
Abstract
In this paper, we design a novel hybrid remote display for mobile thin-client system. The remote frame buffer (RFB) protocol and motion JPEG (M-JPEG) protocol are assigned to handle remote display tasks in the slow-motion region and high-motion region, respectively. Graphic processing units (GPU) are utilized to do a part of a real-time JPEG compression task. A novel quality of experience (QoE)-based high-motion detection algorithm is also proposed to reduce the network bandwidth consumption and the server-side computing resource consumption. The continuity of screen delivery remains whenever the JPEG compression is applied to different screen regions. The proposed hybrid remote display approach has many good features which have been justified by comprehensive simulation studies.
Similar content being viewed by others

1 Introduction
Nowadays, the rapid development of mobile network and device promotes the investigation of mobile services. During the last decade, the processing power of mobile (smartphone) and portable devices (laptop, tablet PC) has been greatly improved. Despite the advances in mobile hardware and local application, the remote mobile services delivered through thin-client computing still is gaining particular interest in research and development of mobile context. According to [1], the first advantage of mobile thin-client computing is that applications need not to be tailored individually for each mobile platform. It has the potential to break the device-specific/OS-specific barrier for mobile and PC applications. Secondly, the mobile thin computing technology handles the “heterogeneous degree of capability” problem for mobile and portable devices. For example, mobile phones still cannot provide enough local processing and storage resources to execute 3D virtual environments that require advanced graphical hardware [2], or applications that operate on large data sets, such as medical imaging application [3]. Although the portable devices may have enough capability to process 3D tasks locally, the battery consumption limits the performance and service time.
Using thin-client computing, users are able to remotely access their services via a local viewer application and delegate actual information processing to the remote server. The viewer application transfers user input to the server, and renders the display updates received from the server. Many types of thin-client technologies have mobile client versions for different mobile devices such as Microsoft Remote Desktop Services (RDP) [4], and Virtual Network Computing (VNC) [5]. However, the current technologies did not provide an efficient and widely applicable remote display solution for mobile thin-client computing.
All existing remote display solutions can be roughly categorized into structured and pixel-based encoding. In the structured encoding domain, the remote display server intercepts elementary drawing commands from application/OS/graphic card, translates them to a format that is executable on the client device, and sends the translated instructions to the client. The instructions are then received by the client, and executed on the client device to generate screen display. Citrix XenApp [6], Windows RDP [4], THINC [7], and MPEG-4 BiFS semantic remote display framework [1] belong to this category. The above solutions perform well supporting only a limited range of applications or OS since most of them (expect THINC) need application/OS level structure information, which is usually inaccessible for an external application, such as the encoder application. Besides, these solutions require client-side hardware support to execute 3D virtual environment even if the 3D structure information is available. Thus, the structured encoding technologies are not widely applicable on both server and client side.
On the other hand, the pixel-based encoding solutions are more general as compared to the structured encoding. The remote display server intercepts the screen pixels from the hardware framebuffer, encodes the screen updates with different compression techniques, and sends the encoded screen updates to the client. Due to the variety of compression techniques, the performances of existing pixel-based encoding solutions differ from each other. The original VNC, which adopts RFB as the encoding technique, suffers from high bandwidth consumption when transmitting high-motion screen updates. As the RFB protocol provides no adequate solution to support pixel-based encoding, the existing works [8, 9] divide the display in slow- and high-motion regions, which are encoded, respectively, by means of VNC drawing primitives and MPEG-4 AVC (a.k.a. H.264) frames. This solution fully eliminates the high bandwidth consumption problem caused by VNC encoding. However, the MPEG decoding still results in high computing resource consumption on the client device. Meanwhile, the motion detection approach is not fully optimized since the switch from RFB to MPEG cannot be done transparently.
RFB-based JPEG compression technology was used in TightVNC [10] and TurboVNC [11] to reduce the consumption of bandwidth and client CPU. They use JPEG compression to encode the difference between the neighbor frames rather than the frame itself. If JPEG compression is applied to each frame, the whole process can be viewed as Motion JPEG (M-JPEG) encoding process. According to [12], M-JPEG has the following advantages: (i) minimum latency in image processing, and (ii) flexibility of splicing and resizing. Even if few network packets containing the frame information have been lost during the transmission, M-JPEG can still provide continuous streaming while the RFB-based JPEG compression technology may not be able to work properly. Besides, the existing thin-client applications using JPEG-based remote display protocol face the low frame rate problem since real-time JPEG encoding is a challenging task for CPU. The experiments in [13] show that it is impossible to guarantee 20–30 frames per second large screen JPEG compression without using parallel processing units.
In this paper, we propose a novel hybrid remote display design for the mobile thin-client system. The RFB protocol is chosen to handle the slow-motion remote display task. We adopt M-JPEG as our protocol for high-motion display. To further improve the encoding efficiency and reduce the response time, graphic processing units (GPU) have been utilized to do a part of JPEG compression task. We install a NVIDIA graphic card and NVIDIA CUDA, which is a parallel computing platform and programming model, enabling dramatic increases in computing performance by harnessing the power of the GPU [14]. By using GPU-assisted M-JPEG compression, our remote display system is capable of providing real-time M-JPEG streaming with low latency and high frame rate, which is considered as the first contribution of this paper.
