
Abstract
Political optimizer (PO) is a recently proposed human-behavior inspired meta-heuristic, which has shown tremendous performance on complex multimodal functions as well as engineering optimization problems. Good convergence speed and well-balanced exploratory and exploitative behavior of PO convince us to employ PO for the training of feedforward neural network (FNN). The FNN-training problem is formulated as an optimization problem in which the objective is to minimize the mean squared error (MSE) or cross entropy (CE). The weights and biases of the FNN are arranged in the form of a vector called a candidate solution. The performance of the proposed trainer is evaluated on 5 classification data-sets and 5 function-approximation data-sets, which have already been used in the literature. In recent years, grey wolf optimizer, moth flame optimization, multi-verse optimizer, sine-cosine algorithm, whale optimization algorithm, ant lion optimizer, and Salp swarm algorithm have successfully been applied on neural network training. In this paper, we compare the performance of PO with these algorithms and show that PO either outperforms them or performs equivalently. The MSE, CE, training set accuracy, and test set accuracy are used as metrics for the comparative analysis. The non-parametric Wilcoxon’s rank-sum test is used to show the statistical significance of the results. Based on the tremendous performance, we highly recommend using PO for the training of artificial neural networks to solve the classification and regression problems.




















Similar content being viewed by others


References
McCulloch WS, Pitts W (1943) A logical calculus of the ideas immanent in nervous activity. Bull Math Biophys 5(4):115–133
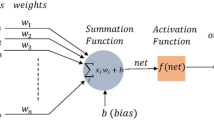
Bebis G, Georgiopoulos M (1994) Feed-forward neural networks. IEEE Potentials 13(4):27–31
Dorffner G (1996) Neural networks for time series processing. Neural Network World 6:447–468
Lawrence S, Giles CL, Tsoi AC, Back AD (1997) Face recognition: a convolutional neural-network approach. IEEE Trans Neural Netw 8(1):98–113
Park J, Sandberg I (1993) Neural computations. Approx Radial Basisfunct Netw 5(2):305–316
Kohonen T (1990) The self-organizing map. Proc IEEE 78(9):1464–1480
Rumelhart DE, Hinton GE, Williams RJ (1985) Learning internal representations by error propagation, Tech. rep., California Univ San Diego La Jolla Inst for Cognitive Science
Hestenes MR, Stiefel E et al (1952) Methods of conjugate gradients for solving linear systems. J Res Natl Bur Stand 49(6):409–436
Chen O-C, Sheu BJ (1994) Optimization schemes for neural network training. In: Proceedings of 1994 IEEE international conference on neural networks (ICNN’94), vol 2. IEEE, pp 817–822
Bertsekas DP (1997) Nonlinear programming. J Oper Res Soc 48(3):334
Marquardt DW (1963) An algorithm for least-squares estimation of nonlinear parameters. J Soc Ind Appl Math 11(2):431–441
Sexton RS, Dorsey RE, Johnson JD (1998) Toward global optimization of neural networks: a comparison of the genetic algorithm and backpropagation. Decis Support Syst 22(2):171–185
Ojha VK, Abraham A, Snášel V (2017) Metaheuristic design of feedforward neural networks: a review of two decades of research. Eng Appl Artif Intell 60:97–116
Bianchi L, Dorigo M, Gambardella LM, Gutjahr WJ (2008) A survey on metaheuristics for stochastic combinatorial optimization. Nat Comput 8(2):239–287
Blum C, Roli A (2003) Metaheuristics in combinatorial optimization: overview and conceptual comparison. ACM Comput Surv (CSUR) 35(3):268–308
Holland JH (1992) Genetic algorithms. Sci Am 267(1):66–73
Simon D (2008) Biogeography-based optimization. IEEE Trans Evol Comput 12(6):702–713
Kennedy J, Eberhart R (1995) Particle swarm optimization. In: Proceedings of ICNN’95—international conference on neural networks, vol 4. IEEE, pp 1942–1948
Dorigo M, Caro GD (1999) Ant colony optimization: a new meta-heuristic. In:Proceedings of the 1999 congress on evolutionary computation-CEC99 (Cat. No. 99TH8406), vol 2. IEEE, pp 1470–1477
Rashedi E, Nezamabadi-pour H, Saryazdi S (2009) GSA: A gravitational search algorithm. Inf Sci 179(13):2232–2248
Kirkpatrick S, Gelatt CD, Vecchi MP (1983) Optimization by simulated annealing. Science 220(4598):671–680
Rao R, Savsani V, Vakharia D (2011) Teaching–learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput Aided Des 43(3):303–315
Askari Q, Saeed M, Younas I (2020) Heap-based optimizer inspired by corporate rank hierarchy for global optimization. Expert Syst Appl 161:113702
Wolpert David H, Macready William G (1997) No free lunch theorems for optimization. IEEE Trans Evol Comput 1(1):67–82
Montana DJ, Davis L (1989) Training feedforward neural networks using genetic algorithms. In: IJCAI, vol 89. pp 762–767
Mendes R, Cortez P, Rocha M, Neves J (2002) Particle swarms for feedforward neural network training. In: Proceedings of the 2002 international joint conference on neural networks. IJCNN’02 (Cat. No. 02CH37290), vol 2. IEEE, pp 1895–1899
Lampinen J, Storn R (2004) Differential evolution. In: Newoptimization techniques in engineering. Springer, Berlin, Heidelberg, pp 123–166
Slowik A, Bialko M (2008) Training of artificial neural networks using differential evolution algorithm. In: Conference on human system interactions. IEEE, pp 60–65
