\frac{\eta }{2}\Vert Sx_k\Vert ^2 + 2\eta {\mathbf {dist} }_k\Vert e_k\Vert . \end{aligned}$$(25) -
Bound \(\eta ^2\Vert Sx_k-e_k\Vert ^2\): By developing the square, we have that
$$\begin{aligned} \eta ^2\Vert Sx_k-e_k\Vert ^2&= \eta ^2 (\Vert Sx_k\Vert ^2 -2\langle Sx_k,e_k\rangle + \Vert e_k\Vert ^2). \end{aligned}$$(26)The inner product term in (26) can be bounded by employing Young’s inequalityFootnote 1 as follows:
$$\begin{aligned} -\,2\langle Sx_k,e_k\rangle&\le 2\Vert Sx_k\Vert \Vert e_k\Vert \nonumber \\&\le 2\left( \frac{\delta }{2}\Vert Sx_k\Vert ^2+\frac{1}{2\delta }\Vert e_k\Vert ^2\right) \nonumber \\&= \delta \Vert Sx_k\Vert ^2 + \frac{1}{\delta }\Vert e_k\Vert ^2, \end{aligned}$$(27)for any \(\delta >0\). Putting together (26) and (27), we get the bound:
$$\begin{aligned} \eta ^2\Vert Sx_k-e_k\Vert ^2 \le \eta ^2(1+\delta )\Vert Sx_k\Vert ^2 + \eta ^2\frac{(\delta +1)}{\delta }\Vert e_k\Vert ^2. \end{aligned}$$(28)
Using (25) and (28), inequality (22) can be written as
The second term in the sum can be eliminated by assuming that
which gives rise to the inequality
The complicating term on the right-hand side can be eliminated by using once more Young’s inequality, i.e.,
1.3 Proof of Lemma 5.3
Proof
We will bound the error term \(\Vert e_k\Vert \) componentwise. For some arbitrary \(i\in \{1,\ldots ,N\}\) and \(k\in \mathbb {N}\), we have from (13) that
Consequently,
The first term can be recovered by using the 1 / L-cocoercivity of B (Assumption 1) in (11), as well as the inequality \(\Vert a_k^i[i]\Vert \le \Vert a_k^i\Vert \), while the second term follows from the inequality
-
We want to bound the two summands of (32). Let us start with bounding \(\Vert a_k^i\Vert \), for which we have for all i:
$$\begin{aligned} \underset{1\le i\le N}{\max }\Vert a_k^i\Vert&\le \sum _{m=k-2\tau }^{k-1}\Vert x_{m+1}-x_m\Vert \nonumber \\&= \eta \sum _{m=k-2\tau }^{k-1}\Vert e_m-Sx_m\Vert \nonumber \\&\le \eta \left( \sum _{m=k-2\tau }^{k-1}\Vert e_m\Vert +\sum _{m=k-2\tau }^{k-1}\Vert Sx_m\Vert \right) \nonumber \\&\le \eta \sum _{m=k-2\tau }^{k-1}(\Vert d_m\Vert + \beta \Vert c_m-b_m\Vert + \Vert Sx_m\Vert ). \end{aligned}$$(33)The first inequality follows from the definitions of \(a_k^i\) in (7), the first equality from (9), while the last two inequalities from the triangle inequality and (13).
-
Bound \(\Vert c_k-b_k\Vert \): Following the same process as in (33), we have that
$$\begin{aligned} \underset{1\le i\le N}{\max }(\Vert c_k^i\Vert +\Vert b_k^i\Vert )&\le \sum _{m=k-3\tau }^{k-1}\Vert x_{m+1}-x_m\Vert + \sum _{m=k-2\tau }^{k-1}\Vert x_{m+1}-x_m\Vert \nonumber \\&\le \eta \left( \sum _{m=k-3\tau }^{k-1}(\Vert d_m\Vert + \beta \Vert c_m-b_m\Vert + \Vert Sx_m\Vert ) \right. \nonumber \\&\left. \quad +\,\sum _{m=k-2\tau }^{k-1}(\Vert d_m\Vert + \beta \Vert c_m-b_m\Vert + \Vert Sx_m\Vert )\right) . \end{aligned}$$(34)
Finally, (33), and (34) can be bounded by means of the quantity (\(\varSigma \)), and by substituting (33) to (32), the result follows.
1.4 Proof of Lemma 5.4
Proof
Let us start by bounding the quantities involved in (\(\varSigma \)), namely \(\Vert b_k\Vert \), \(\Vert c_k\Vert \) and \(\Vert d_k\Vert \) with respect to the maximum distance from the optimizer. The following inequalities hold:
Note, also, that \(\forall \;i=1,\ldots ,N\) and for \(l_i\in \{1,\ldots ,K\}\) holds
Since the first inequality holds \(\forall \;i=1,\ldots ,N\), by denoting \(i_*={{\text { argmax}}}_{{i\in \{1,\ldots ,N\}}}\Vert x_k-x_{k-l_i}\Vert \), we get
From the definition of \(a_k^i\) in (7), we have that
for some \(l_i\in \{1,\ldots ,2\tau \}\).
