
Abstract
This paper presents a new method for human action recognition fusing depth images and skeletal maps. Each depth image is represented by 2D and 3D auto-correlation of gradients features. A feature using spatial and orientational auto-correlation is extracted from depth images. Mutual information is used to define the similarity of each frame in the skeleton sequence, and then extract the key frames from the skeleton sequence. The skeleton feature extracted from the key frames as complementary features to cope with the temporal information loss in depth images. Each set of feature is used as input to two extreme learning machine classifiers and assign different weight to each set of feature. Using different classifier weights provides more flexible to different features. The final class label is determined according to the fused result. Experiments conducted on MSR_Action3D depth action data set show the accuracy of this proposed method is 1.5% higher than the state-of-the-art action recognition methods.
Similar content being viewed by others

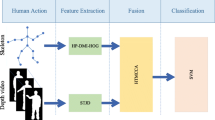
1 Introduction
Human action recognition [10, 15] is an important field of computer vision and pattern recognition, which has a wide range of applications. It is more prominent in video surveillance, human-computer interaction, virtual reality and other applications [19]. The traditional research on human behavior recognition is aimed at the RGB image sequence with 2D information. However, the influence of RGB images on light and background has become a challenge to study human behavior recognition. Compared with RGB images, RGB-D images can not only successfully capture three-dimensional information, but also provide depth information. Depth information represents the distance between the target and the depth camera in the visual range. It can ignore the influence of external factors such as light and background, thus depth data are studied to recognition human action. Shen,Lu, et al. [13, 18] have superior performance on identifying human behavior based on depth data.
Although great progress has been made in the study of human behavior recognition, its challenges are still enormous, especially in capturing space-time information and information redundancy. First of all, it is difficult to capture the complete spatial-temporal structure of action from the video due to the complex background. The method of acquiring spatial-temporal interest points can capture temporal and spatial information of action, but the performance of this method is mainly dependent on correctly obtaining enough interest points. Machine learning can be used to obtain the spatial-temporal information. but consumes much time. However, this method consumes much time, and needs to adjust the parameters. Then, the human action sequence contains a large amount of redundant data in video. If the action characteristics include all data, the redundant information may reduce the accuracy of the identification algorithm. If the selected features just involve part of action data, some information characterizing action will be abandoned. and the recognition accuracy will be disturbed at the same time. Therefore, it is necessary to design a human action recognition method which only retains the valid information of recognition and classification to avoid the influence of these two types of factors.
In this paper, a method of extracting key frames from skeletal sequence is proposed. Multi-feature is used to recognize human action combining the depth features extracted from time and space. The overall framework is shown in Fig. 1. Firstly, gradient and spatial information is acquired from depth image sequences to characterize spatial-temporal information. Secondly, select the key frames from the skeletal sequence, and then establish three kinds of models from key frames. Thirdly, decrease the dimensions of features by reducing the dimension and make the dimensions of all features same. Finally, the two types of features are assigned different weight to highlight distinguishing features.

Overall framework
There are three contributions in human behavior recognition in this paper.
-
(1)
Multi feature combining depth features with skeleton features is used to recognize human action, which makes up for the lack of information in time and space.
-
(2)
Define key frames of skeleton sequences using mutual information.
-
(3)
Use key frames to reduce similar information in skeletal data, so as to reduce the redundant information which has little effect on Classification.
The feature model extracted from the skeleton contains both local information and global information, which makes the skeleton feature more informative.
2 Related work
A variety of feature descriptors based on depth sequences are explored to characterize human action through unremitting efforts. And it achieved remarkable results.For example, depth images in a depth video sequences were projected onto three orthogonal planes. Then, the difference between projected depth maps were accumulated to form three depth motion maps (DMM).Finally, histogram of gradient (HOG) features were extracted from DMM in [21]. In [1], local binary pattern (LBP) feature was also used to describe DMM, which improved the recognition rate of human action. In [4], a new method that fused 2D and 3D gradient local auto-correlation (GLAC) feature with weight for human action recognition using depth sequences was proposed, which made up for the lack of DMM features in time and space.
