
Abstract
Retrieving videos with similar actions is an important task with many applications. Yet it is very challenging due to large variations across different videos. While the state-of-the-art approaches generally utilize the bag-of-visual-words representation with the dense trajectory feature, the spatial-temporal context among trajectories is overlooked. In this paper, we propose to incorporate such information into the descriptor coding and trajectory matching stages of the retrieval pipeline. Specifically, to capture the spatial-temporal correlations among trajectories, we develop a descriptor coding method based on the correlation between spatial-temporal and feature aspects of individual trajectories. To deal with the mis-alignments between dense trajectory segments, we develop an offset-aware distance measure for improved trajectory matching. Our comprehensive experimental results on two popular datasets indicate that the proposed method improves the performance of action video retrieval, especially on more dynamic actions with significant movements and cluttered backgrounds.








Similar content being viewed by others
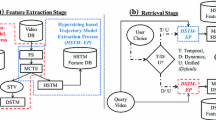
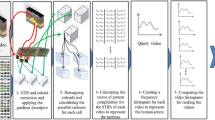

References
Bashir F, Khokhar A, Schonfeld D (2007) Real-time motion trajectory-based indexing and retrieval of video sequences. IEEE Trans Multimed 9(1):58–65. doi:10.1109/TMM.2006.886346
Bregonzio M, Gong S, Xiang T et al (2009) Recognising action as clouds of space-time interest points, IEEE Conference on Computer Vision and Pattern Recognition, 1948–1955. doi:10.1109/CVPR.2009.5206779
Buzan D, Sclaroff S, Kollios G (2004) Extraction and clustering of motion trajectories in video, 2004. ICPR 2004. Proceedings of the 17th International Conference on Pattern Recognition, 2, 521–524. doi:10.1109/ICPR.2004.1334287
Cao L, Ji R, Gao Y, Liu W, Tian Q (2013) Mining spatiotemporal video patterns towards robust action retrieval. Neurocomputing 105:61–69. doi:10.1016/j.neucom.2012.06.044
Cao Y, Wang C, Li Z, Zhang L, Zhang L (2010) Spatial-bag-of-features, IEEE Conference on Computer Vision and Pattern Recognition, 3352–3359. doi:10.1109/CVPR.2010.5540021
Caspi Y, Simakov D, Irani M (2006) Feature-based sequence-to-sequence matching. Int J Comput Vis 68(1):53–64. doi:10.1007/s11263-005-4842-z
Fischler MA, Bolles RC (1981) Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun ACM 24(6):381–395. doi:10.1145/358669.358692
Geronimo D, Kjellstrom H (2014) Unsupervised surveillance video retrieval based on human action and appearance, International Conference on Pattern Recognition, 4630–4635. doi:10.1109/ICPR.2014.792
Hu W, Xie D, Fu Z, Zeng W, Maybank S (2007) Semantic-based surveillance video retrieval. IEEE Trans Image Process 16(4):1168–1181. doi:10.1109/TIP.2006.891352
Jones S, Shao L (2013) Content-based retrieval of human actions from realistic video databases. Inf Sci 236:56–65. doi:10.1016/j.ins.2013.02.018
Keogh EJ, Pazzani MJ (2000) Scaling up dynamic time warping for datamining applications, ACM International Conference on Knowledge Discovery and Data Mining, 285–289, ACM, NY, USA. doi:10.1145/347090.347153
Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T (2011) HMDB: A large video database for human motion recognition, 2011 International Conference on Computer Vision, 2556–2563. doi:10.1109/ICCV.2011.6126543
Laptev I (2005) On space-time interest points. Int J Comput Vis 64(2–3):107–123
Li Q, Qiu Z, Ya T, et al. (2016) Action recognition by learning deep multi-granular spatio-temporal video representation. In: ACM International Conference in Multimedia Retrieval
Li T, Mei T, Kweon IS, Hua XS (2011) Contextual bag-of-words for visual categorization. IEEE Trans Circ Syst Video Technol 21 (4):381–392. doi:10.1109/TCSVT.2010.2041828
Liu AA, Su YT, Nie WZ, Kankanhalli M (2016) Hierarchical clustering multi-task learning for joint human action grouping and recognition, IEEE Trans Pattern Anal Mach Intell, PP, 99. doi:10.1109/TPAMI.2016.2537337
Liu AA, Xu N, Nie WZ, Su YT, Wong Y, Kankanhalli M (2016) Benchmarking a multimodal and multiview and interactive dataset for human action recognition. IEEE Trans Cybern PP(99):1–14. doi:10.1109/TCYB.2016.2582918