Substituting in (35), and following developments similar to (36), we conclude that
Using (37), the sums can be easily bounded as shown below.
the last inequality following from Corollary 4.1.
From the definition of \(\varSigma _K(k)\) in (\(\varSigma \)) and from (38), by introducing
we have that
Since (\(\varSigma \)) is bounded, we can accordingly bound (13a) and (13b):
Using (39a) and (39b), \(\Vert e_k\Vert \) from (13) can be bounded as
where we bounded the quantities with the maximum delay that appeared in (39a) and (39b).
1.5 Proof of Theorem 5.1
Proof
Note that, (16) simplifies to
As a result, we need to find parameters \(\eta ,\beta ,\gamma ,\delta ,\epsilon \) such that the following set of inequalities is satisfied:
The upper-bound \(\gamma _{\max }\) ensures that the stepsize \(\gamma \) is admissible (a possible option is, e.g., \(\gamma _{\max }=2/L\) as proven in ‘Appendix A.6’). We start by noting that the values of \(\delta \) and \(\epsilon \) are irrelevant as long as they are positive. To this end, we can start by choosing \(\epsilon \) such that \(\nu -\epsilon >0\). From the inequality \(\eta <1/(2(1+\delta ))\), it follows that
thus having
from which the result follows. \(\square \)
1.6 Proof of Corollary 4.1.
Proof
-
From Assumption 1, B is 1 / L-cocoercive, which means that \(\gamma B\) is \(1/\gamma L\)-cocoercive. It follows from [24, Proposition 4.13] that \(T_B=I-\gamma B\) is \(\gamma L/2\)-averaged. From [7, Proposition 4.25 (i)], it follows that \(T_B\) is nonexpansive provided that \(\gamma <2/L\). Finally, we conclude that T is nonexpansive as the composition of nonexpansive operators.
-
From [7, Proposition 4.33], we have that S is 1 / 2-cocoercive if and only if T is nonexpansive, which is proven above.
-
The claim is proven in [4, Proposition 2] for the case of the proximal gradient method. The proof below is essentially the same generalized for an operator T. From [7, Example 22.5], we have that if T is c-Lipschitz continuous for some \(c\in [0,1)\) then \(I-T\) is \((1-c)\)-strongly monotone. Let us then prove that T is indeed Lipschitz continuous. For any \(x\in \mathcal {H}\) and \(x_*\in {\text {fix}} T\), it holds that:
$$\begin{aligned} \Vert T_Bx-T_Bx_*\Vert ^2&= \Vert x-x_*\Vert ^2-2\gamma \langle x-x_*,Bx-Bx_*\rangle +\gamma ^2\Vert Bx-Bx_*\Vert ^2 \nonumber \\&\le \Vert x-x_*\Vert ^2-\gamma (2-\gamma L)\langle x-x_*,Bx-Bx_*\rangle \nonumber \\&\le \Vert x-x_*\Vert ^2-\mu \gamma (2-\gamma L)\Vert x-x_*\Vert ^2 \nonumber \\&= (1-2\gamma \mu +\mu \gamma ^2L)\Vert x-x_*\Vert ^2, \end{aligned}$$where the first inequality follows from the 1 / L-cocoercivity of B, while the second one from the \(\mu \)-strong monotonicity of B.
Thus, \(\Vert T_Bx-T_Bx_*\Vert \le \sqrt{(1-2\gamma \mu +\mu \gamma ^2L)}\Vert x-x_*\Vert \) and since \(T_A\) is nonexpansive, we have that \(\Vert Tx-Tx_*\Vert \le \sqrt{(1-2\gamma \mu +\mu \gamma ^2L)}\Vert x-x_*\Vert \). Finally, S is quasi-\(\nu \)-strongly monotone with \(\nu =1-\sqrt{(1-2\gamma \mu +\mu \gamma ^2L)}\) for \(\gamma <2/L\).
\(\square \)
1.7 Proof of Lemma 6.1.
Proof
Since \(T_A=\mathbf{prox}_{\gamma g}\), it is firmly nonexpansive from [7, Proposition 12.27], and 1 / 2-averaged from [7, Proposition 4.2]. In addition, and as we saw in ‘Appendix A.6,’ \(T_B=I-\gamma \nabla f\) is \(\gamma L/2\)-averaged from [24, Proposition 4.13]. Since \(T=T_AT_B\), the composition is \(\alpha \)-averaged from [7, Proposition 4.24], with \(\alpha =\max \left\{ \frac{2}{3},\frac{2}{1+\frac{2}{\gamma L}}\right\} \). Making use of [7, Proposition 4.25 (iii)], we have that for all \(x\in {\mathbb {R} }^n,y\in {\mathbb {R} }^n\):
After performing the simplifications, we end up having
which concludes the proof. \(\square \)
Rights and permissions
About this article

Cite this article
Stathopoulos, G., Jones, C.N. An Inertial Parallel and Asynchronous Forward–Backward Iteration for Distributed Convex Optimization. J Optim Theory Appl 182, 1088–1119 (2019). https://doi.org/10.1007/s10957-019-01542-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-019-01542-7