With the development of technology, skeleton sequences have been successfully extracted from depth image sequences. Skeleton sequences can provide the coordinate of human key joint,so as to determine the specific position of each part of the body. Therefore, feature was studied from depth sequences to skeleton sequences [9]. Then, a new method to predict the 3D position of the body joints quickly and accurately from a single depth image was proposed, but lacking time information [17]. In [20], a skeletal feature descriptor called Eigenjoints was proposed, which can effectively combine static posture, motion characteristics and overall dynamic action characteristics with the difference of the position of the joint points. In [22], a novel action recognition method that combines gradient information with sparse representation was introduced. Then,sparse coding was applied on the coarse Depth-Skeleton feature, which can effectively suppress redundant information and highlight discriminative parts. And in [7], a new representation of skeleton sequences was presented to adequately capture the complex spatial structures and the long-term temporal dynamics of the skeleton sequences, which were very important to recognize the action.
Inspired by Zhang [22], this paper proposes a new feature representation method, which can not only capture the information characteristics of the current frame, but also obtain the difference between the current frame and other frames. In this paper, we need to extract the relatively key frames to represent the skeleton with small variation in the movement, and then analyze the characteristics of the obtained key frames, which is different from other methods for extracting the skeleton features.
3 Feature extraction and analysis
Action recognition is distinguished by different structures. And different action has different structures. As not all skeletal joints are informative for action recognition, and the irrelevant joints often bring noise which can degrade the performance, we need to pay more attention to the informative ones in [11]. And for a sequence, the distribution of frames is not uniform due to the minor changes in two neighbor frames. At this point, we can ignore their differences and use one frame to represent these two frames. This paper calls the frame as the key frame of the two frames. If we extract the key frames of skeleton sequence, it will not affect the overall structure of the action. The length of skeletal sequence can be reduced by extracting the key frames, which can not only improve the efficiency of feature extraction but also eliminate the redundant information.
In fact,mutual information (MI) is a useful measure of information. So it can be regarded as the amount of information about another random variable contained in a random variable.
We know that MI is calculated as formula (1).
Where the entropy h(St) is a measure of variablilty of the t th skeleton St in action sequence. S is the image set of entire sequence. h(St, St+ 1) represents the similarity between two neighbor skeletons. Mathematical relation between h(St) and h(St, St+ 1) is shown in Fig. 2.

Diagram of mutual information
And h(S) is calculated as formula (2).
h(St, St+ 1) is calculated as formula (3).
Where r, k are respectively the depth value of the two maps St and St+ 1. \(p_{s^{t}}(r)=p(\mathbf {S}^{t}=r)\) is the probability distribution of r, and the joints probability distribution function \(p_{s^{t}s^{t+1}}(r,k)=P(\mathbf {S}^{t}=r\cap \mathbf {S}^{t+1}=k)\) is normalized 2D histogram of the two image in [5].
In this paper, mutual information is used to determine the similarity between the two neighbor skeletons. Actually, the smaller the value is, the greater the difference between the two frames is. So we should select the most discriminative frame from the complete frame sequence of an action. In [22], Zhang et al. selected one of the frames to characterize the entire skeleton sequence. However,the average mutual information is selected as the basis of discrimination in this paper, and then represent the entire skeleton sequence using many frames. The specific algorithm steps are as follows.
- Enter::
-
Node coordinates of the skeleton sequence. Suppose there are M frames in this skeletal sequence, with N nodes in each frame.
- Output::
-
Key frames of skeletal sequence.
- Step1.:
-
Transform the coordinates of skeletal joints so as to obtain the new skeletal joint coordinates with the spine as the origin.
- Step2.:
-
Calculate MI between two neighbor frames of skeleton and the average mutual information \(\overline {MI}\).
- Step3.:
-
Mark the skeletal frame for each MI. If \(MI\ge \overline {MI}\), the frame will be recorded as 1, otherwise recorded as 0.
- Step4.:
-
Keep the eligible frames of the skeletal map.
