
Abstract
Urban noise recognition play a vital role in city management and safety operation, especially in the recent smart city engineering. Exiting studies on urban noise recognition are mostly based on conventional acoustic features, such as Mel-Frequency Cepstral Coefficients (MFCC) and Linear Prediction Cepstral Coefficients (LPCC), and the shallow structure based classifiers, such as support vector machine (SVM). However, the urban acoustic environment is complicated and changeable. Conventional acoustic representation and recognition methods may be insufficient in characterizing urban noises, and generally suffer from a degraded performance. In this paper, we study the recent deep neural network based urban noise recognition. The log-Mel-spectrogram, namely, the FBank feature is first derived for acoustic representation. Then, the FBank spectrum constructed with a set of FBank feature vectors from multiple acoustic signal frames is fed to a convolutional neural network (CNN) for urban noise recognition. Comprehensive studies on the dimension of FBank spectrums and the parameters in CNN, including the size of learnable kernels, the dropout rate, and the activation function, etc., are presented in the paper. An acoustic database collected in real environment covering 11 most common urban noises with more than 56,000 samples is constructed for model verification and performance evaluation. In addition, the traditional LPCC and MFCC acoustic feature combining with two popular machine learning algorithms, extreme learning machine (ELM) and support vector machine (SVM), and the FBank image feature combining with extreme learning machine (ELM), hierarchical extreme learning machine (H-ELM) and multilayer extreme learning machine (ML-ELM), have also been presented for discussions. Experimental results show that the proposed method generally outperforms conventional shallow structure based classifiers.
Similar content being viewed by others
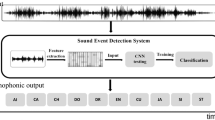


1 Introduction
Urban noise recognition attracts increasing attentions in recent years due to its wide applications in smart city engineering [2, 4, 5, 16, 20, 26,27,28, 32, 38, 41, 43,44,45, 47, 48, 50]. Based on Fourier transform and Back-propagation neural network, the noise pollution problem is investigated in [43]. The urban noise level analysis and measurement on various cities around the world has been studied in [5, 26,27,28, 41, 45, 48], including a noise level survey in C\(\acute {a}\)ceres of Spain [27], the traffic noise evaluation in Beijing [26], the noise pollution and its consequent influence in Curitiba of Brazil [48], etc. Urban traffic noise analysis and control become another popular research topic due to its serious effects on the inhabitants [2, 38, 44, 50]. For example, heavy traffic noises may cause annoyance and sleep disturbance, which may leads to some long-term health effects, such as the cardiovascular disease [38]. An automatic noisy vehicle surveillance camera (NoivelCam) system has been developed in [2] to measure the vehicle noises and a linked camera will be triggered to capture vehicles with high noise exceeding a certain level. Based on virtual noise perception method, the human emotional reaction under various noise pollution levels have been studied and visualized in [20]. Recently, urban noise recognition has been found effective in city security surveillance application, such as the underground pipeline network surveillance [7,8,9, 11, 46], urban traffic surveillance [31], etc. Due to the fast urbanization construction in many developing countries, the underground pipeline network, including water supply and drainage network, gas supply system, underground electric cable, etc., suffered severe external breakages caused by road excavation devices [7,8,9, 11, 46]. Comparing with the conventional surveillance system built on the video/image based excavation device recognition methods [34, 35], the acoustic signal recognition based approaches have shown several merits. For example, the acoustic based surveillance system can work in all day while the video/image based system suffers poor performance in dim light environment [7, 9, 11, 46].
