
Abstract
Multimedia Event Detection(MED) is a multimedia retrieval task with the goal of finding videos of a particular event in video archives, given example videos and event descriptions; different from MED, multimedia classification is a task that classifies given videos into specified classes. Both tasks require mining features of example videos to learn the most discriminative features, with best performance resulting from a combination of multiple complementary features. How to combine different features is the focus of this paper. Generally, early fusion and late fusion are two popular combination strategies. The former one fuses features before performing classification and the latter one combines output of classifiers from different features. Early fusion can better capture the relationship among features yet is prone to over-fit the training data. Late fusion deals with the over-fitting problem better but does not allow classifiers to train on all the data at the same time. In this paper, we introduce a fusion scheme named double fusion, which simply combines early fusion and late fusion together to incorporate their advantages. Results are reported on the TRECVID MED 2010, MED 2011, UCF50 and HMDB51 datasets. For the MED 2010 dataset, we get a mean minimal normalized detection cost (MMNDC) of 0.49, which exceeds the state-of-the-art performance by more than 12 percent. On the TRECVID MED 2011 test dataset, we achieve a MMNDC of 0.51, which is the second best among all 19 participants. On UCF50 and HMDB51, we obtain classification accuracy of 88.1 % and 48.7 % respectively, which are the best reported results to date.





Similar content being viewed by others

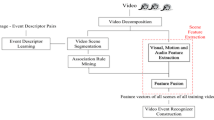

References
Ayache S, Quenot G, Gensel J (2007) Classifier fusion for SVM-based multimedia semantic indexing. In: European conference on information retrieval (ECIR’07)
Bao L, Yu S, Lan Z, Overwijk A, Jin Q, Langner B, Garbus M, Burger S, Metze F, Hauptmann A (2011) Informedia @ TRECVID 2011. In: TRECVID video retrieval evaluation workshop
Bernhard S, Burges CJC, Smola AJ (1999) Advances in kernel methods: support vector learning. MIT Press, Cambridge, MA
Brefeld U, Gaertner T, Scheffer T, Wrobel S (2006) Efficient co-regularized least squares regression. In: International conference of machine learning (ICML’06)
Chang C-C, Lin C-J (2001) LIBSVM: a library for support vector machines
Chen MY, Hauptmann A (2009) MoSIFT: recognizing human actions in surveillance videos. CMU-CS-09-161, Carnegie Mellon University
Cortes C, Mohri M, Rostamizadeh A (2009) L 2 regularization for learning kernels. In: Conference on uncertainty in artificial intelligence (UAI’09)
Erp MV, Vuurpijl LG, Schomaker L (2002) An overview and comparison of voting methods for pattern recognition. In: International workshop on frontiers in handwriting recognition (IWFHR-8)
Gehler P, Nowozin S (2209) On feature combination for multiclass object classification. In: International conference computer vision (ICCV’09)
Hauptmann A, Yan R, Lin W, Christel M, Wactlar H (2007) Can high-level concepts fill the semantic gap in video retrieval? A case study with broadcast news. IEEE Trans Multimedia (TMM) 9(5):958–966
Iyengar G, Nock H, Neti C (2003) Discriminative model fusion for semantic concept detection and annotation in video. In: ACM international conference multimedia (MM’03)
Jiang YG, Zeng XH, Chang SF et al (2010) Columbia-UCF TRECVID2010 multimedia event detection: combining multiple modalities, contextual concepts, and temporal matching. In: TRECVID video retrieval evaluation workshop
Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T (2011) HMDB: a large video database for human motion recognition. In: International conference computer vision (ICCV’11)
Lan Z, Bao L, Yu S, Liu W, Hauptmann A (2012) Double fusion for multimedia event detection. In: International confernce on multimedia modeling
Laptev I, Lindeberg T (2003) Space-time interest points. In: International conference on computer vision (ICCV’03)
Lazebnik S, Schmid C, Ponce J (2006) Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In: IEEE conference on computer vision and pattern recognition (CVPR’06)
Li H, Bao L, Hauptmann A et al (2010) Informedia @ TRECVID 2010. In: TRECVID video retrieval evaluation workshop
Liu J, Luo J, Shah M (2009) Recognizing realistic actions from vides ‘in the wild’. In: IEEE conference on computer vision and pattern recognition (CVPR’09)
Liu J, Yang Y, Shah M (2009) Learning semantic visual vocabularies using diffusion distance. In: IEEE conference on computer vision and pattern recognition (CVPR’09)
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis (IJCV) 60(2):91–100
Nechyba MC, Brandy L, Schneiderman H (2007) Pittpatt face detection and tracking for the CLEAR 2007 evaluation. In: Classifcation of events, activities and relations evaluation and workshop
Oliva A, Torralba A (2001) Modeling the shape of the scene: a holistic representation of the spatial envelope. Int J Comput Vis (IJCV) 42(3):145–175
Over P, Awad G, Fiscus J, Michel M, Antonishek B, Smeaton A, Kraaij W, Quenot G (2011) TRECVid 2011 goals, tasks, data, evaluation mechanisms and metrics. In: TRECVID video retrieval evaluation workshop
Smeaton AF, Over P, Kraaij W (2006) Evaluation campaigns and TRECVid. In: ACM international workshop on multimedia information retrieval (MIR’06)
Snoek CGM, Worringm M, Smeulders AWM (2005) Early versus late fusion in semantic video analysis. In: ACM international conference multimedia (MM’05)
van de Sande KEA, Gevers T, Snoek CGM (2008) Evaluation of color descriptors for object and scene recognition. In: IEEE conference on computer vision and pattern recognition (CVPR’08)
Vedaldi A, Fulkerson B (2008) VLFeat: an open and portable library of computer vision algorithms
Yang Y, Zhuang Y, Wu F, Pan Y (2008) Harmonizing hierarchical manifolds for multimedia document semantics understanding and cross-media retrieval. IEEE Trans Multimedia (TMM) 10(3):437–446
Yang Y, Zhuang Y, Wu F, Pan Y (2008) Harmonizing hierarchical manifolds for multimedia document semantics understanding and cross-media retrieval. IEEE Trans Multimedia (TMM) 10(3):437–446
Acknowledgements
This work was supported in part by the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior National Business Center contract number D11PC20068. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DoI/NBC, or the U.S. Government. Support was also provided, in part, by the National Science Foundation, under award CCF-1019104, and the Gordon and Betty Moore Foundation, in the eScience project. We thank the Parallel Data Lab for the use of their resources.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Lan, Zz., Bao, L., Yu, SI. et al. Multimedia classification and event detection using double fusion. Multimed Tools Appl 71, 333–347 (2014). https://doi.org/10.1007/s11042-013-1391-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-013-1391-2