The second contribution is that the motion detection algorithm in our display protocol is able to reduce the network bandwidth consumption and the server-side computing resource consumption. As the M-JPEG is an intra-frame approach, the resizing and slicing of the M-JPEG frames can be done transparently. Whenever the motion detection algorithm changes the size or position of the high-motion region, the continuity of screen delivery is always preserved. Our proposed algorithm can detect several high-motion regions with the consideration of the following factors: (i) the number of changed pixels, (ii) the network environment, (iii) the resource utilization situation on server side, and (iv) the video quality preference from the client side. The motion detection algorithm first assigns each 8∗8 display region a QoE value showing that how much the M-JPEG compression outperforms RFB encoding regarding that region. Then, the QoE values are used to form a QoE matrix, and the high-motion region detection problem is solved by using a dynamic programming algorithm to get the sub-matrix with maximum summation.
We also present a four-module-four-thread implementation method. The multi-thread design greatly reduces the whole compression time by running tasks in parallel among memory, CPU, GPU, and Network I/O. The proposed display technology with novel motion detection algorithm is compared with existing solutions. The experimental results are demonstrated to support the claims.
The rest of this paper is organized as follows. Section 2 discusses some related work in the thin-client domain. The description of the proposed hybrid remote display protocol can be found in Sect. 3. Section 4 contains the details of the motion detection algorithm. We show our implementation method and some performance results in Sect. 5 and conclude with suggestions for future work in Sect. 6.
2 Related work
Based on the position of interception, the remote display protocols can be categorized into three distinctive groups. At application/OS layer, Microsoft RDP [4] is a well-known and widely used solution developed by Microsoft, which concerns providing a user with a graphical interface to another computer. RDP clients exist for most versions of Microsoft Windows (including Windows Mobile), Linux, Unix, Mac OS X, Android, and other modern operating systems. RemoteFX [15] is integrated with the Remote Desktop Protocol, which allows graphics to be rendered on the host device instead of on the client device. GPU virtualization in RemoteFX allows multiple virtual desktops to share a single GPU on a Hyper-V server.
At device driver layer, THINC uses its virtual device driver to intercept display output in an application and OS agnostic manner [7]. It efficiently translates high-level application display requests to low-level protocol primitives and achieves efficient network usage. Most display protocols working in application/OS layer or device driver layer can be viewed as structured encoding approach. The advantages of those approaches include efficient bandwidth consumption and a low response time. However, those works are not suitable for a mobile thin-client environment since they require many hardware supports from the client-side device. The mobile devices have heterogeneous degrees of hardware capability, and those cheap devices only have limited computing and graphic resources to handle display tasks. The existing structured encoding approaches cannot bridge this gap between functionality demand and available resources on mobile devices. Meanwhile, the low bandwidth consumption cannot be achieved if the structure information is not available, which makes those solutions proprietary.
At the hardware frame buffer layer, the basic principle is to reduce everything to raw pixel values for representing display updates, then read the pixel data from the frame buffer and encode or compress it, a process sometimes called screen scraping. VNC [5] and GoToMyPC [16] are two actively developed and widely used systems based on this approach. Other similar solutions are Laplink [17] and PC Anywhere [18], which have been previously shown to perform poorly [19]. Screen scraping is relatively general and decouples the processing of application display commands from the generation of display updates sent to the client. Servers need to do the full translation from application display commands to actual pixel data. As a benefit, clients can be very simple and stateless. However, display commands consisting of raw pixels alone are typically too bandwidth intensive to mobile devices. For example, using raw pixels to encode display updates for a video player displaying at 30 frames per second (fps) a full-screen video clip on a typical 1024×768 24-bit resolution screen would require over 0.5 Gbps of network bandwidth. Thus, the raw pixel data must be compressed. Many compression techniques have been developed for this purpose.
Several extended versions of VNC exist, differing in the applied coding on these rectangles. Previous measurements have designated the TurboVNC coding as the most bandwidth efficient [20]. A RFB-based JPEG encoding technique has been developed and adopted in TurboVNC. The drawback of RFB-based protocol is that the performance degrades significantly in poor network environment. For the streaming mode, the well-known H.264 codec [21] was selected, transported over the Real-time Transport Protocol (RTP) [22]. In [8], the authors introduced the idea of a real-time desktop streamer using the H.264 video codec to stream the graphical output of applications after GPU processing to a thin-client device. H.264/AVC supports variable block size, multiple reference frames, and quarter sample accuracy motion estimation, but this causes a long response time and high client CPU consumption.
3 Proposed hybrid remote display protocol
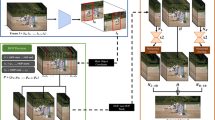
One of the core requirements of remote display is the ability to efficiently compress server-side screen images so that they can be transported over a network and displayed on a client screen. Any codec used for this purpose needs to be able to deliver effective compression (to reduce network bandwidth requirements) and operate with low latency (to enable efficient interactions with remote application). We propose a hybrid remote display protocol using a combination of a classic thin-client protocol RFB and M-JPEG to send the graphical output of an application to a thin-client device. Figure 1 gives a schematic overview of such architecture at the server. The graphic updates are hooked from the graphic card hardware frame buffer. The motion detector will divide the whole screen into a slow-motion region and high-motion region. A high-motion detection should happen in a transparent way for the end-user since applications must not be modified to be used in this thin-client architecture. When the detection result of a display region is slow-motion, the RFB module will be used as the remote display protocol since it consumes less resource at the server. For high-motion regions, the M-JPEG module is responsible for real-time encoding. After packetizing, the network transmission protocol will be applied to send the encoded M-JPEG and RFB data.