Effective feature representation and classification algorithms are crucial to urban noise recognition. The Linear Prediction Cepstral Coefficients (LPCC), which reflects the linear prediction coefficients (LPC) of acoustic signal in the cepstrum domain [39], has been widely used for acoustic wave characterization. Its improved variants, including one-sided autocorrelation matrix of LPCC [46], the Mel-Frequency Linear Prediction Cepstral Coefficients [12], etc., have been developed for performance enhancement. The Mel-Frequency Cepstral Coefficients (MFCC), which describes the acoustic frequency spectrum in the Mel scale frequency domain [14], has been used as feature for speech recognition [3], music information retrieval, etc. Its first- and second-order dynamic MFCC features have been developed for road excavation devices recognition for underground pipeline system protection [7]. However, when dealing with more complex urban noises with a large number of categories, it is shown in [9] that conventional LPCC and MFCC features are not capable of providing discriminative representations. A novel acoustic statistical feature extracted from the probability density distributions (PDF) of the short frame energy ratio, the concentration of spectrum amplitude, the energy distribution ranges has been developed for road excavation devices and some common urban noises characterization in [9]. A cascade classifier based on the PDFs of statistical features and Bayes detector has then been developed for urban noise and excavation devices recognition. But it is noted that a number of parameters in the Bayes cascade detector require human intervention, which may lead to low recognition accuracy due to its poor generalization ability [9]. In [47], a novel aggregation scheme which merges the local class-dependent temporal-spectral features and global long-term descriptive features is developed for urban sound classification in real-life noise environment. Besides the statistical based detector, traditional machine learning algorithms are frequently adopted for urban noise recognition, such as the support vector machine (SVM) [46, 47] and artificial neural networks (ANN) [12, 14, 16]. Particularly, the popular extreme learning machine (ELM) [6, 10, 13, 21, 49] for ANN has been adopted in urban noise classification for its fast model training speed [7, 9, 12, 14].
Although a number of achievements have been reported for urban noise analysis and recognition, existing literatures are either built on the shallow structure based recognition algorithms with conventional acoustic features or tested on benchmark datasets. In real life, the urban noise environment is complicated and changeable. The traditional shallow structure based learning algorithms are usually insufficient in characterizing such a highly complex acoustic environment and hence suffer a degraded recognition performance. Deep neural networks (DNN) become very hot in image recognition, natural language processing and many other data processing areas in the past several years due to its attractive performance in large scale data characterization [1, 15, 17, 22,23,24,25, 33, 36, 37, 40, 42]. The deep network based on the convolution operation in hidden neurons to capture signal features is first developed for document classification in [25]. Pushed by the large scale ImageNet dataset recognition competition [23], research on deep neural networks then becomes explosive in a number areas related to big data processing as the deeply stacked hidden layers have better characterizing capability than the shallow structure based classifiers.
Thanks to the promising generalization performance of DNN on complex and large scale datasets, we study the convolutional neural network (CNN) based urban noise recognition in this paper. The FBank feature has the superiority in describing both the time- and frequency-domain characteristics. It is noted that the FBank feature was motivated by the nature of the acoustic signal and the human perception of acousrtic signals. In general, the Discrete Cosine Transform (DCT) in MFCC was applied for the filter bank coefficient decorrelation, which is also referred to the whitening process. However, the deep convolutional neural networks are generally less susceptible to highly correlated inputs, indicating that the DCT is no longer a necessary step in CNN based framework. Different to the conventional literatures, which generally test on benchmark datasets [16, 32, 44, 47], we construct an acoustic dataset by collecting the most common noises from real urban environment. The dataset consists of 11 different categories of common urban noises, including the engine noises generated by various road excavation devices (including excavator, electric hammer, cutting machine, hydraulic hammer, and pavement milling machine), wind noise, engine sound of vehicles, alarms of vehicles, sound of high-rating generator, human talking and music. All the urban noises are collected in different propagation distances to the acoustic sources to make the algorithm verification reliable and robust. To emphasize the power distribution diversities on different frequency banks for different urban noises, the power spectrum of urban noise is first derived based on the discrete Fourier transform (DFT). For each frame, the Mel logarithm filters are applied to the power spectrum of urban noises to extract the effective FBank features. Then, a FBank spectrum image consisted of FBank feature vectors extracted from consecutive frames is constructed for urban noise representation. The FBank spectrum images are finally fed to a CNN to build the recognition model. Comprehensive studies on the dimension of FBank spectrums and the effects of parameters in CNN for urban noise recognition, including the size of learnable kernels, the dropout rate, and the activation function, etc., have been presented in the paper. To demonstrate the effectiveness of the proposed urban noise recognition framework, experiments on a real collected dataset consists of more than 56,000 samples are conducted. Extensive comparisons to four popular machine learning algorithms, extreme learning machine (ELM), hierarchical extreme learning machine (H-ELM), multilayer extreme learning machine (ML-ELM) and support vector machine (SVM) training with MFCC feature, LPCC feature and the FBank spectrum are presented in the paper. Experimental results suggest that the proposed CNN combining with FBank spectrum based recognition method outperforms conventional shallow structure based classifiers.
