
Abstract
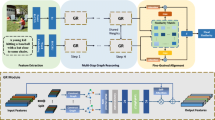
Cross-modal image-text matching has attracted considerable interest in both computer vision and natural language processing communities. The main issue of image-text matching is to learn the compact cross-modal representations and the correlation between image and text representations. However, the image-text matching task has two major challenges. First, the current image representation methods focus on the semantic information and disregard the spatial position relations between image regions. Second, most existing methods pay little attention to improving textual representation which plays a significant role in image-text matching. To address these issues, we designed a decipherable cross-modal multi-relationship aware reasoning network (CMRN) for image-text matching. In particular, a new method is proposed to extract multi-relationship and to learn the correlations between image regions, including two kinds of visual relations: the geometric position relation and semantic interaction. In addition, images are processed as graphs, and a novel spatial relation encoder is introduced to perform reasoning on the graphs by employing a graph convolutional network (GCN) with attention mechanism. Thereafter, a contextual text encoder based on Bidirectional Encoder Representations from Transformers is adopted to learn distinctive textual representations. To verify the effectiveness of the proposed model, extensive experiments were conducted on two public datasets, namely MSCOCO and Flickr30K. The experimental results show that CMRN achieved superior performance when compared with state-of-the-art methods. On Flickr30K, the proposed method outperforms state-of-the-art methods more than 7.4% in text retrieval from image query, and 5.0% relatively in image retrieval with text query (based on Recall@1). On MSCOCO, the performance reaches 73.9% for text retrieval and 60.4% for image retrieval (based on Recall@1).












Similar content being viewed by others


References
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering, pp 6077–6086, 06
Arqub O A, Abo-Hammour ZS (2014) Numerical solution of systems of second-order boundary value problems using continuous genetic algorithm. Inf Sci 279:396–415
Chen J, Zhuge H (2019) Extractive summarization of documents with images based on multi-modal rnn. Future Gener Comput Syst 99:04
Chung J, Gülçehre Ç, Cho K, Bengio Y (2014) Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv:1412.3555
Cornia M, Baraldi L, Tavakoli H R, Cucchiara R (2020) A unified cycle-consistent neural model for text and image retrieval. Multimed Tools Appl 1–25, 07
Devlin J, Chang M-W, Lee K, Toutanova K (2019) BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, vol 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, pp 4171–4186
Faghri F, Fleet DJ, Kiros JR, Fidler S (2018) Vse++: improving visual-semantic embeddings with hard negatives. In: BMVC
Frome A, Corrado G S, Shlens J, Bengio S, Dean J, Ranzato M, Mikolov T (2013) Devise: a deep visual-semantic embedding model. In: NIPS, pp 2121–2129
Gu J, Cai J, Joty S, Niu L, Wang G (2018) Look, imagine and match: improving textual-visual cross-modal retrieval with generative models. In: 2018 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 7181–7189
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), pp 770–778
Hou J, Wu X, Qi Y, Zhao W, Luo J, Jia Y (2019) Relational reasoning using prior knowledge for visual captioning. Computer Vision and Pattern Recognition. arXiv:1906.01290
Huang Y, Wang W, Wang L (2017) Instance-aware image and sentence matching with selective multimodal lstm. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), pp 7254–7262
Huang Y, Wu Q, Song C, Wang L (2018) Learning semantic concepts and order for image and sentence matching, pp 6163–6171, 06
Huang F, Zhang X, Zhao Z, Li Z (2019) Bi-directional spatial-semantic attention networks for image-text matching. IEEE Trans Image Process 28:2008–2020
Karpathy A, Feifei L (2015) Deep visual-semantic alignments for generating image descriptions. In: 2015 IEEE conference on computer vision and pattern recognition (CVPR), pp 3128–3137
Kingma D, Adam J B A (2014) A method for stochastic optimization. In: International conference on learning representations, p 12
Kipf T, Welling M (2017) Semi-supervised classification with graph convolutional networks. arXiv:1609.02907
Klein B, Lev G, Sadeh G, Wolf L (2015) Associating neural word embeddings with deep image representations using fisher vectors. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 4437–4446, 06
Krishna R, Zhu Y, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalantidis Y, Li L, Shamma D A et al (2017) Visual genome: connecting language and vision using crowdsourced dense image annotations. Int J Comput Vis 123(1):32–73
Lee K, Chen X, Hua G, Hu H, He X (2018) Stacked cross attention for image-text matching. In: ECCV. Springer, Cham, pp 212–228
Li Y, Tarlow D, Brockschmidt M, Zemel R S (2015) Gated graph sequence neural networks. CoRR, arXiv:1511.05493
Li S, Xiao T, Li H, Yang W, Wang X (2017) Identity-aware textual-visual matching with latent co-attention. In: 2017 IEEE international conference on computer vision (ICCV), pp 1908–1917
Li K, Zhang Y, Li K, Li Y, Fu Y (2019) Visual semantic reasoning for image-text matching. In: 2019 IEEE/CVF International conference on computer vision (ICCV), pp 4653–4661
