
Abstract
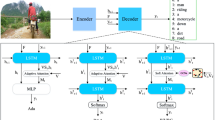
Generating semantic descriptions for images becomes more and more prevalent in recent years. Sentence which contains objects with their attributes and activity or scene involved is more informative and able to express more details of image semantic. In this paper, we focus on the generation of descriptions for images from the structural words we have generated, i.e., a semantically-layered structural tetrad of <object, attribute, activity, scene>. We propose to use deep machine translation method to generate semantically meaningful descriptions. In particular, the generated sentences describe objects with attributes, such as color, size, and corresponding activities or scenes involved. We propose to use a multi-task learning method to recognize structural words. Taking the words sequence as source language, we train a LSTM encoder-decoder machine translation model to output the target caption. In order to demonstrate the effectiveness of using multi-task learning method to generate structural words, we do experiments on benchmark datasets, i.e., aPascal and aYahoo. We also use UIUC Pascal, Flickr8k, Flickr30k, and MSCOCO datasets to justify that translating structural words to sentences achieves promising performance compared to the state-of-the-art methods of image captioning in terms of language generation metrics.









Similar content being viewed by others


References
Aditya S, Yang Y, Baral C, Fermuller C, Aloimonos Y (2015) From images to sentences through scene description graphs using commonsense reasoning and knowledge. arXiv:151103292
Aneja J, Deshpande A (2018) Convolutional image captioning. In: CVPR
Baldridge J (2005) The opennlp project. http://opennlpapacheorg/indexhtml. Accessed 2 Feb 2012
Banerjee S, Lavie A (2005) Meteor: an automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization
Chen L, Zhang H, Xiao J, Nie L, Shao J, Liu W, Chua TS (2017) Sca-cnn: spatial and channel-wise attention in convolutional networks for image captioning. In: CVPR
Cheng G, Zhou P, Han J (2017) Duplex metric learning for image set classification. IEEE Trans Image Process PP(99):1–1
Cheng G, Yang C, Yao X, Guo L, Han J (2018) When deep learning meets metric learning: remote sensing image scene classification via learning discriminative cnns. IEEE Trans Geoscience Remote Sens 56(5):2811–2821
Cho K, van Merriënboer B, Bahdanau D, Bengio Y (2014) On the properties of neural machine translation: encoder–decoder approaches. Syntax, Semantics and Structure in Statistical Translation
Cho K, van Merrienboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using rnn encoder–decoder for statistical machine translation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). Association for Computational Linguistics
Cho K, Courville A, Bengio Y (2015) Describing multimedia content using attention-based encoder-decoder networks. IEEE Trans Multimedia 17(11):1875–1886
Cui H, Zhu L, Cui C, Nie X, Zhang H (2018) Efficient weakly-supervised discrete hashing for large-scale social image retrieval. Pattern Recognition Letters. https://doi.org/10.1016/j.patrec.2018.08.033
Devlin J, Cheng H, Fang H, Gupta S, Deng L, He X, Zweig G, Mitchell M (2015) Language models for image captioning: the quirks and what works. arXiv:150501809
Donahue J, Anne Hendricks L, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T (2015) Long-term recurrent convolutional networks for visual recognition and description. In: CVPR
Fang H, Gupta S, Iandola F, Srivastava R K, Deng L, Dollár P, Gao J, He X, Mitchell M, Platt J C et al (2015) From captions to visual concepts and back. In: CVPR
Farhadi A, Endres I, Hoiem D, Forsyth D (2009) Describing objects by their attributes. In: CVPR
Farhadi A, Hejrati M, Sadeghi M, Young P, Rashtchian C, Hockenmaier J, Forsyth D (2010) Every picture tells a story: generating sentences from images. In: Computer Vision–ECCV
Fawcett T (2006) An introduction to roc analysis. Pattern Recognit Lett 27(8):861–874
Gong Y, Wang L, Hodosh M, Hockenmaier J, Lazebnik S (2014) Improving image-sentence embeddings using large weakly annotated photo collections. In: Computer Vision–ECCV 2014, Springer
Guo J M, Prasetyo H, Chen JH (2015) Content-based image retrieval using error diffusion block truncation coding features. IEEE Trans Circuits Syst Video Technol 25 (3):466–481