- Step4.1.:
-
If the sum of the markers of the skeletal map is not 0 from the d × (a − 1) + 1 th frame to the d × a th frame, we will keep all the frames marked as 1. Otherwise keep the \(\left \lceil \frac {d}{2}\right \rceil \) th frame, where a = 1.
- Step4.2.:
-
a ← a + 1.
- Step4.3.:
-
Repeat Step4.2 and Step4.3, until \(a=\left \lceil \frac {M}{d}\right \rceil \).
Not only can this method to extract key frames keep the original structure, but also remove the complex and repetitive data.
Mutual information is more sensitive to the changes between paired images. In order to highlight the degree of change in action, we extracted three models of skeletal sequence, such as static gesture model, current motion model and global migration model. However, these models presented as a triangular matrix structure are different from Yang [20]. They are built based on the key frames, and the number of nodes is also different. Figure 1 also shows the method of extracting skeletal feature.
-
(1)
Static posture model
The static posture model fcc refers to the posture of human body at a certain moment. The footstep action is relatively static for the waving action, while the position of the hand changes greatly. As a result, the model can highlight the part with obvious change. It is calculated as formula (4).
$$ \mathbf{f}_{\text{cc}}=\left\{\mathbf{s}_{i}-\mathbf{s}_{j}|i\in[1,N-1],j\in[2,N]i<j\right\} $$(4)Where c represents the current frame. si = (xi, yi, zi) is the value of the i th joint. And i, j are different joints of skeleton sequence with N joints. The origin named spine will be ignored in the calculation, so N = 19, \(\mathbf {f}_{\text {cc}}=\frac {N(N-1)}{2}\times 3= 513\).
-
(2)
Current motion model
The current motion model fcp refers to the change between two neighbor skeleton maps. As a result, the model can highlight the range of changes of the current joints. It is calculated as formula (5).
$$ \mathbf{f}_{\text{cp}}=\left\{\mathbf{s}_{i}^{\mathrm{c}}-\mathbf{s}_{j}^{\mathrm{p}}|\mathbf{s}_{i}^{\mathrm{c}}\in\mathbf{S}^{\mathrm{c}},\mathbf{s}_{j}^{\mathrm{p}}\in\mathbf{S}^{\mathrm{p}},i,j\in[1,N]\right\} $$(5)Where p represents the previous frame of the current frame c. And \(\mathbf {s}_{i}^{\mathrm {c}}\) is the value of the i th joint in c. If S = [s1, s2,..., sN], S ∈ RN×3, Sc will represent the c the skeletal map. So The length of fcp is N × N × 3 = 1083.
-
(3)
Global offset model
The global offset model fco refers to the dynamic change of joints between the current frame c and the first frame o. As a result, the model with global characteristics can reflect the changing trend of the current nodes with global characteristics. It is calculated as formula (6).
$$ \mathbf{f}_{\text{co}}=\left\{\mathbf{s}_{i}^{\mathrm{c}}-\mathbf{s}_{j}^{\mathrm{o}}|\mathbf{s}_{i}^{\mathrm{c}}\in\mathbf{S}^{\mathrm{c}},\mathbf{s}_{j}^{\mathrm{o}}\in\mathbf{S}^{\mathrm{o}},i,j\in[1,N]\right\} $$(6)
In brief, the underlying feature F = [fcc, fcp, fco] of a skeleton consists of three models. There is no uniform standard for the coordinates of skeleton sequence, due to the difference of the experimental subjects. Therefore, it is necessary to normalize the features so as to avoid the dominance of larger elements in the range of smaller elements.
Since the number of key frames obtained from each skeleton sequence is different, the fisher vector (FV) based on Gauss mixture model is used to process features of different lengths. It makes the feature data linearly separable. The Fisher vector measures the distance between two samples. That is, the similarity between two samples is calculated. Now, 128 clustering centers are taken in the Gaussian mixture model.
According to the method of extracting depth feature in [4], the depth sequence with time is projected onto three orthogonal planes to form three maps named v. It is supposed that there are M frames in a depth sequence. So Depth motion map Iv is calculated as formula (7).
