
Abstract
Automatic children speech recognition is always challenging due to limited corpus and varying acoustic features. One among those is zero speech corpus and large acoustic variability which limits the power of learning of training dataset. To overcome this issue, an effort has been made to build two types of systems: ASR and Tonal-Non tonal (T-NT) classifiers. Initially, robust features are added into the front phase using prosody embedded feature vectors. Various prosody features are combined with MFCC feature vectors which outperformed conventional Mel Frequency Cepstral Coefficients (MFCC) features only. A small reduction in Word Error Rate (WER) is obtain on the original train and test dataset. To further enhance the recognition rate, training data scarcity is remove through two-level augmentation approach: external prosody modifications (using pitch and time scaling parameters) and internal augmentation using speed perturbation approaches (using 3, 4, and 5 way methods). For that purpose, an original and augmented dataset is pooled to learn more statistical parameters information. Significant improvement in the performance of both systems are observe due to two-level augmentations and prosody embedded features. Finally it achieve a relative improvement of 13.1% and 18.3% for ASR and T-NT classifier systems over the baseline system which are processed on a modified train and original test set respectively.



Similar content being viewed by others
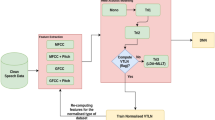
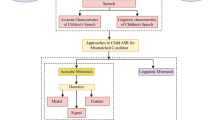
Abbreviations
- ASR:
-
Automatic Speech Recognition
- DNN:
-
Deep Neural Network
- T-NT:
-
Tonal -Non Tonal
- MFCC:
-
Mel Frequency Cepstral Coefficient
- WER:
-
Word Error Rate
- VTLN:
-
Vocal Tract Length Normalization
- LPCC:
-
Linear Predictive Cepstral Coefficient
- RASTA-PLP:
-
Relative Spectral Perceptual Linear Predictive Coding
- PLP:
-
Perceptual Linear Prediction
- PNCC:
-
Power-Normalized Cepstral Coefficients
- GFCC:
-
Gammatone Frequency Cepstral Coefficients
- HMM:
-
Hidden Markov Model
- DTW:
-
Dynamic Time Warping
- DE:
-
Differential Equation
- GA:
-
Genetic Algorithm
- GMM:
-
Gaussian Mixture Model
- VTLP:
-
Vocal Tract Length Perturbation
- MMI:
-
Maximum Mutual Information
- MPE:
-
Minimum Phone Error
- MLE:
-
Maximum Likelihood Equation
- DCT:
-
Discrete Cosine Transformation
- POV:
-
Probability of Voicing
- LDA:
-
Linear Discriminative Analysis
- MLLT:
-
Maximum Likelihood Linear Transformation
- PS:
-
Pitch Scaling
- TS:
-
Time Scaling
References
Anusuya MA, Katti SK (2011) Front end analysis of speech recognition: a review. Int J Speech Technol 14(2):99–145. https://doi.org/10.1007/s10772-010-9088-7
Balam J, Huang J, Lavrukhin V, Deng S, Majumdar S, Ginsburg B (2020) Improving noise robustness of an end-to-end neural model for automatic speech recognition. https://arxiv.org/abs/2010.12715
Bawa P, Kadyan V (2021) Noise robust in-domain children speech enhancement for automatic Punjabi recognition system under mismatched conditions. Appl Acoust 175:107810
Benzeghiba M, De Mori R, Deroo O et al (2007) Automatic speech recognition and speech variability: a review. Speech Comm 49(10–11):763–786. https://doi.org/10.1016/j.specom.2007.02.006
Billa J (2018). ISI ASR system for the low resource speech recognition challenge for Indian languages. In INTERSPEECH 3207–3211
Du C, Yu K (2020) Speaker augmentation for low resource speech recognition. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE 7719–7723. https://doi.org/10.1109/ICASSP40776.2020.9053139
Dua M, Aggarwal RK, Biswas M (2018) Performance evaluation of Hindi speech recognition system using optimized filterbanks. Engineering Science and Technology 21(3):389–398. https://doi.org/10.1016/j.jestch.2018.04.005
