
Abstract
Although the bag-of-visual-words (BOVW) model in computer vision has been demonstrated successfully for the retrieval of particular objects, it suffers from limited accuracy when images of the same object are very different in terms of viewpoint or scale. Naively leveraging multiple views of the same object to query the database naturally alleviates this problem to some extent. However, the bottleneck appears to be the presence of background clutter, which causes significant confusion with images of different objects. To address this issue, we explore the structural organization of interest points within multiple query images and select those that derive from the tentative region of interest (ROI) to significantly reduce the negative contributions of confusing images. Specifically, we propose the use of a multi-layered undirected graph model built on sets of Hessian affine interest points to model the images’ elastic spatial topology. We detect repeating patterns that preserve a coherent local topology, show how these redundancies are leveraged to estimate tentative ROIs, and demonstrate how this novel interest point selection approach improves the quality of visual matching. The approach is discriminative in distinguishing clutter from interest points, and at the same time, is highly robust as regards variation in viewpoint and scale as well as errors in interest point detection and description. Large-scale datasets are used for extensive experimentation and discussion.














Similar content being viewed by others



Notes
1 http://www.robots.ox.ac.uk/ ∼vgg/research/affine/#software
2 http://www.robots.ox.ac.uk/ ∼vgg/software/fastcluster/
3 http://www.robots.ox.ac.uk/ ∼vgg/software/fastann/
4 http://www.cs.cmu.edu/afs/cs/project/quake/public/www/triangle.html
5 http://www.brl.ntt.co.jp/people/wu.xiaomeng/MTAP2013/sup.pdf
Fig. 10 
ROIs estimated with interest point selection approaches. The AP is noted in brackets for each run under settings OB/OBF100K (Magdalen)
Fig. 11 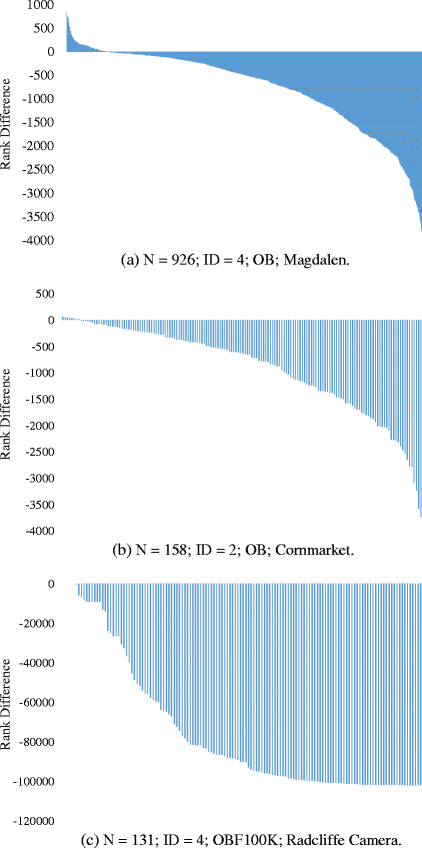
The rank difference of false images after interest point selection based on MSDT. N: the number of false images; ID: the ID of the query image, which caused these false images to be top-ranked; OB/OBF100K: the experimental setting under which retrieval is performed; Magdalen/Cornmarket/Radcliffe Camera: the query name