Liu L, Shao L, Li X, Lu K (2016) Learning spatio-temporal representations for action recognition: A genetic programming approach. IEEE Trans Cybern 46(1):158–170. doi:10.1109/TCYB.2015.2399172
Liu L, Shao L, Rockett P (2013) Boosted key-frame selection and correlated pyramidal motion-feature representation for human action recognition. Pattern Recogn 46(7):1810–1818. doi:10.1016/j.patcog.2012.10.004
Liu L, Wang L, Liu X (2011) In defense of soft-assignment coding, IEEE International Conference on Computer Vision, 2486–2493. doi:10.1109/ICCV.2011.6126534
Lowe D (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis 60(2):91–110. doi:10.1023/B:VISI.0000029664.99615.94
Lu S, Mei T, Wang J, Zhang J, Wang Z, Li S (2015) Exploratory product image search with circle-to-search interaction. IEEE Trans Circ Syst Video Technol 25 (7):1190–1202. doi:10.1109/TCSVT.2014.2372272
Lu S, Wang Z, Mei T, Guan G, Feng DD (2014) A bag-of-importance model with locality-constrained coding based feature learning for video summarization. IEEE Trans Multimed 16(6):1497–1509. doi:10.1109/TMM.2014.2319778
Lu S, Zhang J, Wang Z, Feng DD (2013) Fast human action classification and VOI localization with enhanced sparse coding. J Vis Commun Image Represent 24 (2):127–136. doi:10.1016/j.jvcir.2012.07.008
Lucas BD, Kanade T (1981) An iterative image registration technique with an application to stereo vision, International Joint Conference on Artificial Intelligence, 674–679
Matikainen P, Hebert M, Sukthankar R (2010) Representing pairwise spatial and temporal relations for action recognition, European Conference on Computer Vision, Lecture Notes in Computer Science, 6311, 508–521, Springer, Berlin Heidelberg Daniilidis K, Maragos P, Paragios N (eds). doi:10.1007/978-3-642-15549-9_37
Meng J, Yuan J, Yang J, Wang G, Tan YP (2016) Object instance search in videos via spatio-temporal trajectory discovery. IEEE Trans Multimed 18 (1):116–127. doi:10.1109/TMM.2015.2500734
Messing R, Pal C, Kautz H (2009) Activity recognition using the velocity histories of tracked keypoints, IEEE International Conference on Computer Vision, 104–111. doi:10.1109/ICCV.2009.5459154
Palou G, Salembier P (2013) Hierarchical video representation with trajectory binary partition tree, IEEE Conference on Computer Vision and Pattern Recognition, 2099–2106. doi:10.1109/CVPR.2013.273
Pan Y, Li Y, Yao T, et al. (2016) Learning Deep Intrinsic Video Representation by Exploring Temporal Coherence and Graph Structure. In: International Joint Conference on Artificial Intelligence
Poullot S, Tsukatani S, Phuong Nguyen A, Jégou H, Satoh S (2015) Temporal matching kernel with explicit feature maps, ACM International Conference on Multimedia, 381–390, ACM, NY, USA. doi:10.1145/2733373.2806228
Revaud J, Douze M, Schmid C, Jégou H (2013) Event retrieval in large video collections with circulant temporal encoding, IEEE Conference on Computer Vision and Pattern Recognition, 2459–2466. doi:10.1109/CVPR.2013.318
Rodriguez MD, Ahmed J, Shah M (2008) Action MACH a spatio-temporal maximum average correlation height filter for action recognition, IEEE Conference on Computer Vision and Pattern Recognition, 1–8. doi:10.1109/CVPR.2008.4587727
Rubner Y, Tomasi C, Guibas LJ (1998) A metric for distributions with applications to image databases, International Conference on Computer Vision, 59–66. doi:10.1109/ICCV.1998.710701
Ryoo MS, Aggarwal JK (2010) UT-Interaction dataset, ICPR contest on semantic description of human activities (SDHA). http://cvrc.ece.utexas.edu/SDHA2010/Human_Interaction.html
Sadanand S, Corso JJ (2012) Action bank: A high-level representation of activity in video, IEEE Conference on Computer Vision and Pattern Recognition, 1234–1241. doi:10.1109/CVPR.2012.6247806
Savarese S, DelPozo A, Niebles JC, Fei-Fei L (2008) Spatial-temporal correlatons for unsupervised action classification, IEEE Workshop on Motion and Video Computing, 1–8, IEEE Computer Society, DC, USA. doi:10.1109/WMVC.2008.4544068