2 Proposed CNN+FBank spectrum based algorithm
The proposed CNN based urban noise recognition with the FBank spectrum feature is presented in this section. Figure 1 describes the general framework of the proposed algorithm, which can be broadly decomposed into three phases: 1) the FBank spectrum image construction stage, 2) the CNN based feature extraction and learning stage, and 3) the final classification stage. In the following subsections, detailed introduction to each stage is given, respectively.

The proposed CNN+FBank spectrum based urban noise recognition framework
2.1 FBank spectrum feature extraction
Urban noise environment is complicate and changeable. There exist numerous categories of noises in the urban city. Meanwhile, the acoustic signals from different categories may have overlaps in the time- or frequency- domain characteristics. It is thus a very challenge task to build a pervasive approach which can adapt to the complex environment. In this paper, we focus on analyzing the most representative urban noises and aim to construct a relatively reliable recognition method.
Figure 2 draws the acoustic waves of 11 representative urban noises we have collected for analysis in this paper. Their corresponding spectrograms are shown in Fig. 3, respectively. The 11 urban acoustic signals are the engine noises generated by five frequently used road excavation devices (including excavator, electric hammer, cutting machine, hydraulic hammer, and pavement milling machine), wind noise, engine sound of vehicles, alarms of vehicles, sound of high-rating generator, human talking and music, which cover most of the urban noises in general. As depicted in Fig. 2, some of them can be hardly identified as they show similar shape of waves in the time domain, for example, alarms, engine sound and noises by cutting machine. Meanwhile, as presented in Fig. 3, some of the urban noises have shown similar distributions in the spectrograms. In view of the above-mentioned issues, we exploits the spectrogram based FBank spectrum image feature with the Mel logarithm filter for urban noise representation in this paper. In the following, the detailed steps on deriving the FBank spectrum are given.

Representative urban noises

The spectrogram of 11 representative urban noises
Given a segment of acoustic signal x(n) collected from the urban environment, the window framing is first applied to obtained short acoustic frames as x1(n),…,xM(n). Here, xm(n) denotes the m-th frame with m = 1,…,M. For each frame, the discrete Fourier transform (DFT) Xm(k) is calculated as
where N is the frame length and k is the index of frequency. Then, for the m-th frame, its logarithmic output energy of the Mel filter bank can be calculated as
where L represents the number of Mel filter banks and Hl(k) is the Mel filter defined as
Here, f(l) is the center frequency of the Mel triangle filter and the Mel frequency has a relation to the original frequency as \(f_{Mel} (f ) = 2595\log \left (1+\frac {f}{700}\right )\). We define sm = [sm(1),…,sm(L)]T as the FBank feature vector of the m-th frame acoustic signal. Finally, for all the M frames of the segment urban acoustic signal, we formulate a FBank spectrum feature by stacking all the FBank feature vectors into a matrix as
It is noted that the FBank spectrum feature f is an L × M matrix, which can not only reflect the Mel filter based spectrogram, but also characterize the dynamic features among consecutive frames. To have a clear description, Fig. 4 shows the flowchart of the proposed FBank image feature extraction method and Fig. 5 draws the FBank images for all the 11 representative urban noises we have recorded for performance evaluation in this paper.

Flowchart of extracting the FBank image feature

FBank images of 11 representative urban noises
2.2 Convolutional neural networks
Convolutional neural networks (CNN) [15, 24] is a popular network architecture in deep learning, which is inspired by the natural visual cognition mechanism of biology. A basic structure of CNN generally consists of two stages, namely the feature learning stage and the classifier training stage. The feature extraction is comprised of one or more convolutional layers and sub-sampling layers. The input to each neuron is connected with the local accepted domain of the previous layer and the feature of local information is then extracted. In this paper, the CNN with two stages of convolution and max pooling layers combining with one fully connected layer is adopted for urban noise recognition, where the FBank images are adopted as inputs feeding to the network.
