
Abstract
Aiming at the problem that the traditional deep learning algorithms have unsatisfactory speech enhancement effect under low Signal-to-Noise Ratio (SNR) conditions, this paper improves Deep Neural Network (DNN) and Multiresolution Residual U Network (MultiResU_Net) to discuss the speech enhancement effect. In this paper, the Minimum Mean-Square Error Short-Time Spectral Amplitude Estimator (MMSE-STSA) is used to reduce the noise of the Multi-Resolution Cochleagram (MRCG) features that including the local and global characteristics of speech and using the improved features Improved Multi-Resolution Cochleagram (I-MRCG) as the input of Skip-DNN network to build Skip-DNN speech enhancement model. The short-time Fourier transformed features of the speech signal at low SNR are used as the input of MultiResU_Net network and the output features of residual path and upsampling are rearranged by the hybrid channel to build an improved MultiResU_Net speech enhancement model. Using LibriSpeech ASR corpus, under different SNR conditions, analyze the speech enhancement effects of different network models and different features as the input of the Skip-DNN model. The experimental results show that when the SNR is -5dB, the perceptual evaluation effect of the average speech quality is better that I-MRCG is used as the feature input of the Skip-DNN model. The average short-time objective intelligibility (STOI), the average perceptual evaluation of speech quality (PESQ) and Source-to-Distortion Ratio (SDR) of the improved MultiResU_Net speech enhancement model are higher than other models. It can be seen that both the improved Skip-DNN and MultiResU_Net proposed in this paper have better speech enhancement effect, especially the improved MultiResU_Net network is more suitable for speech enhancement at low SNR.














Similar content being viewed by others
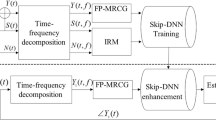
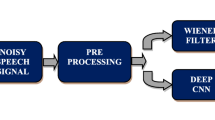
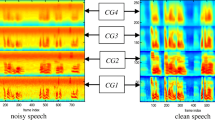
Data availability
All data included in this study are available upon request by contact with the corresponding author.
References
Asma B, Sid AS, Abderrahmane A, Mohammed SY (2021) Improved empirical mode decomposition using optimal recursive averaging noise estimation for speech enhancement. Circuit Syst Signal Process :1–28. https://sci-hub.se/downloads/2021-08-16/99/bouchair2021.pdf
Attabi Y, Champagne B, Zhu W-P (2021) DNN-based calibrated-filter models for speech enhancement. Circuits Syst Signal Process. https://doi.org/10.1007/s00034-020-01604-6
Bulut AE, Koishida K, Low-Latency Single Channel Speech Enhancement Using U-Net Convolutional Neural Networks (2020). 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 6214–6218. https://sci-hub.se/downloads/2020-05-19/75/bulut2020.pdf?rand=61a9f852d4d1d
Chen J-T, Wang Y-X, Wang D-L (2014) A feature study for classification-based speech separation at very low signal-to-noise ratio. Paper presented at 2014 IEEE International Conference on Acoustics, Speech and Signal Processing, 14. https://ieeexplore.ieee.org/document/6854965/
Chen J-T, Wang Y-X, Wang D-L (2016) Noise perturbation for supervised speech separation. Speech Commun 78:1–10. https://www.sciencedirect.com/science/article/abs/pii/S0167639315001405
Chen H, Du J, Hu Y, Dai L-R, Yin B-C, Lee C-H (2021) Correlating subword articulation with lip shapes for embedding aware audio-visual speech enhancement. Neural Netw 143:171–182
Choi HS, Kim JH, Huh J et al (2019) Phase-aware speech enhancement with deep complex U-Net. International Conference on Learning Representations, Montreal, Canada. https://openreview.net/pdf?id=SkeRTsAcYm
Felix W, Juergen G, Martin W et al (2014) Feature enhancement by deep LSTM networks for ASR in reverberant multisource environments. Comput Speech Lang 4(28):888–902
Gao T, Du J, Dai L-R, Lee C-H (2018) Densely connected progressive learning for LSTM-based speech enhancement. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 5054–5058. https://twin.sci-hub.se/7118/4d0fc104065ac4f94f302637571f9352/gao2018.pdf
Ibtehaz N, Rahman MS (2020) MultiResUNet: rethinking the U-Net architecture for multimodal biomedical image segmentation neural networks [J]. Neural Netw 121:74–87
Islam MS, Zhu YY, Hossain MI, Ullah R, Ye ZF (2020) Supervised single channel dual domains speech enhancement using sparse non-negative matrix factorization. Digit Signal Proc 100(C):102697–102697
Jia H-R, Wang W-M, Mei S-L (2021) Combining adaptive sparse NMF feature extraction and soft mask to optimize DNN for speech enhancement. Appl Acoust 171:107666. https://linkinghub.elsevier.com/retrieve/pii/S0003682X20307702
Jiang Y, Wang DL, Liu RS, Feng ZM (2014) Binaural classification for reverberant speech segregation using deep neural networks. IEEE/ACM Trans Audio Speech Lang Process 22:2112–2121
Kang TG, Kwon K, Shin JW, Kim NS (2015) NMF-based target source separation using deep neural network. Published in IEEE Signal Processing Letters. https://ieeexplore.ieee.org/document/6892992
Li L-J, Kang Y-K, Shi Y-C, Kürzinger L, Watzel T, Rigoll G (2021) Light-weight self-attention augmented generative adversarial networks for speech enhancement. Electronics 10(13):1586