Mirjalili S (2015) How effective is the grey wolf optimizer in training multi-layer perceptrons. Appl Intell 43(1):150–161
Aljarah I, Faris H, Mirjalili S (2018) Optimizing connection weights in neural networks using the whale optimization algorithm. Soft Comput 22(1):1–15
Faris H, Aljarah I, Mirjalili S (2016) Training feedforward neural networks using multi-verse optimizer for binary classification problems. Appl Intell 45(2):322–332
Yamany W, Fawzy M, Tharwat A, Hassanien AE (2015) Moth-flame optimization for training multi-layer perceptrons. In:11th International computer engineering conference (ICENCO). IEEE, pp 267–272
Yan X, Yang W, Shi H (2012) A group search optimization based on improved small world and its application on neural network training in ammonia synthesis. Neurocomputing 97:94–107
Mirjalili S, Mirjalili SM, Lewis A (2014) Let a biogeography-based optimizer train your multi-layer perceptron. Inf Sci 269:188–209
Wu H, Zhou Y, Luo Q, Basset MA (2016) Training feedforward neural networks using symbiotic organisms search algorithm. Comput Intell Neurosci 2016:14
Mirjalili S, Sadiq AS (2011) Magnetic optimization algorithm for training multi layer perceptron. In: 2011 IEEE 3rd international conference on communication software and networks. IEEE, pp 42–46
Faris H, Aljarah I, Mirjalili S (2018) Improved monarch butterfly optimization for unconstrained global search and neural network training. Appl Intell 48(2):445–464
Wang L, Zou F, Hei X, Yang D, Chen D, Jiang Q (2014) An improved teaching-learning-based optimization with neighborhood search for applications of ANN. Neurocomputing 143:231–247
Zhao R, Wang Y, Hu P, Jelodar H, Yuan C, Li Y, Masood I, Rabbani M (2019) Selfish herds optimization algorithm with orthogonal design and information update for training multi-layer perceptron neural network. Appl Intell 49(6):2339–2381
Heidari AA, Faris H, Aljarah I, Mirjalili S (2019) An efficient hybrid multilayer perceptron neural network with grasshopper optimization. Soft Comput 23(17):7941–7958
Tang R, Fong S, Deb S, Vasilakos AV, Millham RC (2018) Dynamic group optimisation algorithm for training feed-forward neural networks. Neurocomputing 314:1–19
Mirjalili S, Hashim SZM, Sardroudi HM (2012) Training feedforward neural networks using hybrid particle swarm optimization and gravitational search algorithm. Appl Math Comput 218(22):11125–11137
Nayak J, Naik B, Behera H (2016) A novel nature inspired firefly algorithm with higher order neural network: performance analysis. Eng Sci Technol Int J 19(1):197–211
Valian E, Mohanna S, Tavakoli S (2011) Improved cuckoo search algorithm for feedforward neural network training. Int J Artif Intell Appl 2(3):36–43
Kowalski PA, Łukasik S (2016) Training neural networks with krill herd algorithm. Neural Process Lett 44(1):5–17
Liu T, Liang S, Xiong Q, Wang K (2019) Integrated CS optimization and OLS for recurrent neural network in modeling microwave thermal process. Neural Comput Appl 32(16):12267–12280
Chen S, Hong X, Harris CJ (2010) Particle swarm optimization aided orthogonal forward regression for unified data modeling. IEEE Trans Evol Comput 14(4):477–499
Sun Y, Xue B, Zhang M, Yen GG, Lv J (2020) Automatically designing cnn architectures using the genetic algorithm for image classification. IEEE Trans Cybern 50:3840–3854
Kapanova K, Dimov I, Sellier J (2018) A genetic approach to automatic neural network architecture optimization. Neural Comput Appl 29(5):1481–1492
Faris H, Mirjalili S, Aljarah I (2019) Automatic selection of hidden neurons and weights in neural networks using grey wolf optimizer based on a hybrid encoding scheme. Int J Mach Learn Cybern 10(10):2901–2920
Stanley KO, Clune J, Lehman J, Miikkulainen R (2019) Designing neural networks through neuroevolution. Nat Mach Intell 1(1):24–35
Huang C, Zhang H (2019) Periodicity of non-autonomous inertial neural networks involving proportional delays and non-reduced order method. Int J Biomath 12(02):1950016
Wang W (2018) Finite-time synchronization for a class of fuzzy cellular neural networks with time-varying coefficients and proportional delays. Fuzzy Sets Syst 338:40–49
Zhang J, Huang C (2020) Dynamics analysis on a class of delayed neural networks involving inertial terms. Adv Differ Equ 2020(1):1–12
Rajchakit G, Pratap A, Raja R, Cao J, Alzabut J, Huang C (2019) Hybrid control scheme for projective lag synchronization of Riemann–Liouville sense fractional order memristive BAM neuralnetworks with mixed delays. Mathematics 7(8):759
Zhang H, Qian C (2020) Convergence analysis on inertial proportional delayed neural networks. Adv Differ Equ 2020(1):1–10
Bohat VK, Arya K (2018) An effective gbest-guided gravitational search algorithm for real-parameter optimization and its application in training of feedforward neural networks. Knowl-Based Syst 143:192–207
Askari Q, Younas I, Saeed M (2020) Political optimizer: a novel socio-inspired meta-heuristic for global optimization. Knowl Based Syst 195:105709
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Askari, Q., Younas, I. Political Optimizer Based Feedforward Neural Network for Classification and Function Approximation. Neural Process Lett 53, 429–458 (2021). https://doi.org/10.1007/s11063-020-10406-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-020-10406-5