Figure 6 shows the detailed structure of the CNN used for feature extraction and classifier learning in this paper. Here, the urban noise FBank image with 11 consecutive frames (M = 11) and each frame filtered with 40 Mel filter banks (L = 40) is taken as an example as the network input feature. Two convolution layers with each followed by a max-pooling layer are adopted in the CNN. For the two convolution layers, 256 and 512 kernels are used, respectively. The convolution operation on each layer can be expressed as
where fi− 1 denotes the input image feature to the i-th layer, fi is the obtained feature, g represents the filter used in the convolution, bi is the bias of the i-th layer, and σ(⋅) is the nonlinear activation function. The popular Rectified Linear Unit function (ReLU) [18, 29] is adopted. Figure 7 presents the detailed learnable kernel size and the patch size used for max-pooling in the proposed CNN structure. The learnable kernel size used in convolution is set to be 3 × 3 in this paper. Each learnable kernel detects a particular feature at location region on the input maps. To reduce redundant information and noises, a downsampling operation achieved by max-pooling is implemented in the proposed CNN based urban noise recognition scheme. The patch size used in the max-pooling is 2 × 1. The training algorithm used for CNN is the back-propagation algorithm.

The structure of CNN used for feature extraction and learning

Learnable kernel and activation function in the proposed CNN
3 Experiments and discussions
To verify the effectiveness of the proposed FBank image combining with CNN based urban noise recognition framework, experiments conducted on real collected urban noises of 11 categories are presented in this section. Performance analyses on using different parameters in CNN, including the size of learnable kernels, the dropout rate, and the activation function, etc., are given. Comparisons to the conventional LPCC feature and MFCC feature with extreme learning machine (ELM) and support vector machine (SVM), and the FBank image with ELM H-ELM and ML-ELM are also provided for effectiveness demonstration.
3.1 Dataset description and experimental set-ups
A cross-layer microphone array is designed for urban noise collection in this paper, where the sampling rate is 20 kHz. To closely simulate the urban noise environment, the most representative urban noises belonging to 11 categories are recorded for performance evaluation, including acoustic signal generated by five road excavation devices (namely excavator, electric hammer, cutting machine, hydraulic hammer, and pavement milling machine), the wind noise, the engine sound of passing vehicles, the alarms of vehicles, the sound of high-rating generator, human talking and music. All urban noise signals are collected in real environment with each recorded under various propagation distances to the acoustic source. Table 1 summaries the number of FBank image samples of the urban noises for each category. The used size of FBank image samples listed in Table 1 is 40 × 11, indicating that 11 consecutive acoustic frames are used to construct the FBank image where 40 Mel filter banks are adopted on each frame. It is noted that the number of FBank image samples will be changed when the used consecutive frames for FBank images are changed.
Before calculating the FBank image, a first-order highpass filter for pre-emphasis employed to the urban noises with the pre-emphasis coefficient 0.9375. The frame length is set to be 1024 samples with 50% overlaps in consecutive frames. We test on 3 different dimensions of the FBank images. That is, 3 different numbers of consecutive frames are used to construct the FBank image, which are 8, 11, and 15 frames, respectively.
For the CNN, two convolution layers with each following a sub-sampling layer have been used for feature learning. In the convolution layer, the 3 × 3 learnable kernel is used and in the sub-sampling layer, the non-overlapping of max-pooling is employed where the stride is set to be 1. The ReLU is adopted as the activation function and the categorical cross-entropy between the estimated outputs and the targets is used as loss function in parameter learning. The stochastic gradient descent (SGD) [25] is employed for model training, where the parameters of SGD are set as: the maximum iteration epochs 30, the momentum 0.8, the initial learning rate 0.01, the step size 0.01 for learning rate after 5 epochs, and the weight decay 1e-5 (lambda corresponds to L2 norm regularization).
3.2 Performance on CNN kernel sizes
The urban noise recognition performance using the proposed CNN combining with FBank image on different kernel sizes is tested in this section. Five different kernel size combinations are tested, where we change the number of kernels of the first and second convolutional layers as {64/128,64/512,128/256,128/512,256/512} in the proposed CNN, respectively. To reflect the affections of learnable kernels, the size of FBank image of the urban noise is fixed to 40 × 11 in this experiment. The parameters used in CNN are followed the set-ups given in Section 3.1.
Table 2 lists the average recognition accuracy on each urban noise category with the five different learnable kernel size combinations in CNN. As shown in the table, the proposed CNN with the FBank image offers good recognition performance on various learnable kernel sizes. For all categories and all testing kernel sizes, the lowest recognition accuracy is 85.54. The highest accuracy is highlighted with the boldface. Noted that the CNN structure with the most learnable kernels in both two convolutional layers achieves the best recognition performance in general. But it is also worthy pointing out that comparing with other structures, the increments on recognition rate are small.
