
Abstract
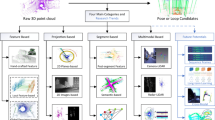
Recovering a 3D human-pose in the form of an abstracted skeleton from a 2D image suffers from loss of depth information. Assuming the projected human-pose is represented by a set of 2D landmarks capturing the human-pose limbs, recovering back the original 3D locations is an ill posed problem. To recover a 3D configuration, camera localization in 3D space plays a major role, an inaccurate camera localization might mislead the recovery process. In this paper, we propose a 3D camera localization model using only human-pose appearance in a 2D image (i.e., the set of 2D landmarks). We apply a supervised multi-class logistic regression to assign the camera location in 3D space. In the learning process, we assume a set of predefined labeled camera locations. The features we train consist of relative length of limbs and 2D shape context. The goal is to build a relation between these projected landmarks and the camera location in 3D space. This kind of analysis allows us to reconstruct 3D human-poses based on the 2D projection only without any predefined camera parameters. Also, makes real-time multimedia exchange more reliable specially for human-pose related tasks. We test our model on a set of real images showing a variety of camera locations.













Similar content being viewed by others


Change history
28 November 2018
The author regrets that the acknowledgment was left out from the original publication.
References
Akhter I, Black MJ (2015) Pose-conditioned joint angle limits for 3D human pose reconstruction. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1446–1455
Al-Badarneh A, Khalil M, Al-Hami M (2008) Improving protein 3D structure prediction accuracy using dense regions areas of secondary structures in the contact map. Am J Biochem Biotechnol 4(4):375–384
Al-Hami M (2016) Towards a better pose understanding for humanoid robots. PhD thesis, Temple University Libraries
Al-Hami M, Khreishah A, Wu J (2013) Video streaming over wireless lan with network coding
Al-Hami M, Lakaemper R (2014) Sitting pose generation using genetic algorithm for nao humanoid robots. In: 2014 IEEE workshop on Advanced robotics and its social impacts (ARSO), IEEE, pp 137–142
Al-Hami M, Lakaemper R (2015) Towards human pose semantic synthesis in 3D based on query keywords. In: Scitepress
Al-Hami M, Lakaemper R (2015) Towards human pose semantic synthesis in 3D based on query keywords. In: VISAPP (3), pp 420–427
Al-Hami M, Lakaemper R (2017) Reconstructing 3D human poses from keyword based image database query. In: 2017 International Conference on 3D vision (3DV), IEEE, pp 440–448
Awad G, Le DD, Ngo CW, Nguyen VT, Quénot G, Snoek C, Satoh S (2017) Video indexing, search, detection, and description with focus on trecvid. In: Proceedings of the 2017 ACM on international conference on multimedia retrieval, ACM, pp 3–4
Belongie S, Malik J, Puzicha J (2002) Shape matching and object recognition using shape contexts. IEEE Trans Pattern Anal Mach Intell 24(4):509–522
Carreira J, Agrawal P, Fragkiadaki K, Malik J (2016) Human pose estimation with iterative error feedback. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4733–4742
Chen CH, Ramanan D (2017) 3D human pose estimation= 2D pose estimation+ matching. In: CVPR. Volume 2, p 6
Ferrari V, Marin-Jimenez M, Zisserman A (2008) Progressive search space reduction for human pose estimation. In: IEEE conference on Computer Vision and Pattern Recognition (CVPR), 2008, IEEE, pp 1–8
Gavrila D (2000) Pedestrian detection from a moving vehicle. In: Computer Vision ECCV 2000. Springer, pp 37–49
Gross R, Shi J (2001) The cmu motion of body (mobo) database
Jokinen K, Wilcock G (2014) Multimodal open-domain conversations with the nao robot. In: Natural interaction with Robots, Knowbots and Smartphones. Springer, pp 213–224
Lakaemper R KinectTCP documentation. https://sites.google.com/a/temple.edu/kinecttcp/ Accessed: 2018-08-8
Lan X, Huttenlocher DP (2004) A unified spatio-temporal articulated model for tracking. In: IEEE computer society conference on Computer Vision and Pattern Recognition (CVPR), 2004. Volume 1, IEEE, pp I–722
Lan X, Huttenlocher DP (2005) Beyond trees: Common-factor models for 2D human pose recovery. In: Tenth IEEE international Conference on Computer Vision (ICCV), 2005. Volume 1, IEEE, pp 470–477
Lin CJ, Weng RC, Keerthi SS (2008) Trust region newton method for logistic regression. J Mach Learn Res 9:627–650
Mehta D, Sridhar S, Sotnychenko O, Rhodin H, Shafiei M, Seidel HP, Xu W, Casas D, Theobalt C (2017) Vnect: Real-time 3D human pose estimation with a single rgb camera. ACM Transactions on Graphics (TOG) 36(4):44
Mousas C, Anagnostopoulos CN (2017) Performance-driven hybrid full-body character control for navigation and interaction in virtual environments. 3D Res 8(2):18
Newell A, Yang K, Deng J (2016) Stacked hourglass networks for human pose estimation. In: European conference on computer vision, Springer, pp 483–499
Ramakrishna V, Kanade T, Sheikh Y (2012) Reconstructing 3D human pose from 2D image landmarks, pp 573–586
Ramanan D (2006) Learning to parse images of articulated bodies. In: Advances in neural information processing systems, pp 1129–1136
Rennie JD (2005) Regularized logistic regression is strictly convex. Unpublished manuscript. people.csail.mit.edu/jrennie/writing/convexLR.pdf
Sapp B, Taskar B (2013) Modec: Multimodal decomposable models for human pose estimation. In: IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2013, IEEE, pp 3674–3681
Schönemann P (1966) A generalized solution of the orthogonal procrustes problem. Psychometrika 31(1):1–10
Sharma D, Lakhmi J, Favorskaya M, Howlett RJ (2015) Fusion of smart, multimedia and computer gaming technologies. Volume 1. Springer, Berlin
Taylor CJ (2000) Reconstruction of articulated objects from point correspondences in a single uncalibrated image. In: IEEE conference on Computer Vision and Pattern Recognition (CVPR), 2000. Volume 1, IEEE, pp 677–684
The vicon skeleton template. http://mocap.cs.cmu.edu/info.php Accessed: 2016-1-15
Varadarajan J, Subramanian R, Bulò SR, Ahuja N, Lanz O, Ricci E (2018) Joint estimation of human pose and conversational groups from social scenes. Int J Comput Vis 126(2-4):410–429
Wang C, Wang Y, Lin Z, Yuille AL, Gao W (2014) Robust estimation of 3D human poses from a single image. In: 2014 IEEE conference on Computer vision and pattern recognition (CVPR), IEEE, pp 2369–2376
Yang W, Ouyang W, Li H, Wang X (2016) End-to-end learning of deformable mixture of parts and deep convolutional neural networks for human pose estimation, pp 3073–3082
Zhang Z (2012) Microsoft kinect sensor and its effect. IEEE Multimedia 19 (2):4–10
Zhou X, Zhu M, Leonardos S, Derpanis KG, Daniilidis K (2016) Sparseness meets deepness: 3D human pose estimation from monocular video. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4966–4975
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Al-Hami, M., Lakaemper, R., Rawashdeh, M. et al. Camera localization for a human-pose in 3D space using a single 2D human-pose image with landmarks: a multimedia social network emerging demand. Multimed Tools Appl 78, 3587–3608 (2019). https://doi.org/10.1007/s11042-018-6789-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-6789-4