Architecture of a hybrid remote display protocol at the server
We also explore the potential performance improvements that could be gained through the use GPU-processing techniques within the CUDA [14] architecture for JPEG compression algorithm. Since JPEG compression is a computing intensive task that can be slow on current CPUs, using CPU codec will cause a long delay due to the long compression time.
JPEG image compression differs from sound or file compression because image sizes are typically in the range of megabytes, which means that the working set will usually fit in the size of device global memory of GPUs. Unlike larger files, which usually will require some form of streaming of data to and from the GPU, JPEG compression needs only a few memory copies to and from the device, reducing the required GPU memory bandwidth and overhead. Moreover, the independent nature of the pixels and blocks automatically leads to data level parallelism in CUDA. Because of these two factors, JPEG compression can take advantage of CUDA’s massive parallelism. With the help of GPU, the JPEG compression time can be greatly reduced to a reasonable level.
Figure 2 shows the flow diagram of JPEG compression using both GPU and CPU. As we can see, the color space transformation, discrete cosine transform, adaptive quantization and “zigzag” ordering are assigned to GPU since those tasks consists of many independent computing tasks which match with the data level parallelism feature in GPU. By contrast, the run-length encoding and Huffman coding contains lots of branches. Handling branches will cause significant inefficiency since the codes in every branch need to be executed by CUDA. Thus, we assign the last two parts to CPU. Besides, there also exists a parallelism between GPU and CPU. For example, CPU can process the run-length encoding and Huffman coding tasks for the first frame when GPU is processing the color space transformation, discrete cosine transform, adaptive quantization, and “zigzag” ordering tasks for the second one.