3.3 Performance on FBank image sizes
Besides the testing on the CNN structure, the performance of the FBank image size on urban noise recognition is also studied in this subsection. Three different FBank image sizes by changing the number of consecutive frames to 8, 11, and 15, respectively, are investigated. The number of Mel filters is set to be 40 for all three cases, and hence the FBank image sizes are 40 × 8, 40 × 11, and 40 × 15, respectively. To have a fair comparison, the CNN with the same structure is used where the kernel sizes used in the first and second convolutional layers are 256 and 512, respectively. The same network parameters in Section 3.1 are used in CNN.
The average recognition rate for each category on three different FBank image sizes is plotted in Fig. 8. As depicted in the figure, the FBank image constructed using 11 consecutive acoustic frames provides the highest urban noise recognition rate. Besides electric hammer, hydralic hammer and cutting machine, the affections of acoustic frames to the recognition rate are small.

The recognition rate of 11 categories acoustic signals with various window size
3.4 Performance on dropout rate
The dropout rate in CNN prevents the over-fitting issue during the training process by randomly drop units along with their connections from the neural network [42]. In general, the dropout layer is employed after the max-pooling layer in CNN. To test the urban noise recognition performance on the dropout rate in CNN, we compare the urban noise recognition performance on 6 combinations of dropout rates used in the first and second layers. In addition, the performance obtained by CNN with no dropout is also included for comparison. The detailed dropout rate values and their associated average recognition rates are given in Table 3. For each category, the highest recognition rate is highlighted in boldface. As shown in the table, using the dropout rates 0.1/0.5 in CNN wins the best performance in 3 urban noise categories and for the three cases by employing the dropout rates 0.01/0.25, 0.25/0.5 and no dropout rate, each provides the highest recognition rate in 2 urban noise categories. The remaining two dropout rates 0.01/0.1 and 0.01/0.5 both achieve the best performance in 1 urban noise category. Overall, one can find that the affections of changing the dropout rates are small to the urban noise recognition.
3.5 Performance on activation function
The activation function in CNN affects the convergence speed and network performance. The conventional neural network usually employs the Sigmoid or Hyperbolic tangent (tanh) activation function. But they were found suffering the saturated region issue during the network parameter training, which leads to the gradient disappearance during error propagation. The Rectifier Linear Units (ReLU) function is proposed to address the gradient disappearance issue in conventional activation function [29]. A lot of variants to ReLU function has been developed in the past for performance improvement. In this experiment, we study the urban noise recognition performance on the parametric ReLU activation function (PReLU) [18]. The PReLU function introduces the coefficient of leakage into a parameter that is learned along with the other neural network parameters, where the function is expressed as
Here, α is the slope value chosen from (0,1).
To study the performance on different slope values of the PReLU function in CNN, we conduct the experiment by using 7 slope values as {0,0.01,0.05,0.1,0.2,0.3,0.4}, respectively. The urban noise dataset with the 40 × 11 FBank image size is adopted. It is noted that when α = 0, it is equivalent to the basic ReLU function. Table 4 lists the average recognition rate on the 7 slope values. It is found that the basic ReLU function is not the best in urban noise recognition. For PReLU, it generally achieves the overall highest recognition rates for 11 urban noise categories when α is around 0.1 and 0.2. It is known that too small slope in PReLU has a close performance to the tradition ReLU function as few input neural of negative value is activated. Meanwhile, a large slope leads the PReLU closed to a linear function, which may not be effective in exploiting the nonlinear feature of the inputs.