Savarese S, Winn J, Criminisi A (2006) Discriminative object class models of appearance and shape by correlatons, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2033–2040, IEEE Computer Society, DC, USA. doi:10.1109/CVPR.2006.102
Scovanner P, Ali S, Shah M (2007) A 3-dimensional sift descriptor and its application to action recognition, Proceedings of the 15th International Conference on Multimedia, 357–360, ACM, NY, USA. doi:10.1145/1291233.1291311
Shen X, Zhang L, Wang Z, Feng DD (2015) Spatial-temporal correlation for trajectory based action video retrieval, IEEE International Workshop on Multimedia Signal Processing, 1–6. doi:10.1109/MMSP.2015.7340811
Sivic J, Zisserman A (2006) Video Google: Efficient visual search of videos, Toward Category-Level Object Recognition, 127–144, Springer, Berlin Heidelberg. doi:10.1007/11957959_7
Soomro K, Zamir AR, Shah M (2012) UCF101: A dataset of 101 human actions classes from videos in the wild. Technical. Report. CRCV-TR-12-01 University of Central Florida
Sun J, Wu X, Yan S, Cheong LF, Chua TS, Li J (2009) Hierarchical spatio-temporal context modeling for action recognition, IEEE Conference on Computer Vision and Pattern Recognition, 2004–2011. doi:10.1109/CVPR.2009.5206721
Tran D, Bourdev L, Fergus RCB, Torresani L, Paluri M (2015) Learning spatiotemporal features with 3D convolutional networks, IEEE International Conference on Computer Vision, 4489–4497. doi:10.1109/ICCV.2015.510
Wang H, Kläser A, Schmid C, Liu CL (2013) Dense trajectories and motion boundary descriptors for action recognition. Int J Comput Vis 103(1):60–79. doi:10.1007/s11263-012-0594-8
Wang H, Schmid C (2013) Action recognition with improved trajectories, IEEE International Conference on Computer Vision, 3551–3558. doi:10.1109/ICCV.2013.441
Wang J, Yang J, Yu K, Lv F, Huang T, Gong Y (2010) Locality-constrained linear coding for image classification, IEEE Conference on Computer Vision and Pattern Recognition, 3360–3367. doi:10.1109/CVPR.2010.5540018
Wang L, Song D, Elyan E (2012) Improving bag-of-visual-words model with spatial-temporal correlation for video retrieval, ACM International Conference on Information and Knowledge Management, 1303–1312, ACM, NY, USA. 10.1145/2396761.2398433
Wu J, Zhang Y, Lin W (2016) Good practices for learning to recognize actions using FV and VLAD. IEEE Trans Cybern PP(99):1–13. doi:10.1109/TCYB.2015.2493538
Wu Q, Wang Z, Deng F, Xia Y, Kang W, Feng DD (2013) Discriminative two-level feature selection for realistic human action recognition. J Vis Commun Image Represent 24(7):1064–1074. doi:10.1016/j.jvcir.2013.07.001
Wu X, Satoh S (2013) Ultrahigh-speed TV commercial detection, extraction, and matching. IEEE Trans Circ Syst Video Technol 23 (6):1054–1069. doi:10.1109/TCSVT.2013.2248991
Zhang L, Wang Z, Mei T, Feng DD (2016) A scalable approach for content-based image retrieval in peer-to-peer networks. IEEE Transactions on Knowledge and Data Engineering
Zhang S, Tian Q, Hua G, Huang Q, Li S (2009) Descriptive visual words and visual phrases for image applications, ACM International Conference on Multimedia, 75–84, ACM, NY, USA. doi:10.1145/1631272.1631285
Zhen X, Shao L (2016) Action recognition via spatio-temporal local features: A comprehensive study. Image Vis Comput 50:1–13. doi:10.1016/j.imavis.2016.02.006
Zheng J, Feng DD, Zhao RC (2005) Trajectory matching and classification of video moving objects, IEEE Workshop on Multimedia Signal Processing, 1–4. doi:10.1109/MMSP.2005.248553
Zhou Z, Shi F, Wu W (2015) Learning spatial and temporal extents of human actions for action detection. IEEE Trans Multimed 17(4):512–525. doi:10.1109/TMM.2015.2404779
Acknowledgments
This work was partially supported by ARC (Australian Research Council) grants, the National Institute of Informatics, Japan, the China Scholarship Council (201406690011), and the HPC (High Performance Computing) service at the University of Sydney.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, L., Wang, Z., Yao, T. et al. Exploiting spatial-temporal context for trajectory based action video retrieval. Multimed Tools Appl 77, 2057–2081 (2018). https://doi.org/10.1007/s11042-017-4353-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4353-2