Flow diagram of JPEG compression
The adaptive quantization is a special component in JPEG compression algorithm. We prepare several quantization tables to achieve different compression ratios. Based on the capacity of client’s network or the user preference, the compression ratio can be varied dynamically. With this feature, our thin-client protocol can guarantee the quality of video, meaning that client can always receive fluent screen images regardless of an unstable network situation.
4 Motion detection approach
The main task of our motion detection approach is to separate slow- and high-motion screen regions. Since we apply RFB encoding and JPEG encoding to slow-motion region and high-motion region, respectively, the decision of motion detection should be made with the consideration of two factors: server resource and network bandwidth consumed by each encoding method. We also consider the current server resource condition and network environment which can be potential constraints. The user is allowed to set a subjective parameter to describe the desired quality of M-JPEG stream. The objective parameters involved in the decision process include the server hardware/software environment and the number of changed pixels. After collecting the parameters, the high-motion detection process is formulated as an optimization problem. In order to provide a real-time solution, we adopt dynamic programming algorithm to reduce the computational complexity. The overall process of our motion detection solution is presented in Fig. 3, and the details can be found in the following sub-sections.

Proposed Motion Detection Approach
4.1 QoE difference value
As we can see in Fig. 3, the first step of motion detection is to divide the whole screen display area into several 8∗8 small rectangles. For each 8∗8 screen region, a QoE value needs to be calculated, showing how much the JPEG encoding outperforms the RFB encoding. The advantage of RFB encoding is that it is a light-weight technology in terms of server resource consumption. On the other hand, the JPEG encoding consumes considerable amount of CPU and GPU resources while compressing the screen update. It makes RFB encoding a consistently better solution with respect to server resource consumption. In addition, the client-side decoding complexity has a similar feature where the RFB decoding consumes slightly less CPU resource as compare to the JPEG decoding.
For the simplicity of calculation and explanation, all parameters regarding resource consumption and situation are defined in percentage form. Let \(C_{\mathit{RFB}} = (c_{\mathit{RFB\_ij}})\) be the CPU resource consumption matrix over RFB encoding where \(c_{\mathit{RFB\_ij}}\) is defined as the CPU overhead for handling the ij th 8∗8 region provided that RFB encoding is used; let \(C_{\mathit{JPEG}} = (c_{\mathit{JPEG\_ij}})\) be the CPU resource consumption matrix over JPEG encoding where \(c_{\mathit{JPEG\_ij}}\) is defined as the CPU overhead for handling the ij th 8∗8 region provided that JPEG encoding is used; and let \(G_{\mathit{JPEG}} = (g_{\mathit{JPEG\_ij}})\) be the GPU resource consumption matrix over JPEG encoding where \(g_{\mathit{JPEG\_ij}}\) is defined as the GPU overhead for handling the ij th 8×8 region provided that JPEG encoding is used. Given a hardware/software environment including hardware configuration, OS, and CUDA version, the value of \(\sum_{i,j} c_{\mathit{RFB\_ij}}\), \(\sum_{i,j} c_{\mathit{JPEG\_ij}}\), \(\sum_{i,j} g_{\mathit{JPEG\_ij}}\) can be obtained by applying RFB or JPEG to the whole screen region as benchmarking. As the total number of changed pixels in each 8×8 region can range from 0 to 64, we use 65 specially designed video clips to estimate the CPU/GPU overhead information before running the thin-client service. In each video clip, all 8×8 regions are identical in every frame, and the numbers of changed pixels in all 8×8 regions are also identical between two consecutive frames. For instance, every 8×8 region in the video clip No. 30 always has 30 pixels changed between two consecutive frames. As the encoding complexity is the same among all 8×8 regions, we can simply use
to get the CPU and GPU consumption for each 8∗8 region using RFB encoding and JPEG encoding, respectively. Since the CPU/GPU overhead for any 8∗8 region with a certain number of changed pixels has been pre-estimated through benchmarking, this part of the QoE calculation only brings a negligible CPU overhead to the server during running time.