3.6 Performance comparison with state-of-the-art methods
To show the good generalization performance for urban noise recognition using the proposed CNN combining with the FBank image, performance comparisons to the popular LPCC, MFCC acoustic feature and the FBank image feature with two machine learning algorithms SVM [30] and ELM [21], and the FBank image feature with two deep layer based ELM algorithms that H-ELM and ML-ELM, are provided in this subsection. The same acoustic LPCC and MFCC features used to construct the FBank image for CNN are adopted for SVM and ELM, where the whole LPCC feature dataset includes 438598 samples for all 11 categories, and MFCC feature dataset includes 550000 samples for all 11 categories. For CNN, the FBank image dataset with the size 40 × 11 is used. To adaptive to the shallow structure based classifier, the FBank image is reformulated as a long feature vector by concatenating the image along the columns. For SVM, the radial basis function (RBF) is adopted as the kernel function, where the cost parameter C and the kernel parameter g are searched within a grid formed by C = [212,211,...,2− 2] and g = [24,23,...,2− 10] [19] and then the optimal parameters with the highest recognition rate are used. For ELM, the Sigmoid function is used as the activation function and the number of hidden nodes is optimized from 100 to 5000 where the one with the best performance is reported. For H-ELM, the linear function and Sigmoid function are used as the activation function in the AE and classifier layers, respectively. The number of hidden nodes of AE and ELM classifier of H-ELM are optimized from 2000 to 4000, 500 to 5000 respectively, where the one with the best performance is reported. For ML-ELM, the Sigmoid function is used as the activation of AE and ELM classifier. Two hidden layers of AEs are used in ML-ELM, where the number of hidden nodes of first AE is optimized from 100 to 5000, and the number of the hidden nodes of the second AE is optimized from 100 to 2000.
Table 5 shows the urban noise recognition rate comparisons on LPCC+SVM, LPCC+ELM, MFCC+SVM, MFCC+ELM, FBank+ELM, FBank+H-ELM, FBank+ML-ELM and the proposed FBank+CNN framework. Among the 11 urban noise categories, one can find that the MFCC feature based methods (MFCC+SVM and MFCC+ELM) perform poorly in 6 categories. They fail in recognizing the excavator, cutting machine, and hydraulic hammer as the lowest recognition rate is only around 12%. To diagnosis the reason of the poor performance, the confusion matrix of MFCC+SVM and MFCC+ELM on the three categories are plotted in Fig. 9. As shown in Fig. 9a, with the MFCC+SVM algorithm, the excavator has been wrongly recognized as engine sound, hydraulic hammer and milling machine with rates 17.13%, 10.39%, and 12.36%, respectively. The hydraulic hammer has been wrongly recognized as excavator and engine sound with rates 9.66% and 16.13%, respectively. The cutting machine has been wrongly recognized as excavator, electric hammer, engine sound and talking with rates 23.13%, 16.11%, 17.52% and 17.30%, respectively. For the MFCC+ELM algorithm, the wrong recognition rates of the confusion matrix is also shown in Fig. 9b. The poor recognition performance of SVM and ELM is because of the less discriminative capability of the MFCC features in characterizing the urban noise acoustic signals. For illustration, the comparison on the MFCC features of the most wrongly recognized 8 urban noise categories are drawn in Fig. 10. For each category, the 12-order MFCC features of 200 acoustic frames are depicted. One can readily find that the excavator has a close distributions on the MFCC features to the engine sound and milling machine. Similar observations can also be found for the hydraulic hammer and cutting machine in the figure. Comparing with the MFCC feature, employing the FBank feature in ELM obviously improves the recognition performance. From the table, we can find that the proposed FBank+CNN wins the best performance on 6 out of 11 categories of urban noises, while for the rest 5 categories, it performs closely to the best algorithm. Hence, in general, the proposed FBank+CNN based algorithm is effective in urban noise recognition.

Confusion matrices of a MFCC+SVM and b MFCC+ELM

Comparison on the MFCC features on 8 urban noise categories
4 Conclusions
Urban noise recognition play vital roles in the recent smart city engineering. In this paper, we have investigated the recent deep neural network based urban noise recognition. A FBank feature based on the log-Mel-spectrogram of urban noise has been constructed and the FBank spectrum consisting of a series of FBank features from multiple frames has been developed for acoustic signal representation. A convolutional neural network (CNN) trained with the FBank image feature has been then proposed for urban noise recognition. Comprehensive studies on the dimension of FBank spectrums and the effects of parameters in CNN for urban noise recognition, including the size of learnable kernels, the dropout rate, and the activation function, etc., have been presented in the paper. Performance comparisons to the traditional LPCC and MFCC acoustic feature combining with two popular machine learning algorithms, extreme learning machine (ELM) and support vector machine (SVM), as well as FBank image feature combining with two deep layer based ELM algorithms that H-ELM and ML-ELM have also been presented. Experimental results have demonstrated that the proposed CNN combining with FBank image outperforms the conventional shallow structure based classifiers.
