
Abstract
We consider the problem of temporal fair scheduling of queued data transmissions in wireless heterogeneous networks. We deal with both the throughput maximization problem and the delay minimization problem. Taking fairness constraints and the data arrival queues into consideration, we formulate the transmission scheduling problem as a Markov decision process (MDP) with fairness constraints. We study two categories of fairness constraints, namely temporal fairness and utilitarian fairness. We consider two criteria: infinite horizon expected total discounted reward and expected average reward. Applying the dynamic programming approach, we derive and prove explicit optimality equations for the above constrained MDPs, and give corresponding optimal fair scheduling policies based on those equations. A practical stochastic-approximation-type algorithm is applied to calculate the control parameters online in the policies. Furthermore, we develop a novel approximation method—temporal fair rollout—to achieve a tractable computation. Numerical results show that the proposed scheme achieves significant performance improvement for both throughput maximization and delay minimization problems compared with other existing schemes.







Similar content being viewed by others
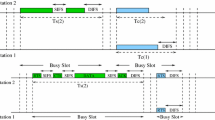
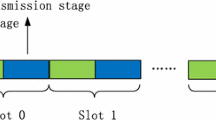
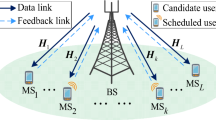
Notes
An MDP is unichain if the transition matrix corresponding to every deterministic stationary policy consists of one single recurrent class plus a possibly empty set of transient state [12].
References
Zhang Z, Moola S, Chong EKP (2008) Approximate stochastic dynamic programming for opportunistic fair scheduling in wireless networks. In: Proc. 47th IEEE conference on decision and control, Cancun, 9–11 December 2008, pp 1404–1409
Knopp R, Humblet P (1995) Information capacity and power control in single cell multiuser communications. In: Proc. IEEE int. conference on communications 1995, vol 1, pp 331–335
Andrews M, Kumaran K, Ramanan K, Stolyar A, Whiting P, Vijayakumar R (2001) Providing quality of service over a shared wireless link. IEEE Commun Mag 39(2):150–153
Bender P, Black P, Grob M, Padovani R, Sindhushyana N, Viterbi A (2000) Cdma/hdr: a bandwidth-efficient high-speed wireless data service for nomadic users. IEEE Commun Mag 38(7):70–77
Andrews M (2005) A survey of scheduling theory in wireless data networks. In: Proc. 2005 IMA summer workshop on wireless communications
Parkvall S, Dahlman E, Frenger P, Beming P, Persson M (2001) The high speed packet data evolution of wcdma. In: Proc. IEEE VTC 2001, vol 3, pp 2287–2291
Liu X, Chong EKP, Shroff NB (2001) Opportunistic transmission scheduling with resource-sharing constraints in wireless networks. IEEE J Sel Areas Commun 19(10):2053–2064
Liu X, Chong EKP, Shroff NB (2003) A framework for opportunistic scheduling in wireless networks. Comput Netw 41(4):451–474
Liu X, Chong EKP, Shroff NB (2004) Opportunistic scheduling: an illustration of cross-layer design. Telecommun Rev 14(6):947–959
Wang HS, Moayeri N (1995) Finite-state markov channel—a useful model for radio communication channels. IEEE Trans Veh Technol 43:163–171
Kelly F (1997) Charging and rate control for elastic traffic. Eur Trans Telecommun 8:33–37
Puterman ML (1994) Markov decision processes. Wiley, New York
Bertsekas DP (2001) Dynamic programming and optimal control, 2nd ed. Athena, Belmont
Ross SM (1970) Applied probability models with optimization applications. Dover, New York
Derman C (1970) Finite sate Markovian decision processes. Academic, New York
Altman E (1998) Constrained Markov decision processes. Chapman and Hall/CRC, London
Piunovskiy AB (1997) Optimal control of random sequences in problems with constraints. Kluwer, Dordrecht
Feinberg EA, Shwartz A (eds) (2002) Handbook of Markov decision processes: methods and applications. Kluwer, Boston
Ross KW (1989) Randomized and past-dependent policies for Markov decision processes with multiple constraints. Oper Res 37(3):474–477
Piunovskiy AB, Mao X (2000) Constrained markovian decision processes: the dynamic programming approach. Oper Res Lett 27:119–126
Chen RC, Blankenship GL (2004) Dynamic programming equations for discounted constrained stochastic control. IEEE Trans Automat Contr 49(5):699–709
Bertsekas DP, Tsitsiklis JN (1996) Neuro-dynamic programming. Athena, Belmont
Bertsekas DP, Tsitsiklis JN, Wu C (1997) Rollout algorithms for combinatorial optimization. J Heuristics 3:245–262
Bertsekas DP, Castanon DA (1999) Rollout algorithms for stochastic scheduling problems. J Heuristics 5(1):89–108
Gesbert D, Slim-Alouini M (2004) How much feedback is multi-user diversity really worth? In: Proc. IEEE international conference on communications, pp 234–238
Floren F, Edfors O, Molin BA (2003) The effect of feedback quantization on the throughput of a multiuser diversity scheme. In: Proc. IEEE global telecommunication conference (GLOBECOM’03), pp 497–501
Svedman P, Wilson S, Cimini LJ Jr., Ottersten B (2004) A simplified opportunistic feedback and scheduling scheme for ofdm. In: Proc. IEEE vehicular technology conference 2004
Al-Harthi Y, Tewfik A, Alouini MS (2007) Multiuser diversity with quantized feedback. IEEE Trans Wirel Commun 6(1):330–337
Parekh AK, Gallager RG (1993) A generalized processor sharing approach to flow control in integrated services networks: the single-node case. IEEE/ACM Trans Netw 1(3):344–357
Kushner HJ, Yin GG (2003) Stochastic approximation and recursive algorithms and applications, 2nd ed. Springer, New York
Chen HF (2002) Stochastic approximation and its applications. Kluwer, Dordrecht
Gilbert E (1960) Capacity of a burst-noise channel. Bell Syst Technol J 39:1253–1265
Elliott EO (1963) Estimates of error rates for codes on burst-noise channels. Bell Syst Technol 42:1977–1997
Swarts F, Ferreira HC (1993) Markov characterization of channels with soft decision outputs. IEEE Trans Commun 41:678–682
Author information
Authors and Affiliations
Corresponding author
Additional information
This research was supported in part by NSF under grant ECCS-0700559. Parts of an early version of this paper was presented at the IEEE Conference on Decision and Control 2008 [1].