As we mentioned before, the current resource situation on server is a potential constraint. If other applications running on the server have already occupied great amount of CPU or GPU capacity, applying large-scale JPEG encoding is not a good choice since it may result in overload problem. Let f_cpu denote the current free capacity of CPU, and let f_gpu denote the current free capacity of GPU. We define the weight factor of CPU, w c , and that of GPU, w g , as below:
w c is less than or equal to 1 given that the CPU capacity required by JPEG encoding does exceed the current free capacity, and the same for w g . Then we define the ij th resource consumption factor \(\mathit{QoE}_{\mathit{R\_ij}}\) as follows:
where the value ‘0’ in the formula denotes that RFB encoding does not require GPU.
Another QoE factor in our system is the bandwidth consumption. Let \(b_{\mathit{JPEG\_ij}}\) denote the size of encoded JPEG data in ij th region, and let \(b_{\mathit{RFB\_ij}}\) be the size of encoded RFB result in ij th region. Based on user’s preference on the JPEG quality, we can easily get the file size of the full-screen JPEG image represented as \(\sum_{i,j} b_{\mathit{JPEG\_ij}}\). The size of the RFB result depends on the number of pixels changed between neighboring frames. Given the number of changed pixels, we can also get the expected bandwidth consumption \(\sum _{i,j} b_{\mathit{RFB\_ij}}\) in a full-screen mode through benchmarking. Then we use \(b_{\mathit{RFB\_ij}} = \frac{\sum_{i,j} b_{\mathit{RFB\_ij}}}{i \times j}\) and \(b_{\mathit{JPEG\_ij}} = \frac{\sum_{i,j} b_{\mathit{JPEG\_ij}}}{i \times j}\) to get the bandwidth consumption for encoding ij th region with RFB and JPEG, respectively. Similarly, we define the weight factor of network bandwidth w b to address the possible constraint:
where f_bandwidth denotes the current available bandwidth, which can be provided by user. According to Eq. (3), w b is greater than 1 if the size of RFB result is too large to be sent over the network with limited bandwidth. Then we define the ij th bandwidth consumption factor \(\mathit{QoE}_{\mathit{B\_ij}}\) as follows:
The final step is to calculate the ij th QoE factor, q ij , using two factors and one tunable weight parameter w. The formula is given in Eq. (5). The tuning of w can be done with different considerations. For example, a larger value assigned to w denotes that the bandwidth consumption is more emphasized, and will result in a larger high-motion region and smaller slow-motion region.
4.2 Sub-matrix with maximum summation
After generating the QoE difference value for each 8∗8 region, we get a QoE matrix Q={q ij }. For any q ij , a positive value means that applying JPEG encoding to the corresponding region is more beneficial. As JPEG image must be rectangular, we use dynamic programming method to find the sub-matrix with maximum summation from Q. The pseudo-code of the dynamic programming algorithm is shown in Fig. 4.

Pseudo-code of dynamic programming solution
The time complexity of the dynamic programming solution is Q(n 3) where n 2 denotes the total number of matrix element. It is also possible to find several non-overlapping high-motion regions by repeating the code in Fig. 4. After each loop, the algorithm also need to set ‘−∞’ to the elements in the previously identified sub-matrix.
5 Implementation and simulation
In this section, we first introduce a four-module-four-thread implementation method in Windows. Then we present the comparison of proposed hybrid display protocol with existing solutions.
5.1 Implementation
In the whole program, we use four threads to improve the processing speed. The threads have been designed in a nearly independent way so that parallelism is achieved. They use a global buffer to communicate with each other, and work in an asynchronous way. Once the new data is generated, the old data in the global buffer is discarded to guarantee that only the latest frame is encoded and transmitted to the client. Our model supports parallel execution on memory copy, GPU, CPU, and network I/O. We combine the screen capturing module and motion detection module into one thread since each of them consumes only small amount of computing resource. As GPU and the CPU can work at the same time, we divide encoding module into two threads. Figure 5 shows the four-module-four-thread implementation.