Li L, Gan Z, Cheng Y, Liu J (2019) Relation-aware graph attention network for visual question answering. In: 2019 IEEE/CVF international conference on computer vision (ICCV), pp 10313–10322
Lin X, Parikh D (2016) Leveraging visual question answering for image-caption ranking 9906:261–277, 10
Lin T -Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick C (2014) Microsoft coco: common objects in context, 8693, 04
Liu Y, Guo Y, Liu L, Bakker E M, Lew M S (2019) Cyclematch: a cycle-consistent embedding network for image-text matching. Pattern Recognit 93:365–379, 05
Liu C, Mao Z, Liu A -A, Zhang T, Wang B, Zhang Y (2019) Focus your attention: a bidirectional focal attention network for image-text matching. In: Proceedings of the 27th ACM international conference on multimedia, MM ’19. Association for Computing Machinery, New York, pp 3–11
Liu C, Mao Z, Zhang T, Xie H, Wang B, Zhang Y (2020) Graph structured network for image-text matching. arXiv:2004.00277
Lu J, Batra D, Parikh D, Lee S (2019) Vilbert: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In: Advances in neural information processing systems, pp 13–23
Ma L, Lu Z, Shang L, Li H (2015) Multimodal convolutional neural networks for matching image and sentence. In: 2015 IEEE international conference on computer vision (ICCV), pp 2623–2631
Ma L, Jiang W, Jie Z, Wang X (2019) Bidirectional image-sentence retrieval by local and global deep matching. Neurocomputing 345:36–44, 02
Messina N, Falchi F, Esuli A, Amato G (2020) Transformer reasoning network for image-text matching and retrieval. arXiv:2004.09144
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. arXiv:1301.3781
Nam H, Ha J, Kim J (2017) Dual attention networks for multimodal reasoning and matching. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), pp 2156–2164
Norcliffebrown W, Vafeias S, Parisot S (2018) Learning conditioned graph structures for interpretable visual question answering. In: NeurIPS, pp 8334–8343
Paszke A, Gross S, Chintala S, Chanan G, Yang E, Devito Z, Lin Z, Desmaison A, Antiga L, Lerer A (2017) Automatic differentiation in pytorch
Qi D, Su L, Song J, Cui E, Bharti T, Sacheti A (2020) Imagebert: cross-modal pre-training with large-scale weak-supervised image-text data. Comput Vis Pattern Recognit. arXiv:2001.07966
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39:1137–1149, 06
Scarselli F, Gori M, Tsoi A C, Hagenbuchner M, Monfardini G (2009) The graph neural network model. IEEE Trans Neural Netw 20(1):61–80
Trott A, Xiong C, Socher R (2018) Interpretable counting for visual question answering. arXiv:1712.08697
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: NIPS
Velickovic P, Cucurull G, Casanova A, Romero A, Lio P, Bengio Y (2018) Graph attention networks. arXiv:1710.10903
Venugopalan S, Rohrbach M, Donahue J, Mooney R J, Darrell T, Saenko K (2015) Sequence to sequence—video to text. In: 2015 IEEE international conference on computer vision (ICCV), pp 4534–4542
Wang L, Li Y, Lazebnik S (2016) Learning deep structure-preserving image-text embeddings. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), pp 5005–5013, 06
Wang Y, Yang H, Qian X, Ma L, Lu J, Li B, Fan X (2019) Position focused attention network for image-text matching. Computation and Language. arXiv:1907.09748
Wang L, Li Y, Huang J, Lazebnik S (2019) Learning two-branch neural networks for image-text matching tasks. IEEE Trans Pattern Anal Mach Intell 41(2):394–407
Wang T, Xu X, Yang Y, Hanjalic A, Shen H, Song J (2019) Matching images and text with multi-modal tensor fusion and re-ranking. In: Proceedings of the 27th ACM international conference on multimedia, pp 12–20, 10
Wang P, Wu Q, Cao J, Shen C, Gao L, Van Den Hengel A (2019) Neighbourhood watch: referring expression comprehension via language-guided graph attention networks. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 1960–1968
Wei Y, Zhao Y, Lu C, Wei S, Liu L, Zhu Z, Yan S (2017) Cross-modal retrieval with cnn visual features: a new baseline. IEEE Trans Syst Man Cybern 47(2):449–460
Xu X, Wang T, Yang Y, Zuo L, Shen F, Shen H T (2020) Cross-modal attention with semantic consistence for image-text matching. IEEE Trans Neural Netw Learn Syst 02:1–14
Yang Z, Qin Z, Yu J, Hu Y (2018) Scene graph reasoning with prior visual relationship for visual question answering. arXiv: Multimedia
Yao T, Pan Y, Li Y, Mei T (2018) Exploring visual relationship for image captioning. In: European conference on computer vision, pp 711–727
Young P, Lai A, Hodosh M, Hockenmaier J (2014) From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions. Trans Assoc Comput Linguist 2(1):67–78
Zhang Y, Lu H (2018) Deep cross-modal projection learning for image-text matching. In: The European conference on computer vision (ECCV), pp 707–723
Zhang Y, Hare J S, Prugelbennett A (2018) Learning to count objects in natural images for visual question answering. arXiv:1802.05766
Zheng Z, Zheng L, Garrett M, Yang Y, Xu M, Shen Y -D (2020) Dual-path convolutional image-text embeddings with instance loss. ACM Trans Multimed Comput Commun Appl 16(2): 1–23
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grant 61871278, the Industrial Cluster Collaborative Innovation Project of Chengdu (no. 2016-XT00-00015-GX), the Sichuan Science and Technology Program (no. 2018HH0143).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, J., He, X., Qing, L. et al. Cross-modal multi-relationship aware reasoning for image-text matching. Multimed Tools Appl 81, 12005–12027 (2022). https://doi.org/10.1007/s11042-020-10466-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-10466-8