References
Abdel-Hamid O, Mohamed AR et al. (2014) Convolutional neural networks for speech recognition. IEEE-ACM Trans Audio Speech Language Process 22(10):1533–1545
Agha A, Ranjan R, Gan WS (2016) Noisy vehicle surveillance camera: A system to deter noisy vehicle in smart city. Appl Acoust 117:236–245
Ahmad K, Thosarz A, Jagannath H (2015) A unique approach in text independent speaker recognition using MFCC feature sets and probabilistic neural network. In: IEEE eighth international conference on advances in pattern recognition, pp 1–6
Asensio C (2017) Acoustics in Smart Cities. Appl Acoust 117:191–192
Calixto A, Diniz FB, Zannin PHT (2003) The statistical modeling of road traffic noise in an urban setting. Cities 20(1):23–29
Cao J, Chen T, Fan J (2016) Landmark recognition with compact BoW histogram and ensemble ELM. Multimed Tools Appl 75(5):2839–2857
Cao J, Huang W, Zhao T, Wang J, Wang R (2017) An enhance excavation equipments classification algorithm based on acoustic spectrum dynamic feature. Multidim Syst Sign Process 28(3):921–943
Cao J, Shang L, Wang J, Vong C, Yin C, Cheng Y, Huang X (2017) A novel distance estimation algorithm for periodic surface vibrations based on frequency band energy percentage feature. Mechanical Systems and Signal Processing. https://doi.org/10.1016/j.ymssp.2017.10.016
Cao J, Wang W, Wang J, Wang R (2017) Excavation equipment recognition based on novel acoustic statistical Features. IEEE Trans Cybern 47(12):4392–4404
Cao J, Zhang K, Luo M, Yin C, Lai X (2016) Extreme learning machine and adaptive sparse representation for image classification. Neural Netw 81:91–102
Cao J, Zhao T, Wang W, Wang J, Wang R (2017) Excavation equipments classification based on improved MFCC features and ELM. Neurocomputing 261:231–241
Cao M, Wang J, Cao J, Zeng H (2017) Acoustics recognition of excavation equipment based on MF-PLPCC features and RELM. In: Proceedings of the 36th Chinese control conference, pp 5400–5404
Chutani S, Goyal A (2017) Improved universal quantitative steganalysis in spatial domain using ELM ensemble. Multimedia Tools and Applications. https://doi.org/10.1007/s11042-017-4656-3
Davis B, Mermelstein P (1980) Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans Acoust Speech Signal Process 28(4):357–366
Deng L, Yu D (2014) Deep learning: Methods and applications. Found Trends Signal Process 7(3-4):197–387
Fernández LPS, Fernández XLAS, Hernández JJC et al. (2015) Methods of analysis for urban environmental noise. In: IEEE Sai intelligent systems conference, pp 381–389
Han Y, Kim J, Lee K (2017) Deep convolutional neural networks for predominant instrument recognition in polyphonic music. IEEE/ACM Trans Audio Speech Language Process 25(1):208–221
He K, Zhang X, Ren S, Sun J (2015) Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: Proceedings of IEEE international conference on computer vision (ICCV), pp 1026–1034
Hsu CW, Lin CJ (2002) A comparison of methods for multiclass support vector machines. IEEE Trans Neural Netw 13(2):415–425
Huang B, Pan Z, Zhang B (2015) A virtual perception method for urban noise: The calculation of noise annoyance threshold and facial emotion expression in the virtual noise scene. Appl Acoust 99:125–134
Huang G-B, Zhu Q-Y, Siew C-K (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1-3):489–501
Huang Y, Yu D, Liu C, Gong Y (2014) A comparative analytic study on the gaussian mixture and context dependent deep neural network hidden Markov models, Interspeech
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 60(2):1097–1105
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521 (7553):436–444
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. In: Proceedings of the IEEE, pp 2278–2324
Li B, Tao S, Dawson RW (2002) Evalution and analysis of traffic noise from the main urban roads in Beijing. Appl Acoust 63(10):1137–1142
Morillas JMB, Escobar VG, Sierra JAM et al. (2002) An environmental noise study in the city of Cáceres. Spain Appl. Acoust. 63(10):1061–1070
Mydlarz C, Salamon J, Bello JP (2016) The implementation of low-cost urban acoustic monitoring devices. Appl Acoust 117:207–218