Dua M, Aggarwal RK, Biswas M (2019a) Discriminatively trained continuous Hindi speech recognition system using interpolated recurrent neural network language modeling. Neural Comput & Applic 31(10):6747–6755
Dua M, Aggarwal RK, Biswas M (2019b) GFCC based discriminatively trained noise robust continuous ASR system for Hindi language. J Ambient Intell Humaniz Comput 10(6):2301–2314. https://doi.org/10.1007/s12652-018-0828-x
Dua M, Aggarwal RK, Kadyan V, Dua S (2012) Punjabi automatic speech recognition using HTK. Int J Comput Sci Issues (IJCSI) 9(4):359
Forsberg M (2003) Why is speech recognition difficult. Chalmers University of Technology
Geng M, Xie X, Liu S, Yu J, Hu S, Liu X, Meng H (2020) Investigation of data augmentation techniques for disordered speech recognition. Proc. Interspeech 696–700. https://doi.org/10.21437/Interspeech.2020-1161
Gerosa M, Giuliani D, Brugnara F (2007) Acoustic variability and automatic recognition of children’s speech. Speech Comm 49(10–11):847–860. https://doi.org/10.1016/j.specom.2007.01.002
Ghahremani P, BabaAli B, Povey D, Riedhammer K, Trmal J, Khudanpur S (2014) A pitch extraction algorithm tuned for automatic speech recognition. In 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE 2494–2498. https://doi.org/10.1109/ICASSP.2014.6854049
Goyal K, Singh A, Kadyan V (2021) A comparison of laryngeal effect in the dialects of Punjabi language. J Ambient Intell Human Comput. https://doi.org/10.1007/s12652-021-03235-4
Hakak S, Alazab M, Khan S, Gadekallu TR, Maddikunta PKR, Khan WZ (2021) An ensemble machine learning approach through effective feature extraction to classify fake news. Futur Gener Comput Syst 117:47–58
Jaitly N, Hinton GE (2013, June) Vocal tract length perturbation (VTLP) improves speech recognition. In Proc. ICML workshop on deep learning for audio, speech and language (Vol. 117).
Kadyan V, Mantri A, Aggarwal RK (2017) A heterogeneous speech feature vectors generation approach with hybrid hmm classifiers. Int J Speech Technol 20:761–769. https://doi.org/10.1007/s10772-017-9446-9
Kadyan V, Mantri A, Aggarwal RK, Singh A (2019) A comparative study of deep neural network based Punjabi-ASR system. Int J Speech Technol 22(1):111–119. https://doi.org/10.1007/s10772-018-09577-3
Kadyan V (2018) Acoustic features optimization for Punjabi automatic speech recognition system. PhD diss. Chitkara University
Kathania HK, Kadiri SR, Alku P, Kurimo M (2020) Study of formant modification for children ASR. In ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE 7429–7433. https://doi.org/10.1109/ICASSP40776.2020.9053334
Kathania HK, Shahnawazuddin S, Adiga N, Ahmad W (2018) Role of prosodic features on children's speech recognition. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE 5519–5523. https://doi.org/10.1109/ICASSP.2018.8461668
Kaur A, Singh A (2016a) Power-normalized cepstral coefficients (PNCC) for Punjabi automatic speech recognition using phone based modelling in HTK, second international conference on applied and theoretical computing and communication technology. IEEE Explore, ICATCCT2016, Bengaluru.
Kaur A, Singh A (2016b) Optimizing feature extraction techniques constituting phone based modelling on connected words for Punjabi automatic speech recognition, communicated in 5th International Conference on Advances in Computing, Communications and Informatics, IEEE Explore, ICACCI-2016, Jaipur
Kaur H, Kadyan V. (2020) Feature space discriminatively trained Punjabi children speech recognition system using Kaldi toolkit. Available at SSRN 3565906.
Kaur J, Singh A, Kadyan V (2020) Automatic speech recognition system for tonal languages: state-of-the-art survey. Archives of Computational Methods in Engineering:1–30. https://doi.org/10.1007/s11831-020-09414-4
Ko T, Peddinti V, Povey D, Khudanpur S (2015) Audio augmentation for speech recognition. In Sixteenth Annual Conference of the International Speech Communication Association.