Where vt is projected map in the t th frame in a depth video sequence.
Doubtlessly, the region of interest algorithm is performed on the depth motion map to make the projected images with same angle have the same size. And the formation of depth motion map is shown in Fig. 3.

Formation of depth motion map
In this paper, 2D and 3D depth feature FD is obtained through the magnitude \(n=\sqrt {\frac {\partial \mathbf {v}^{2}}{\partial x}+\frac {\partial \mathbf {v}^{2}}{\partial y}}\) and the orientation angle \(\theta =\arctan (\frac {\partial \mathbf {v}}{\partial x},\frac {\partial \mathbf {v}}{\partial y})\) of the image gradient at each pixel in the time and space. Then, FS and FD are used individually as input to two ELM[6] classifiers. The probability outputs of each individual classifier are assigned with different weights and finally merged to generate the final outcome l∗.
In fact, we use the logarithmic function to estimate the global membership degree. It is calculated as formula (8). The final outcome is determined according to the maximum membership degree and calculated as formula (9).
Where p1(lk|FS) and p2(lk|FD) are individually the posterior probability calculated by skeletal feature and depth feature through Sigmoid function.
4 Experiments
The experiment runs on ASUS K43S notebook with Windows 8.1 and Matlab R2014b . Its CPU is 2.40GHz and installation memory is 6.00GB.
4.1 Data set
Experiments are conducted on the MSR Action3D dataset [16] provided by Microsoft. There are 557 depth video sequences in this data set. In this paper, we will select 524 depth video sequences because 33 depth video sequences are lost or wrong. The data set includes 20 actions performed by 10 subjects. And the 20 action are: high wave,horizontal wave,hammer,hand catch,forward punch,high throw,draw x,draw tick,draw circle,hand clap,two hand wave,side boxing,bend,forward kick,side kick,jogging,tennis swing,tennis serve,golf swing,pick up throw.
4.2 Settings
- Experiment 1::
-
Similar to Chen et al. [1], the 20 actions are divided into 3 groups (AS1, AS2, AS3). And the MSR Action3D subset data set is shown in Table 1. The actions with similar similarity were divided into the same group, and each group of samples was subjected to three experiments. In the first experiment, there is more testing data than training data. Where \(\frac {1}{3}\) sample is used as training, and the remaining data is used to test. By comparison, there is less testing data than training data in the second experiment. Where \(\frac {2}{3}\) sample is used as training, and the remaining data is used to test. Finally, cross validation [12] is used to test in the third experiment.
- Experiment 2::
-
Similar to Chen et al. [4], all samples are classified at the same time. The data collected from the objects marked as 1, 3, 5, 6, 7 and 9 is used to train,and the remaining data are used for testing.
4.3 Results
There are two points need to pay attention to when dealing with the depth video sequence without the earlier two frames and the later ones. First, it avoids that minor movements are interfered with the edges of the depth motion map so as to form noise at the tbeginning and end of an action. Second, there is an objective difference between the data collected by the object. And the human body shape will lead to unnecessary inter class error. To avoid this kind of situation, ROI is performed on the projected depth motion map, so that the projection images obtained in the same perspective have the same size. In this paper, the size of the front, side, top is separately, 102 × 54, 102 × 75 and 75 × 54.
In addition, the size of the parameters d should be determined when extracting key frames. If d is smaller, the algorithm will contain redundant information, which can not only effectively reduce the feature amount,but also lose its advantage in the time taken by the feature extraction. On the contrary, if d is larger, the algorithm will lost useful information and reduce recognition rate. Figure 4 shows the relationship among d, recognition rate and the time. From this figure, we can see the recognition rate of human action based on skeleton sequence is the highest when d = 3. And its average time spent by all samples is 0.0934s. Where d = 1 means that no key frames are extracted from skeleton sequences. At this time, redundant information is included, so the relative recognition rate of key frame is decreased, and the feature extraction takes more time.