Han J, Zhang D, Cheng G, Liu N, Xu D (2018) Advanced deep-learning techniques for salient and category-specific object detection: a survey. IEEE Sign Process Mag 35(1):84–100
Han Y, Li G (2015) Describing images with hierarchical concepts and object class localization. In: Proceedings of the 5th ACM on international conference on multimedia retrieval. ACM
Hendricks LA, Venugopalan S, Rohrbach M, Mooney R, Saenko K, Darrell T (2015) Deep compositional captioning: Describing novel object categories without paired training data. In: CVPR. IEEE
Hodosh M, Young P, Hockenmaier J (2013) Framing image description as a ranking task: data, models and evaluation metrics. J Artif Intell Res 47:853–899
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T (2014) Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the ACM international conference on multimedia. ACM
Jing P, Su Y, Nie L, Gu H, Liu J, Wang M (2018) A framework of joint low-rank and sparse regression for image memorability prediction. IEEE Transactions on Circuits and Systems for Video Technology. https://doi.org/10.1109/TCSVT.2018.2832095
Johnson J, Krishna R, Stark M, Li LJ, Shamma DA, Bernstein MS, Fei-Fei L (2015) Image retrieval using scene graphs. In: CVPR. IEEE
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: CVPR
Kiros R, Salakhutdinov R, Zemel R (2014) Multimodal neural language models. In: Proceedings of the 31st international conference on machine learning (ICML-14)
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems
Kulkarni G, Premraj V, Dhar S, Li S, Choi Y, Berg A C, Berg T L (2011) Baby talk: Understanding and generating simple image descriptions. In: CVPR
Lampert CH, Nickisch H, Harmeling S (2009) Learning to detect unseen object classes by between-class attribute transfer. In: CVPR
Li J, Wu Y, Zhao J, Lu K (2016) Multi-manifold sparse graph embedding for multi-modal image classification. Neurocomputing 173(Part 3):501–510
Li J, Yue W, Zhao J, Ke L (2016) Low-rank discriminant embedding for multiview learning. IEEE Trans Cybern 47(11):3516–3529
Li J, Zhao J, Lu K (2016) Joint feature selection and structure preservation for domain adaptation. In: Proceedings of the twenty-fifth international joint conference on artificial intelligence. AAAI Press
Lin CY, Och FJ (2004) Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In: Proceedings of the 42nd annual meeting on association for computational linguistics, association for computational linguistics
Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: Common objects in context. In: European conference on computer vision. Springer
Liu X, Xu Q, Chau T, Mu Y, Zhu L, Yan S (2018) Revisiting jump-diffusion process for visual tracking: a reinforcement learning approach. IEEE Transactions on Circuits and Systems for Video Technology. https://doi.org/10.1109/TCSVT.2018.2862891
Liu X, Xu Y, Zhu L, Mu Y (2018) A stochastic attribute grammar for robust cross-view human tracking. IEEE Trans Circuits Syst Video Technol 28(10):2884–2895
Lu X, Zhu L, Cheng Z, Song X, Zhang H (2019) Efficient discrete latent semantic hashing for scalable cross-modal retrieval. Signal Process 154:217–231. https://doi.org/10.1016/j.sigpro.2018.09.007
Ma Z, Nie F, Yang Y, Uijlings JR, Sebe N (2012) Web image annotation via subspace-sparsity collaborated feature selection. IEEE Trans Multimedia 14(4):1021–1030
Ma Z, Yang Y, Cai Y, Sebe N, Hauptmann AG (2012) Knowledge adaptation for ad hoc multimedia event detection with few exemplars. In: Proceedings of the 20th ACM international conference on multimedia. ACM
Mao J, Xu W, Yang Y, Wang J, Yuille AL (2014) Explain images with multimodal recurrent neural networks. NIPS Deep Learning Workshop
Mekhalfi ML, Melgani F, Bazi Y, Alajlan N (2015) A compressive sensing approach to describe indoor scenes for blind people. IEEE Trans Circuits Syst Video Technol 25(7):1246–1257
Mitchell M, Han X, Dodge J, Mensch A, Goyal A, Berg A, Yamaguchi K, Berg T, Stratos K, Daumé H III (2012) Midge: generating image descriptions from computer vision detections. In: Proceedings of the 13th conference of the European chapter of the association for computational linguistics, association for computational linguistics
Pan JS, Feng Q, Yan L, Yang JF (2015) Neighborhood feature line segment for image classification. IEEE Trans Circuits Syst Video Technol 25(3):387–398