Four-module-four-thread implementation
5.2 Simulation
In these simulations, we compared the performance of our proposed hybrid remote display protocol with that of existing protocols. In this paper, the advantage of mobile thin clients is evaluated by the size of data transmission from server to client which is represented by bandwidth network consumption. If the network bandwidth consumption of our solution is less than the previous methods while the performance of video is preserved, we can conclude that our outperforms the others in supporting the mobile thin client. Table 1 shows the hardware/software environment according to which we conducted the simulations. We chose normal file operation and Video Player (AVI file, 320×200 or 640×480, 30 frames/sec) as the testing applications. Since we support not only thin client but also mobile client, we implement thin client in both environments: PC thin client and mobile thin client (Android tablet). In the tablet, we use the PocketCloud application as RDP and RemoteFX client, androidVNC as Tight/Ultra VNC client, and CPU monitor to measure CPU usage in the Android tablet.
5.2.1 Comparisons in static environment
The first group of comparisons was done regarding three aspects: (i) network bandwidth consumption, (ii) client-side CPU consumption and, (iii) quality of video. The quality of JPEG was set as 50 during the simulation. The results are the average values observed over 5 minutes.
Figure 6 shows the network bandwidth consumption results in three different scenarios. In a slow-motion scenario, RDP and RemoteFX perform better than the others since they do not transmit images for normal windows operation. However, the network consumption of RDP [4], RemoteFX [15], and UltraVNC [23] dramatically increase when the data becomes high-motion. In high-motion mode, we conduct the experiment with the same application running with different size of window. As we can see, RDP and RemoteFX are still better than UltraVNC probably because they adopt better compression algorithms. TightVNC [10] does not consume much bandwidth, but results in extremely low quality of video. Most of the information has not been delivered by TightVNC. Our proposed method (Hybrid) outperforms in bandwidth consumption in the high-motion mode. Hybrid consumes less bandwidth network than others, even the size of the window is adjusted. Compared with the high-motion small window, the bandwidth consumption of Hybrid is increased trivially while others require an enormous amount of bandwidth network in the high-motion large window.

Bandwidth consumption of different protocols
Figure 7 depicts the quality of video results in three different scenarios. We used the slow-motion technique [24] to measure the quality of video. Among these protocols, TightVNC provides the worst quality of video especially in high-motion scenario. RDP, RemoteFX and UltraVNC do not perform well when the testing environment is high-motion and large window size. Our approach has a consistent and excellent performance for all cases. As a conclusion, our approach outperforms existing solutions by saving a huge amount of bandwidth while preserving the quality of video.

Quality of video of different protocols
Figures 8a and 8b show that the PC thin-client and mobile thin-client (tablet) CPU consumption results in three different scenarios, respectively. In Fig. 8a, TightVNC is the most inefficient protocol regarding the client-side CPU consumption. In Fig. 8b, Ultra VNC and our proposed method consume less CPU usage than the remained methods in slow-motion mode because of comparing the difference between two successive frames. In high-motion large window mode, the Ultra VNC consumes a small amount of CPU usage because the number of transmitted frames per second is reduced. However, compared with RDP, RemoteFX, and UltraVNC, our approach consumes a similar amount of CPU capacity on the PC and mobile client side.