Recognition rate with different d and time
When d = 3, Fig. 5 shows the result of extracting key frames. Where Fig. 5a, b and c are respectively the original skeleton, new skeleton with the spine as the origin, and the skeleton composed of key frames extracted from the new skeleton. As shown in Fig. 5, the remaining skeleton essentially restores the structure of the original skeleton and highlights the areas with obvious changes.

Results of key frames
In this paper, three models are established in the calculation of skeleton characteristics. And identifying three models respectively to proves that combination model can improve the accuracy of human action recognition. We can see that the recognition rate of skeletal features is the highest when the three models are used simultaneously in Table 2. Its recognition rate is 79.3970%. So that the recognition rate is at least 0.5% higher than single model and the other.
Besides, weights FS measure the contribution of depth features FD and skeletal features FS to classification. In this paper, μ ∈ [0,1] is the weight of FS, then have experiments with different μ cumulated by 0.1. Where μ = 0 means that FS does not contribute to the classification of human action. On the contrary, μ = 1 means that the classification of human action recognition depends entirely on skeletal features, at which point FD can be removed. Cross-validation is used for calculation to estimate the optimal weight μ. Recognition rate with different μ is shown in Table 3. We know the proposed method makes the higher performance when μ = 0.1. At this moment, the recognition rate of FD is 13.5678% higher than FS. Therefore, it is reasonable to assign higher weights to FD. Experiments show that the fused features have a higher discriminative power.
The results of comparisons between the proposed method and the current mainstream algorithms are listed in Fig. 6 and Table 4. In addition, the average results of the three sets of experiments are given in Fig. 6. Seen from Fig. 6, the recognition rate of proposed in this paper is independent on the number of samples. The proposed method combined with the advantages of depth and skeletal features has obvious advantages in all three groups of experiments. The average value is at least 2.1% higher than other good methods, Especially in test3.

Results of experiment 1
All the movements are identified simultaneously in experiment 2. Because of the large amount of sample data, the new method proposed in this paper is more challenging. As can be seen from Table 5, the proposed method achieves a recognition rate of 94.4724%, which increases the recognition rate by at least 1.5% compared with other methods.
In order to deeply understand the performance of the algorithm recognition, the confusion matrix of recognition results is given in Fig. 7. The number in the matrix represents the number of test samples. Comparing Fig. 7a with b, some similar actions in this method have been disrupted during recognition, such as “ hand catch”, “high wave”, “draw x” and “horizontal wave”. However, the fusion method proposed in this paper reduces the misclassification of “draw circle” and “draw x ”, compared with the confusion matrix obtained by the depth feature recognition. As shown in Fig.7 the recognition rate of “bend” is 0%, and mistaken for “pick up throw”. Since the number of “bend” is too small, and the only one sample is used for testing, there has been no sample to train the model of “bend”. “pick up throw” including “bend” is trained, so “bend” is wrongly identified as “pick up throw”. The recognition rate of “draw circle” increases from \(\frac {9}{12}\) to \(\frac {11}{12}\). The method of this article strictly distinguishes “draw circle” from “hammer” and reduces the probability of being wrongly divided into “draw tick”. And “draw circle” is similar to “draw tick”. Both action containing the act of painting an arc on the chest and the incompleteness of collected data lead to “draw circle” wrongly identified as “draw tick”.

Confusion matrix
4.4 Conclusion
This paper presents a method for extracting keyframes for skeletal sequence. Firstly, the mutual information is used to extract the key frames from the similarity evaluation of two neighbor skeleton images, which can reduce the similar features in skeleton images and accelerate the speed of feature extraction. Secondly, the static attitude model, the current motion model and the dynamic offset model are established on the basis of the key frames. Abundant local features and global features can be obtained through three models to improve the recognition rate. Thirdly, fisher algorithm based on Gauss mixture model is used to deal with skeleton features. Finally, fuse the skeleton feature with the depth feature by weight to improve the recognition rate of human action.