Ko T, Peddinti V, Povey D et al (2017) A study on data augmentation of reverberant speech for robust speech recognition. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 5220–5224. https://doi.org/10.1109/ICASSP.2017.7953152
Kumar Y, Singh N, Kumar M, Singh A (2021) AutoSSR: an efficient approach for automatic spontaneous speech recognition model for the Punjabi language. Soft Comput 25:1617–1630. https://doi.org/10.1007/s00500-020-05248-1
Kwon O, Jang I, Ahn C, Kang HG (2019) Emotional speech synthesis based on style embedded Tacotron2 framework. In 2019 34th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC). IEEE, 1–4. https://doi.org/10.1109/ITC-CSCC.2019.8793393
Lata S, Arora S (2012, May) Exploratory analysis of Punjabi tones in relation to orthographic characters: a case study. In Workshop on Indian Language and Data: Resources and Evaluation Workshop programme 76
Lata S, Arora S (2013, August) Laryngeal tonal characteristics of Punjabi—an experimental study. In 2013 International Conference on Human Computer Interactions (ICHCI). IEEE, 1–6 https://doi.org/10.1109/ICHCI-IEEE.2013.6887793
Lee S, Potamianos A, Narayanan S (1999) Acoustics of children’s speech: developmental changes of temporal and spectral parameters. The Journal of the Acoustical Society of America 105(3):1455–1468. https://doi.org/10.1121/1.426686
Lei X, Siu M, Hwang MY et al (2006) Improved tone modeling for mandarin broadcast news speech recognition. In Ninth International Conference on Spoken Language Processing
Li C, Qian Y (2019) Prosody usage optimization for children speech recognition with zero resource children speech. In Interspeech 3446–3450. https://doi.org/10.21437/Interspeech.2019-2659
Li X, Wu X (2015) Modeling speaker variability using long short-term memory networks for speech recognition. In Sixteenth Annual Conference of the International Speech Communication Association.
Litman DJ, Hirschberg JB, Swerts M (2000) Predicting automatic speech recognition performance using prosodic cues, Proc. 1st North Am. Chapter Assoc. Comput. Linguist. Conf. 218–225 [Online]. Available: http://dl.acm.org/citation.cfm?id=974305.974334.
Long Y, Li Y, Zhang Q, Wei S, Ye H, Yang J (2020) Acoustic data augmentation for mandarin-English code-switching speech recognition. Appl Acoust 161:107175. https://doi.org/10.1016/j.apacoust.2019.107175
Mary L, Yegnanarayana B (2008) Extraction and representation of prosodic features for language and speaker recognition. Speech Comm 50(10):782–796. https://doi.org/10.1016/j.specom.2008.04.010
Milde B, Köhn A (2018) Open source automatic speech recognition for German. In Speech Communication; 13th ITG-Symposium 1–5 VDE
Nguyen TS, Stueker S, Niehues J, et al (2020) Improving sequence-to-sequence speech recognition training with on-the-fly data augmentation. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. 7689–7693 https://doi.org/10.1109/ICASSP40776.2020.9054130
Passricha V, Aggarwal RK (2020) A comparative analysis of pooling strategies for convolutional neural network based Hindi ASR. J Ambient Intell Humaniz Comput 11(2):675–691. https://doi.org/10.1007/s12652-019-01325-y
Povey D, Ghoshal A, Boulianne G et al(2011) The Kaldi speech recognition toolkit. In IEEE 2011 workshop on automatic speech recognition and understanding (No. CONF). IEEE Signal Processing Society
Rafi MS (2010) Semantic variations of Punjabi Toneme. Lang India 10(8):56–65 http://hdl.handle.net/123456789/543
Ravinder K (2010) Comparison of hmm and dtw for isolated word recognition system of Punjabi language. In Iberoamerican Congress on Pattern Recognition. Springer, Heidelberg. 244–252 https://doi.org/10.1007/978-3-642-16687-7_35
Rose R, Yin SC, Tang Y (2011) An investigation of subspace modeling for phonetic and speaker variability in automatic speech recognition. In 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. 4508–4511. https://doi.org/10.1109/ICASSP.2011.5947356
Rostami M, Berahmand K, Forouzandeh S (2020) A novel method of constrained feature selection by the measurement of pairwise constraints uncertainty. J Big Data 7(1):1–21
Rostami M, Berahmand K, Forouzandeh S (2021) A novel community detection based genetic algorithm for feature selection. J Big Data 8(1):1–27
Shahnawazuddin S, Adiga N, Kathania HK (2017) Effect of prosody modification on children's ASR. IEEE Signal Processing Letters 24(11):1749–1753. https://doi.org/10.1109/LSP.2017.2756347
Shahnawazuddin S, Adiga N, Kathania HK, Sai BT (2020a) Creating speaker independent ASR system through prosody modification based data augmentation. Pattern Recogn Lett 131:213–218. https://doi.org/10.1016/j.patrec.2019.12.019
Shahnawazuddin S, Adiga N, Kumar K et al (2020b). Voice conversion based data augmentation to improve Children’s speech recognition in limited data scenario. Proc. Interspeech 2020, 4382–4386. https://doi.org/10.21437/Interspeech.2020-1112