PC thin client-side CPU consumption of different protocols

Mobile thin client-side CPU consumption of different protocols
5.2.2 Comparisons with high-motion scaling
In the second group of experiment, we first did some file operations, and then opened the media player with window size 640×480. Finally, the high-motion region was reduced to 320×240.
Figure 9 shows the bandwidth consumption comparison during the simulation process. In the slow-motion case, a pure MPEG and pure M-JPEG approach cannot provide an efficient solution due to the whole screen encoding. Other solutions including RDP [4], RealVNC [25], MPEG+VNC [8], and M-JPEG+VNC perform equally well since they only encode and transmit the changed pixels. When the media player application is started, RDP and RealVNC begin to occupy a huge amount of bandwidth. We also figure that the lower bandwidth consumption for RealVNC is associated with the low frame rate at client side. The pure MPEG and M-JPEG encoding techniques remain the same bandwidth consumption all the time. The hybrid solutions show the superiority achieved by dynamically adjusting the encoding screen updates. If the bandwidth consumption is the only factor that need to be considered, MPEG+VNC solution is better than M-JPEG+VNC.

Bandwidth consumption of different protocols during the whole process
Figure 10 presents the client CPU consumption results collected in the same period. Although MPEG-based solutions have good performance regarding bandwidth consumption, their client CPU overhead is much higher than the others. Except MPEG-based decoding, 20 % is the maximum CPU consumption that we observed during the simulation. The average value of pure M-JPEG decoding CPU overhead is between 13–14 %, while it is less than 10 % for M-JPEG and VNC hybrid. With pure consideration of client CPU, RealVNC is the best among all remote display protocols.

Client CPU consumption of different protocols during the whole process
The response time of different protocols can be found in Fig. 11. Since the simulation is conducted with loose network constraint, the response time is closely related to the encoding time. As we can see from Fig. 11, the MPEG encoding is time-consuming even if the MPEG encoder card has been used. To encode single frame, our solution consumes 10–20 ms more than RDP and RealVNC. Even though the total encoding time for one frame is more than 60 ms, the average per frame encoding time has been reduced to 28 ms since we have implemented multi-thread programming, which means the frames can be encoded in a parallel way.

Response time of different protocols during the whole process
Figure 12 presents the comparison on average per frame encoding time between single-thread program and multi-thread program. We first open a media player with window size 640×480, and then scale it down to 320×240. The results show that the efficiency has been significantly improved by adopting multi-thread programming. Meanwhile, the observed per frame encoding time is less than 40 ms, which means our encoder has the potential to support a larger window size on the test machine.

Average encoding time for multi-thread and single-thread
In order to show that the proposed motion detection algorithm does not create much CPU overhead, we remove the encoding part and only retain the motion detection approach running on the server. The results presented in Fig. 13 are generated from a lightly loaded server and heavily loaded server. As we can see, there is no obvious difference between the server running motion detection algorithm and the one without running it in both lightly loaded and heavily loaded situations. This observation proves that our motion detection algorithm, including QoE calculation and high-motion region determination, is a light-weight approach and suitable for heavily loaded server as well.