Liu W-J, Nie S, Liang S, Zhang X-L (2016) Deep learning based speech separation technology and its developments. Acta Autom Sin 42(6):819–833
Olaf R, Fischer P, Brox T (2015) U-Net: Convolutional networks for biomedical image segmentatin[C]. International Conference on Medical Image Computing and Computer-Assisited Intervention Intervention, 234–241. https://doi.org/10.1007/978-3-319-24574-4_28.pdf
Park SR, Lee JW (2017) A fully convolutional neural network for speech enhancement. INTERSPEECH. https://doi.org/10.21437/Interspeech.2017-1465
Shi W-H, Zhang X-W, Zhang R-X, Han W (2016) Special lectures on deep learning theory and its applications (4) lecture 8 The Application of Deep Learning Methods in Speech Enhancement. Military Commun Technol 37(03):98–104. https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2016&filename=JSTY201603021&v=fegNytVa6QrSPGnMaPlHpz2qMtxEbwAw7zQMaviwn0uv0aRrm8owrnCdYqGPOpu0
Smaragdis P (2007) Convolutive speech bases and their application to supervised speech separation. Published in: IEEE Transactions on Audio, Speech, and Language Processing. https://ieeexplore.ieee.org/document/4032795
Tim F, Marco C, Wilhelm W (2021) Speech signal enhancement in cocktail party scenarios by deep learning based virtual sensing of head-mounted microphones. Hear Res 408:108294
Tseng H-W, Hong M-Y, Luo Z-Q (2015) Combining sparse NMF with deep neural network: A new classification-based approach for speech enhancement. Paper presented at 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, 19–24. https://ieeexplore.ieee.org/document/7178350
Tu M, Zhang X-X (2017) Speech enhancement based on Deep Neural Networks with skip connections. Paper presented at 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, 5–9. https://ieeexplore.ieee.org/document/7953221
Tu Y, Du J, Xu Y, Dai L-R, Lee C-H (2014) Deep neural network based speech separation for robust speech recognition. Published in 2014 12th International Conference on Signal Processing, 19-23. https://ieeexplore.ieee.org/document/7015061?tp=&arnumber=7015061&ranges%3D2013_2015_p_Publication_Year%26queryText%3Ddeep%20neural%20network%20in%20speech=
Vincent E, Rémi G, Cédric F (2006) Performance measurement in blind audio source separation. IEEE Trans Audio Speech Lang Process 14(4):1462–1469
Wang Y-X, Wang D-L (2014) A structure-preserving training target for supervised speech separation. Paper presented at 2014 IEEE International Conference on Acoustics, Speech and Signal Processing, 4–9. https://ieeexplore.ieee.org/document/6854777/footnotes#footnotes
Wang Y-X, Wang D-L (2013) Towards scaling up classification-based speech separation. Published in IEEE Transactions on Audio, Speech, and Language Processing. https://ieeexplore.ieee.org/document/6473841
Williamson DS, Wang YX, Wang DL (2016) Complex ratio masking for monaural speech separation. IEEE/ACM Trans Audio Speech Lang Process 24(3):483–492
Xu Y, Du J, Dai L-R, Lee C-H (2014) An experimental study on speech enhancement based on deep neural networks. IEEE Signal Processing Lett 21(1):66–68
Xu Y, Du J, Dai L-R, Lee C-H (2015) A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans Audio Speech Lang Process 23(1):7–19
Yang Q, Li Y-K, Zhang M-Y et al (2020) Automatic segmentation of COVID-19 CT Images using improved MultiResU_Net[C]. 2020 Chinese Automation Congress (CAC), Shanghai, China, 1614–1618. https://sci-hub.se/downloads/2021-05-14//54/yang2020.pdf?rand=61a9f943ed918
Zhang Q-Y, Zhang D-H, Xu F-J (2021) An encrypted speech authentication and tampering recovery method based on perceptual hashing. Multimed Tools Appl :1–14. https://doi.org/10.1007/s11042-021-10905-0.pdf
Acknowledgements
This work was supported by the national natural science youth foundation of china (No.11804068) and the natural science foundation of Heilongjiang Province (No. LH2020F033).
Funding
This research received by the national natural science youth foundation of china (No.11804068) and the natural science foundation of Heilongjiang Province (No. LH2020F033).
Author information
Authors and Affiliations
Contributions
Chaofeng Lan contributed to the conception of the study and contributed significantly to analysis and manuscript preparation; Lei Zhang polished, edited and checked the article during the first submission process, and also made important contributions in the process of major revisions and adjustments of this article; Yuqiao Wang made important contributions in made adjustments to the structure of the paper, revised the paper, edited the manuscript and english polished; Chundong Liu performeds the experiment、the data analyses and wrote the manuscript.
Corresponding authors
Ethics declarations
This manuscript has been presented as Preprint according to the following link: https://www.researchsquare.com/article/rs-229829/v1.
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Lan, C., Zhang, L., Wang, Y. et al. Research on improved DNN and MultiResU_Net network speech enhancement effect. Multimed Tools Appl 81, 26163–26184 (2022). https://doi.org/10.1007/s11042-022-12929-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12929-6