In this paper, the key frame is extracted from skeleton sequence, which reduces the amount of skeleton data and accelerates the speed of feature extraction. And the depth features containing abundant detail has an important role of classification but it consumes too much time. So simplifying the depth feature will be one of the future researches to have a real-time effect on human action recognition without lowering the recognition rate.
References
Chen C, Jafari R, Kehtarnavaz N. (2015) Action recognition from depth sequences using depth motion maps-based local binary patterns
Chen C, Hou ZJ, Zhang BC (2015) Gradient local auto-correlations and extreme learning machine for depth-based activity recognition
Chen C, Liu K, Kehtarnavaz N (2016) Real-time human action recognition based on depth motion maps. J Real-Time Image Proc 12(1):155–163
Chen C, Zhang B, Hou ZJ, Jiang J, Liu M, Yang Y (2017) Action recognition from depth sequences using weighted fusion of 2d and 3d auto-correlation of gradients features. Multimed Tools Appl 76(3):4651–4669
Dame A, Marchand E (2012) Second-order optimization of mutual information for real-time image registration. IEEE Trans Image Process 21(9):4190
Huang GB, Zhou H, Ding X, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybern B 42(2):513–529
Ke Q, Bennamoun M, An S, Sohel F, Boussaid F (2018) Learning clip representations for skeleton-based 3d action recognition. IEEE Trans Image Process PP(99):1–1
Kobayashi T, Otsu N (2012) Motion recognition using local auto-correlation of space-time gradients. Pattern Recogn Lett 33(9):1188–1195
Li W, Zhang Z, Liu Z (2010) Action recognition based on a bag of 3D points
Liang F, Zhang ZL, Xiang Y, Tong Z (2015) Action recognition of human’s lower limbs in the process of human motion capture. Journal of Computer-Aided Design and Computer Graphics 12(27):2419–2427
Liu J, Wang G, Duan LY, Abdiyeva K, Kot AC (2018) Skeleton-based human action recognition with global context-aware attention lstm networks. IEEE Trans Image Process PP(99):1–1
Liu XY, Li P, Gao CH (2011) Fast leave-one-out cross-validation algorithm for extreme learning machine. Journal of Shanghai Jiaotong University 45(8):1140–1145
Lu ZQ, Hou ZJ, Chen C, Liang JZ (2016) Action recognition based on depth images and skeleton data. J Comput Appl 36(11):2979–2984
Oreifej O, Liu Z (2013) HON4D: histogram of oriented 4D normals for activity recognition from depth sequences. In: Proceedings of 2013 IEEE conference on computer vision and pattern recognition. IEEE Computer Society Press, Los Alamitos, pp 716–723
Shan Y, Zhang Z, Huang K (2016) Visual human action recognition:history,status and prospects. Journal of Computer Research and Development 53(1):93–112
Shotton J, Fitzgibbon A, Cook M, Sharp T, Finocchio M, Moore R, Kipman A, Blake A (2011) Real-time human pose recognition in parts from single depth images. Commun ACM 56(1):1297–1304
Shotton J, Fitzgibbon A, Cook M, Sharp T, Finocchio M, Moore R, Kipman A, Blake A (2013) Real-time human pose recognition in parts from single depth images. Springer, Berlin
Shen XX (2014) Research on human behavior recognition alogrithms based on depth information. Tianjin University of Technology
Xu HN, Chen EQ, Liang CB (2016) Three-dimensional spatio-temporal feature extraction method for action recognition. J Comput Appl 36(2):568
Yang X, Tian YL (2012) Eigenjoints-based action recognition using naïve-bayes-nearest-neighbor. Springer, Berlin
Yang X, Zhang C, Tian YL (2012) Recognizing actions using depth motion maps-based histograms of oriented gradients
Zhang H, Zhong P, He J, Xia C (2017) Combining depth-skeleton feature with sparse coding for action recognition. Neurocomputing 230(C):417–426
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Xu, Y., Hou, Z., Liang, J. et al. Action recognition using weighted fusion of depth images and skeleton’s key frames. Multimed Tools Appl 78, 25063–25078 (2019). https://doi.org/10.1007/s11042-019-7593-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-7593-5