References
Arandjelovic R, Zisserman A (2012) Multiple queries for large scale specific object retrieval. In: BMVC, pp 1–11
Arandjelovic R, Zisserman A (2012) Three things everyone should know to improve object retrieval. In: CVPR, pp 2911–2918
Bay H, Ess A, Tuytelaars T, Gool LJV (2008) Speeded-up robust features (surf). Comp Vision Image Underst 110(3):346–359
Berg Md, Cheong O, Kreveld Mv, Overmars M (2008) Computational geometry: algorithms and applications, 3rd edn. Springer-Verlag TELOS, Santa Clara
Chum O, Mikulík A, Perdoch M, Matas J (2011) Total recall ii: query expansion revisited. In: CVPR, pp 889–896
Cox IJ, Miller ML, Minka TP, Papathomas TV, Yianilos PN (2000) The bayesian image retrieval system, pichunter: theory, implementation, and psychophysical experiments. IEEE Trans Image Processing 9(1): 20–37
Gammeter S, Bossard L, Quack T, Gool LJV (2009) I know what you did last summer: object-level auto-annotation of holiday snaps. In: ICCV, pp 614–621
Heller KA, Ghahramani Z (2006) A simple bayesian framework for content-based image retrieval. In: CVPR, vol 2, pp 2110–2117
Jegou H, Douze M, Schmid C (2008) Hamming embedding and weak geometric consistency for large scale image search. In: ECCV, vol 1, pp 304–317
Jegou H, Douze M, Schmid C (2010) Improving bag-of-features for large scale image search. Int J Comput Vis 87(3):316–336
Kalantidis Y, Pueyo LG, Trevisiol M, van Zwol R, Avrithis YS (2011) Scalable triangulation-based logo recognition. In: ICMR, p 20
Knopp J, Sivic J, Pajdla T (2010) Avoiding confusing features in place recognition. In: ECCV (1), pp 748–761
Li F, Kosecka J (2006) Probabilistic location recognition using reduced feature set. In: ICRA, pp 3405–3410
Liu Z, Li H, Zhou W, Tian Q (2012) Embedding spatial context information into inverted file for large-scale image retrieval. In: ACM multimedia, pp 199–208
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis 60(2):91–110
Matas J, Chum O, Urban M, Pajdla T (2002) Robust wide baseline stereo from maximally stable extremal regions. In: BMVC, pp 1–10
Mikolajczyk K, Schmid C (2004) Scale & affine invariant interest point detectors. Int J Comput Vis 60(1):63–86
Over P, Awad G, Michel M, Fiscus J, Sanders G, Shaw B, Kraaij W, Smeaton AF, Quenot G (2012) Trecvid 2012—an overview of the goals, tasks, data, evaluation mechanisms and metrics. In: Proceedings of TRECVID 2012. NIST, USA
Philbin J, Chum O, Isard M, Sivic J, Zisserman A (2007) Object retrieval with large vocabularies and fast spatial matching. In: CVPR
Philbin J, Chum O, Isard M, Sivic J, Zisserman A (2008) Lost in quantization: improving particular object retrieval in large scale image databases. In: CVPR
Poullot S, Buisson O, Crucianu M (2010) Scaling content-based video copy detection to very large databases. Multimed Tools Appl 47(2):279–306
Romberg S, Lienhart R (2013) Bundle min-Hashing. Int J Multimedia Inf Retr 2(4):243–259
Romberg S, Pueyo LG, Lienhart R, van Zwol R (2011) Scalable logo recognition in real-world images. In: ICMR, p 25
Schindler G, Brown M, Szeliski R (2007) City-scale location recognition. In: CVPR
Shewchuk JR (1996) Triangle: engineering a 2d quality mesh generator and Delaunay triangulator. In: WACG, pp 203–222
Sivic J, Zisserman A (2003) Video google: a text retrieval approach to object matching in videos. In: ICCV, pp 1470–1477
Torresani L, Szummer M, Fitzgibbon AW (2010) Efficient object category recognition using classemes. In: ECCV (1), pp 776–789
Wang SY, Liao WS, Hsieh LC, Chen YY, Hsu WH (2012) Learning by expansion: exploiting social media for image classification with few training examples. Neurocomputing 95:117–125
Wang X, Yang M, Cour T, Zhu S, Yu K, Han TX (2011) Contextual weighting for vocabulary tree based image retrieval. In: ICCV, pp 209–216
Wang Z, Fan B, Wu F (2011) Local intensity order pattern for feature description. In: ICCV, pp 603–610
Welzl E, Su P, Drysdale RL III (1997) A comparison of sequential Delaunay triangulation algorithms. Comput Geom 7:361–385
Wu Z, Ke Q, Isard M, Sun J (2009) Bundling features for large scale partial-duplicate web image search. In: CVPR, pp 25–32
Yang Y, Newsam S (2011) Spatial pyramid co-occurrence for image classification. In: ICCV, pp 1465–1472
Zhang W, Pang L, Ngo CW (2012) Snap-and-ask: answering multimodal question by naming visual instance. In: ACM Multimedia, pp 609–618
Zhang Y, Jia Z, Chen T (2011) Image retrieval with geometry-preserving visual phrases. In: CVPR, pp 809–816
Zhu CZ, Satoh S (2012) Large vocabulary quantization for searching instances from videos. In: ICMR, p 52
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wu, X., Kashino, K. Interest point selection by topology coherence for multi-query image retrieval. Multimed Tools Appl 74, 7147–7180 (2015). https://doi.org/10.1007/s11042-014-1957-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-014-1957-7