CPU overhead for motion detection
6 Conclusion
In this paper, a novel hybrid remote display design for the mobile thin-client system is proposed. We use the RFB protocol to handle a slow-motion remote display task and M-JPEG for high-motion display. Graphic processing units (GPU) have been utilized to do a part of the JPEG compression task. We also propose a transparent motion detection algorithm to reduce the network bandwidth consumption and the server-side computing resource consumption. The continuity of screen delivery is always preserved even if the JPEG compression is applied to a different screen region. A four-module-four-thread implementation method is presented in this paper as well. The multi-thread design greatly reduces the whole compression time by running tasks in parallel among memory, CPU, GPU, and Network I/O.
In order to conclude our work with a clear demonstration of advantages and disadvantages, we compare our work with several well-known approaches in Table 2. It shows that our approach has many good features and two limitations, including lossy compression and extra hardware requirement, which are very similar to the VNC-MPEG hybrid approach. The difference is that our proposal consumes less computing resources on both server side and client side as compared to VNC-MPEG, but the bandwidth consumption is not the best.
In the future, we plan to investigate the possibility of using cheap M-JPEG encoding hardware to further reduce the server-side cost.
References
Simoens P, Joveski B, Gardenghi L, Marshall I, Vankeirsbilck B, Mitrea M, Preteux F, De Turck F, Dhoedt B (2011) Optimized mobile thin clients through a MPEG-4 BiFS semantic remote display framework. Multimed Tools Appl, 1–24
Boukerche A, Pazzi RWN, Feng J (2008) An end-to-end virtual environment streaming technique for thin mobile devices over heterogeneous networks. Comput Commun 31(11):2716–2725
Koller D, Turitzin M, Levoy M, Tarini M, Croccia G, Cignoni P, Scopigno R (2004) Protected interactive 3D graphics via remote rendering. ACM Trans Graph 23(3):695–703
Microsoft remote desktop protocol: basic connectivity and graphics remoting specification (May 2013). http://msdn2.microsoft.com/en-us/library/cc240445.aspx
Richardson T, Stafford-Fraser Q, Wood K, Hopper A (1998) Virtual network computing. Internet Comput 2(1):33–38
Citrix Xendesktop (May 2013). http://www.citrix.com/products/xendesktop/overview.html
Baratto R (2011) THINC: a virtual and remote display architecture for desktop computing and mobile devices. PhD Thesis, Department of Computer Science, Columbia University, April 2011
Simoens P, Praet P, Vankeirsbilck B, De Wachter J, Deboosere L, De Turck F, Dhoedt B, Demeester P (2008) Design and implementation of a hybrid remote display protocol to optimize multimedia experience on thin client devices. In: Australian telecommunication networks and applications conference, 2008. ATNAC 2008, 7–10 December, pp 391–396
Tan K-J, Gong J-W, Wu B-T, Chang D-C, Li H-Y, Hsiao Y-M, Chen Y-C, Lo S-W, Chu Y-S, Guo J-I (2010) A remote thin client system for real time multimedia streaming over VNC. In: 2010 IEEE international conference on multimedia and expo (ICME), 19–23 July, pp 992–997
TightVNC (May 2013). http://www.tightvnc.com/
TurboVNC (May 2013). http://www.virtualgl.org/Downloads/TurboVNC
MJPEG vs MPEG4 (2006) White paper, On-Net Surveillance Systems Inc
From tight to turbo and back again: designing a better encoding method for TurboVNC. Version 2a, the VirtualGL project, 2012
CUDA (May 2013). http://www.nvidia.com/object/cuda_home_new.html
RemoteFX (May 2013). http://en.wikipedia.org/wiki/RemoteFX
Gotomypc (May 2013). http://www.gotomypc.com/
Laplink (May 2013). http://www.laplink.com/
Pc anywhere (May 2013). http://www.anyplace-control.com/pcanywhere.shtml
Nieh J, Yang S, Novik N et al (2000) A comparison of thin-client computing architectures. Technical Report CUCS-022-00, Department of Computer Science, Columbia University, Tech Rep
Deboosere L, De Wachter J, Simoens P, De Turck F, Dhoedt B, Demeester P (2007) Thin client computing solutions in low- and high-motion scenarios. In: Third international conference on networking and services, 2007. ICNS, 19–25 June, p 38
ITU-T: h.264 (2005) Advanced video coding for generic audiovisual services
Schulzrinne H, Casner S, Frederick R, Jacobson V (May 2013) RTP: a transport protocol for real-time applications. RFC 3550 (Standard). [Online]. Available: http://www.ietf.org/rfc/rfc3550.txt
Ultra VNC (May 2013). http://www.uvnc.com/
Nieh J, Yang SJ, Novik N (2003) Measuring thin-client performance using slow-motion benchmarking. ACM Trans Comput Syst 21(1):87–115
Real VNC (May 2013). http://www.realvnc.com/
Acknowledgements
This research was supported by Next-Generation Information Computing Development Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (2012–0006418). Professor Eui-Nam Huh is corresponding author.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Song, B., Tang, W., Nguyen, TD. et al. An optimized hybrid remote display protocol using GPU-assisted M-JPEG encoding and novel high-motion detection algorithm. J Supercomput 66, 1729–1748 (2013). https://doi.org/10.1007/s11227-013-0972-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-013-0972-1