Shahnawazuddin S, Adiga N, Sai BT, Ahmad W, Kathania HK (2019) Developing speaker independent ASR system using limited data through prosody modification based on fuzzy classification of spectral bins. Digital Signal Processing 93:34–42. https://doi.org/10.1016/j.dsp.2019.06.015
Shahnawazuddin S, Ahmad W, Adiga N, Kumar A (2020c,) In-domain and out-of-domain data augmentation to improve Children’s speaker verification system in limited data scenario. In ICASSP 2020-2020 IEEE international conference on acoustics, speech and signal processing (ICASSP). 7554–7558. IEEE. https://doi.org/10.1109/ICASSP40776.2020.9053891
Shahnawazuddin S, Kathania HK, Dey A, Sinha R (2018) Improving children’s mismatched ASR using structured low-rank feature projection. Speech Comm 105:103–113. https://doi.org/10.1016/j.specom.2018.11.001
Shivakumar PG, Georgiou P (2020) Transfer learning from adult to children for speech recognition: evaluation, analysis and recommendations. Comput Speech Lang 63:101077
Shriberg E, Ferrer L, Kajarekar S et al (2005) Modeling prosodic feature sequences for speaker recognition. Speech Commun 46(3–4):455–472. https://doi.org/10.1016/j.specom.2005.02.018
Singh A, Kadyan V, Kumar M, Bassan N (2019) ASRoIL: a comprehensive survey for automatic speech recognition of Indian languages. Artif Intell Rev 53:1–32. https://doi.org/10.1007/s10462-019-09775-8
Singh A, Kaur N, Kukreja V et al (2022) Computational intelligence in processing of speech acoustics: a survey. Complex Intell Syst 8(2623):2661 https://doi.org/10.1007/s40747-022-00665-1
Talkin D, Kleijn WB (1995) A robust algorithm for pitch tracking (RAPT). Speech coding and synthesis 495:518
Taniya, Bhardwaj V, Kadyan V (2020) Deep neural network trained Punjabi children speech recognition system using Kaldi toolkit. In 2020 IEEE 5th international conference on computing communication and automation (ICCCA) (pp. 374-378). IEEE
Teixeira JP, Oliveira C, Lopes C (2013) Vocal acoustic analysis–jitter, shimmer and hnr parameters. Procedia Technology 9:1112–1122. https://doi.org/10.1016/j.protcy.2013.12.124
Ten Bosch L (2003) Emotions, speech and the ASR framework. Speech Comm 40(1–2):213–225. https://doi.org/10.1016/S0167-6393(02)00083-3
Wang L, Ambikairajah E, Choi EH (2006) Automatic tonal and non-tonal language classification and language identification using prosodic information. In International Symposium on Chinese Spoken language Processing. (ISCSLP) 485–496
Wang L, Ambikairajah E, Choi EH (2007a,) A novel method for automatic tonal and non-tonal language classification. In 2007 IEEE International Conference on Multimedia and Expo. IEEE. 352–355. https://doi.org/10.1109/ICME.2007.4284659
Wang L, Ambikairajah E, Choi EH (2007b) Automatic language recognition with tonal and non-tonal language pre-classification. In 2007 15th European Signal Processing Conference 2375–2379. IEEE.
Yadav IC, Shahnawazuddin S, Pradhan G (2019) Addressing noise and pitch sensitivity of speech recognition system through variational mode decomposition based spectral smoothing. Digital Signal Processing 86:55–64. https://doi.org/10.1016/j.dsp.2018.12.013
Yeung G, Alwan A (2018) On the difficulties of automatic speech recognition for kindergarten-aged children. In INTERSPEECH 1661–1665. https://doi.org/10.21437/Interspeech.2018-2297
Zehra W, Javed AR, Jalil Z et al (2021) Cross corpus multi-lingual speech emotion recognition using ensemble learning. Complex and Intelligent Systems 7:1–10
Zhang JS, Hirose K (2000) Anchoring hypothesis and its application to tone recognition of Chinese continuous speech. In 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 00CH37100). IEEE. 3:1419–1422. https://doi.org/10.1109/ICASSP.2000.861859
Zhao X, Wang D (2013) Analyzing noise robustness of MFCC and GFCC features in speaker identification. In 2013 IEEE international conference on acoustics, speech and signal processing 7204–7208. IEEE. https://doi.org/10.1109/ICASSP.2013.6639061
Zhu W, O'Shaughnessy D (2004) Incorporating frequency masking filtering in a standard MFCC feature extraction algorithm. In Proceedings 7th International Conference on Signal Processing, 2004. Proceedings. ICSP'04. 2004. IEEE. 1:617–620. https://doi.org/10.1109/ICOSP.2004.1452739
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We have no conflict of interest to declare.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kadyan, V., Hasija, T. & Singh, A. Prosody features based low resource Punjabi children ASR and T-NT classifier using data augmentation. Multimed Tools Appl 82, 3973–3994 (2023). https://doi.org/10.1007/s11042-022-13435-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-13435-5