Papineni K, Roukos S, Ward T, Zhu WJ (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting on association for computational linguistics, association for computational linguistics
Parikh D, Grauman K (2011) Relative attributes. In: 2011 international conference on computer vision. IEEE
Ren Z, Gao S, Chia LT, Tsang IWH (2014) Region-based saliency detection and its application in object recognition. IEEE Trans Circuits Syst Video Technol 24 (5):769–779
Rohrbach A, Rohrbach M, Schiele B (2015) The long-short story of movie description. In: Pattern recognition. Springer
Schuster S, Krishna R, Chang A, Fei-Fei L, Manning CD (2015) Generating semantically precise scene graphs from textual descriptions for improved image retrieval. In: Proceedings of the fourth workshop on vision and language
Socher R, Karpathy A, Le QV, Manning CD, Ng AY (2014) Grounded compositional semantics for finding and describing images with sentences. Trans Assoc Comput Linguist 2(1):207–218
Song X, Shi Y, Chen X, Han Y (2018) Explore multi-step reasoning in video question answering. In: Proceedings of the ACM international conference on multimedia (ACM MM)
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. In: Advances in neural information processing systems
Thomason J, Venugopalan S, Guadarrama S, Saenko K, Mooney R (2014) Integrating language and vision to generate natural language descriptions of videos in the wild. In: Proceedings of the 25th international conference on computational Linguistics (COLING) August
Vinyals O, Toshev A, Bengio S, Erhan D (2015) Show and tell: a neural image caption generator. In: CVPR
Wang C, Yan S, Zhang L, Zhang HJ (2009) Multi-label sparse coding for automatic image annotation. In: CVPR. IEEE
Wang H, Xiao B, Wang L, Zhu F, Jiang YG, Wu J (2015) Chcf: a cloud-based heterogeneous computing framework for large-scale image retrieval. IEEE Trans Circuits Syst Video Technol 25(12):1900–1913
Wang B, Xu Y, Han Y, Hong R (2018) Movie question answering: remembering the textual cues for layered visual contents. In: AAAI
Wang H, Xu Y, Han Y (2018) Spotting and aggregating salient regions for video captioning. In: Proceedings of the ACM international conference on multimedia (ACM MM)
Werbos PJ (1990) Backpropagation through time: what it does and how to do it. In: Proceedings of the IEEE
Wu A, Han Y (2018) Multi-modal circulant fusion for video-to-language and backward. In: IJCAI, pp 1029–1035
Wu Q, Shen C, Liu L, Dick A, van den Hengel A (2016) What value do explicit high level concepts have in vision to language problems? In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xu Y, Han Y, Hong R, Tian Q (2018) Sequential video vlad: training the aggregation locally and temporally. IEEE Trans Image Process 27(10):4933–4944
Yang Y, Shen HT, Ma Z, Huang Z, Zhou X (2011) l2, 1-norm regularized discriminative feature selection for unsupervised learning. In: IJCAI proceedings-international joint conference on artificial intelligence. Citeseer
Yang Y, Teo CL, Daumé H III, Aloimonos Y (2011) Corpus-guided sentence generation of natural images. In: Proceedings of the conference on empirical methods in natural language processing, association for computational linguistics
Yang Z, Han Y, Wang Z (2017) Catching the temporal regions-of-interest for video captioning. In: Proceedings of the ACM international conference on multimedia (ACM MM)
Young P, Lai A, Hodosh M, Hockenmaier J (2014) From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions. Trans Assoc Comput Linguist 2:67–78
Zhang L, Wang L, Lin W, Yan S (2014) Geometric optimum experimental design for collaborative image retrieval. IEEE Trans Circuits Syst Video Technol 24(2):346–359
Zhao S, Liu Y, Han Y, Hong R, Hu Q, Tian Q (2018) Pooling the convolutional layers in deep convnets for video action recognition. IEEE Trans Circuits Syst Video Technol 28(8):1839–1849
Zhou D, Huang J, Schölkopf B (2006) Learning with hypergraphs: clustering, classification and embedding. In: Advances in neural information processing systems
Acknowledgements
This work is supported by the NSFC (under Grant U1509206,61472276, 61876130) and Tianjin Natural Science Foundation (no. 15JCYBJC15400).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Guo, R., Ma, S. & Han, Y. Image captioning: from structural tetrad to translated sentences. Multimed Tools Appl 78, 24321–24346 (2019). https://doi.org/10.1007/s11042-018-7118-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-7118-7