Appendix
Appendix
1.1 A Proof of Lemma 1
Proof
Let π be an arbitrary policy, and suppose that π chooses action a at time slot 0 with probability P a , a ∈ A. Then,
where W π (s′) represents the expected discounted weighted reward with the weight u(π t ) incurred from time slot 1 onwards, given that π is employed and the state a time 1 is s′. However, it follows that
and hence that
Since π is arbitrary, Eq. 23 implies that
To go the other way, let a 0 be such that
and let π be the policy that chooses a 0 at time 0; and, if the next state is s′, views the process as originating in state s′; and follows a policy π s′, which is such that \(V_{\pi_{s'}}(s')\geq V_{\alpha}(s')-\varepsilon\), s′ ∈ S. Hence,
which, since V α (s) ≥ V π (s), implies that
Hence, from Eq. 25, we have
Since π s′ could be arbitrary, then ε is arbitrary, from Eqs. 24 and 26, we have
□
1.2 B Proof of Lemma 2
Proof
By applying the mapping \(T_{\pi^*}\) to V α , we obtain
where the last equation follows from Lemma 1. Hence, by induction we have,
Letting n→ ∞ and using Banach fixed-point theorem yields the result,
□
1.3 C Proof of Theorem 1
Proof
Let π be a policy satisfying the expected discounted temporal fairness constraint. And suppose there exists u:A→ℝ satisfying conditions 1–3. Then,
Since \(V_{\pi}(s)\leq V_{\alpha}(s)=V_{\pi^*}(s)\) from Lemma 2, we have
where the second part of Eq. 28 equals zero because of condition 3 on u. From Eq. 27, we get the corresponding optimal discounted reward as
□
1.4 D Proof of Theorem 2
Proof
Let π be a policy satisfying the expected average temporal fairness constraint; and let H t = (X 0,π 0,..., X t − 1,π t − 1,X t ,π t ) denote the history of the process up to time t. First, we have
since
Also,
with equality for π *, since π * is defined to take the maximizing action. Hence,
Letting T → ∞ and using the fact that h is bounded, we have that
Since we know that u ≥ 0, and that the policy π satisfies the temporal fairness constraints, the second part of Eq. 29 is greater than or equal to zero. We get
With policy π *, we have
where the second part of Eq. 30 equals to zero because of condition 3 on u(a). Hence, the desired result is proven. □
1.5 E Proof of Theorem 3
Proof
Let π be a policy satisfying the expected discounted utilitarian fairness constraint. And suppose there exists ω:A→ℝ satisfying conditions 1–3. Then,
where \(\kappa\!=\!1\!-\!\sum_{\pi_t\in A}D(\pi_t)\omega(\pi_t)\). Since U π (s) ≤ U α (s) = \(U_{\pi^*}(s)\) from Lemma 4, we have
where the second part of Eq. 32 equals zero because of condition 3 on ω. From Eq. 31, we get the corresponding optimal discounted reward is
□
1.6 F Proof of Theorem 4
Proof
Let π be a policy satisfying the expected average utilitarian fairness constraint; and let H t = (X 0,π 0,..., X t − 1,π t − 1,X t ,π t ) denote the history of the process up to time t. First, we have
Also,
with equality for π *, since π * is defined to take the maximizing action. Hence,
Letting T → ∞ and using the fact that h is bounded, we have that
Since we know that ω ≥ 0, and that the policy π satisfies the utilitarian fairness constraints, the second part of Eq. 33 is greater than or equal to zero. We get
With policy π *, we have
where the second part of Eq. 34 equals to zero because of condition 3 on ω(a). Hence, the desired result is proven. □
Rights and permissions
About this article
Cite this article
Zhang, Z., Moola, S. & Chong, E.K.P. Opportunistic Fair Scheduling in Wireless Networks: An Approximate Dynamic Programming Approach. Mobile Netw Appl 15, 710–728 (2010). https://doi.org/10.1007/s11036-009-0198-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11036-009-0198-x