
Abstract
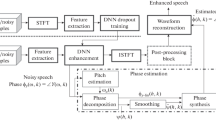
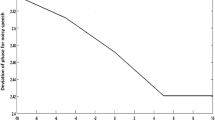
Enhancing reverberant speech with Deep Neural Networks (DNNs) is an interesting yet challenging topic. The performance of speech enhancement degrades significantly when test and training conditions are mismatched. In this paper we propose a Static Reverberation Aware Training (SRAT)-based dereverberation through which the reverberation estimate is obtained by averaging over broken down frame. This method significantly reduces the input dimensions of the and enables the DNN to learn the relations between clean and reverberant speech more efficiently. Most speech enhancement approaches ignore phase information due to its complicated structure. As phase correlates closely to speech signal we exploited this relationship to achieve better performance using DNN. Phase information was augmented with magnitude information and used as the input for DNN. We denote this method as phase aware DNN. Finally, both phase information and reverberation were added to reverberant speech to achieve better speech enhancement performance in a distant-talking condition. Features of the reverberant speech, phase and reverberation were used during the training and testing stages. This is because the DNN could use both reverberation and phase information to better generalize the speech signal. The proposed method was evaluated using the REVERB CHALLENGE 2014 database. Results are significantly improved results with respect to both reconstructed speech quality (PESQ: Perceptual Evaluation of Speech Quality) and influence of reverberation (SRMR: Speech to Reverberation Modulation Energy Ratio). As compared to the conventional DNN-based approach, this proposed one improved SRMR from 4.84 to 5.92 and PESQ from 2.34 to 2.70, indicating that our proposed method could efficiently enhance speech severely corrupted by reverberation.





Similar content being viewed by others
References
Benesty J, Makino S, Chen J (2005) Speech enhancement. Springer, New York
Boll S (1984) Suppression of acoustics noise in speech using spectral subtraction. IEEE Trans on Acoustics, Speech, Signal Processing 32:1109–1121
Ephraim Y, Malah D (1985) Speech enhancement using a minimum mean square error short-time spectral amplitude estimator. IEEE Trans on Acoustics, Speech and Signal Processing 33(2):443–445
Ephraim Y et al (1995) A signal subspace approach for speech enhancement. IEEE Trans on Speech and Audio Processing 3(4):251–266
Hegde RM et al (2007) Significance of the Modified Group Delay Feature in Speech Recognition. IEEE Trans on Audio, Speech, and Language Processing 15(1):190–202
Hinton GE et al (2006) A fast learning algorithm for deep belief Networks. Neural Comput 18:1527–1554
Kanagasundaram A, Dean D, Sridharan S (2012) JFA based speaker recognition using delta-phase and MFCC features. In: Proc. of SST, pp. 9-12
Kinoshita K, Nakatani T (2011) Speech dereverberation using linear prediction. NTT Technical Review 9(7):1–7
Kinoshita K, Delcroix M, Nakatani T, Miyoshi M (2009) Suppression of Late Reverberation Effect on Speech Signal Using Long-Term Multiple–Step Linear Prediction. IEEE trans Audio, Speech and Language Processing 17(4):534–545
Kinoshita K et al (2013) The reverb challenge: a common evaluation framework for dereverberation and recognition of reverberant speech. Proc. of IEEE Workshop on Application of Signal Processing to Audio Acoustics
Lu X, Tsao Y, Matsuda S, Hori C (2013) Speech enhancement based on deep denoising autoencoder. In: Proc. of Interspeech, pp. 436-440
Miao Y et al (2015) Distant aware training for robust speech recognition. Proc. of Interspeech, pp. 761-765
Nakagawa S et al (2012) Speaker Identification and Verification by Combining MFCC and Phase Information. IEEE Trans on Audio, Speech and Language Processing 20(4):1085–1095
Nakatani T, Yoshioka T, Kinoshita K, Miyoshi M, Juang BH (2008) Blind speech dereverberation with multi- channel linear prediction based on short time fourier representation. Proc. of ICASSP, Las Vegas, pp 85–88
Oo Z, Wang L, Masahiro I (2015) Investigation of DNN based Distant-Talking Speech Enhancement. Proc of 109th Spoken Language Research Workshop of IEICE 115(346):37–42
Robinson T, Fransen J, Pye D, Foote J, Renals S (1995) WSJCAM0: a british english speech corpus for large vocabulary continuous speech recognition. Proc. of ICASSP, Detroit, pp 81–84
Seltzer ML, Wang Y (2013) An investigation of deep neural networks for noise robust speech recognition. Proc. of ICASSP, Vancouver, pp 7398–7402
Tchorz J, Kollmeier B (2003) SNR estimation based on amplitude modulation analysis with applications to noise suppression. IEEE Trans on Speech Audio Process 11(3):184–192
Ueda Y, Wang L, Kai A, Ren B (2015) Environmental dependent denoising autoencoder for distant talking speech recognition. Eurasip Journal on Advances in Signal Processing 2015(92):1–11
Wan EA, Nelson T (1998) Handbook of neural network for speech processing. Artech House, Boston
Wang L et al (2010) Speaker recognition by combining MFCC and phase information in noisy conditions. IEICE Trans Inf Syst E93-D 9:2397–2406
Wang L et al (2015) Relative phase information for detection human speech and spoofed speech. In: Proc. of Interspeech, pp. 2092-2096
Xiao X et al (2014) The NTU–ADSC system for reverberation challenge 2014. Proc of Reverb Workshop
Xiao X et al (2016) Speech dereverberation for enhancement and recognition using dynamic features constrained deep neural networks and feature adaptation. EURASIP Journal of Advances in Signal Processing 2016(4):1–18
Xu Y, Du J, Dai L, Lee C (2014) An Experimental Study on Speech on Deep Neural Networks. IEEE Signal Processing Letter 21(1):65–68
Xu Y, Du J, Dai L, Lee C (2014) Dynamic noise aware training for speech enhancement based on deep neural networks. Proc. of Interspeech, pp. 2670–2674
Xu Y, Du J, Dai L, Lee C (2015) “A Regression Approach to Speech Enhancement Based on Deep Neural Networks” IEEE Trans on Audio. Speech and Language Processing 23:7–19
Acknowledgements
The research was supported partially by the National Natural Science Foundation of China (No. 61771333 and No. U1736219) and JSPS KAKENHI Grant (No. 16K12461 and No. 16K00297).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Oo, Z., Wang, L., Phapatanaburi, K. et al. Phase and reverberation aware DNN for distant-talking speech enhancement. Multimed Tools Appl 77, 18865–18880 (2018). https://doi.org/10.1007/s11042-018-5686-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-5686-1