Nair V, Hinton G (2010) Rectified linear units improve restricted boltzmann machines. In: ICML, 2010, pp 807–814
Nan S, Sun L, Chen B, Lin Z, Toh K-A (2017) Density-dependent quantized least squares support vector machine for large data sets. IEEE Trans Neural Netw Learn Syst 28(1):94–106
Ntalampiras S (2014) Universal background modeling for acoustic surveillance of urban traffic. Digital Signal Process 31:69–78
Piczak KJ (2015) Environmental sound classification with convoltional neural networks. In: IEEE international workshop on machine learning for signal processing, pp 1–6
Qian Y et al. (2016) Very deep convolutional neural networks for noise robust speech recognition. IEEE/ACM Trans Audio Speech Language Process 24(12):2263–2276
Rezazadeh Azar E, McCabe B (2011) Vision-based equipment detection in construction images.. In: The 3rd international/9th construction specialty conference, Ottawa ON, Canada, Accepted
Rezazadeh Azar E, McCabe B (2012) Part based model and spatialtemporal reasoning to recognize hydraulic excavators in construction images and videos. Autom Constr 24(7):194–202
Sainath TN, Kingsbury B, Saon G, Soltau H et al. (2015) Deep convolutional neural networks for large-scale speech tasks. Neural Netw 64:39–48
Sak H, Senior A, Beaufays F (2014) Long short-term memory recurrent neural network architectures for large scale acoustic modeling. Computer Science, pp 338–342
Salomons EM, Pont MB (2012) Urban traffic noise and the relation to urban desity, form, and traffic elasticity. Landsc Urban Plan 108(1):2–16
Schroeder M (1985) Linear predictive coding of speech: review and current directions. IEEE Commun Mag 23(8):54–61
Sermanet P, Chintala S, LeCun Y (2012) Convolutional neural networks applied to house numbers digit classification. In: IEEE international conference on pattern recognition, pp 3288–3291
Souza LCLD, Giunta MB (2011) Urban indices as environmental noise indicators. Comput Environ Urban Syst 35(5):421–430
Srivastava N, Hinton G, Krizhevsky A et al. (2014) Dropout: A simple way to prevent neural networks from overfitting. J Mach Learn Res 15(1):1929–1958
Stoeckle S, Path N, Kumar DK et al. (2001) Environmental sound sources classification using neural networks. In: IEEE intelligent information systems conference, the 7th Australian and New Zealand, pp 399–403
Torija AJ, Ruiz DP (2016) Automated classification of urban locations for environmental noise impact assessment on the basis of road-traffic content. Expert Syst Appl 53:1–13
Tsai KT, Lin MD, Chen YH (2009) Noise mapping in urban environments: A Taiwan study. Appl Acoust 70(7):964–972
Yang S, Cao J, Wang J, Wang R (2016) Linear prediction of one-sided autocorrelation sequence for noisy acoustics recognition of excavation equipment. In: 12th world congress on intelligent control and automation, pp 924–928
Ye J, Kobayashi T, Murakawa M (2016) Urban sound event classification based on local and global features aggregation. Appl Acoust 117:246–256
Zannin PHT, Calixto A, Diniz FB et al. (2003) A survey of urban noise annoyance in a large Brazilian city: the importance of a subjective analysis in conjunction with an objective analysis. Environ Impact Assess Rev 23(2):245–255
Zhang Y, Zhao G, Sun J et al. (2017) Smart pathological brain detection by synthetic minority oversampling technique, extreme learning machine, and Jaya algorithm, Multimedia Tools and Applications. https://doi.org/10.1007/s11042-017-5023-0
Zhao J, Zhang X, Chen Y (2012) A novel traffic-noise prediction method for nonstraight roads. Appl Acoust 73(3):276–280
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by the National Natural Science Foundation of China (61503104, U1509205) and Hangzhou Smart City Research Center of Zhejiang/Zhejiang Smart City Regional Collaborative Innovation Center (GK150906299001/019).
Rights and permissions
About this article

Cite this article
Cao, J., Cao, M., Wang, J. et al. Urban noise recognition with convolutional neural network. Multimed Tools Appl 78, 29021–29041 (2019). https://doi.org/10.1007/s11042-018-6295-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-6295-8