
Abstract
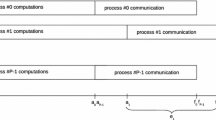
Reduction algorithms are optimized only under the assumption that all processes commence the reduction simultaneously. Research on process arrival times has shown that this is rarely the case. Thus, all benchmarking methodologies that take into account only balanced arrival times might not portray a true picture of real-world algorithm performance. In this paper, we select a subset of four reduction algorithms frequently used by library implementations and evaluate their performance for both balanced and imbalanced process arrival times. The main contribution of this paper is a novel imbalance robust algorithm that uses pre-knowledge of process arrival times to construct reduction schedules. The performance of selected algorithms was empirically evaluated on a 128 node subset of the Partnership for Advanced Computing in Europe CURIE supercomputer. The reported results show that the new imbalance robust algorithm universally outperforms all the selected algorithms, whenever the reduction schedule is precomputed. We find that when the cost of schedule construction is included in the total runtime, the new algorithm outperforms the selected algorithms for problem sizes greater than 1 MiB.













Similar content being viewed by others


Notes
Helsim is an electromagnetic explicit 3D in situ-visualized resilient particle-in-cell simulator, developed in the Leuven Intel ExaScale Lab, Belgium. It is a combined multidisciplinary effort integrating astrophysics, linear solvers, runtime environment, in situ visualization and architectural optimization-focused simulations. It was developed to be a proto-app, showing a realistic example of trade-offs between computation and communication on a small, manageable code base with modern implementation techniques. It was implemented in C\(++\)11 utilizing the inlab Shark PGAS library for all distributed data structures and the Cobra library for load balancing and resiliency.
VSC muk is a tier-1 cluster machine at the Flemish Supercomputing Center. It has 528 compute nodes with two Xeon E5-2670 processors and 64 GiB of RAM memory. The nodes are interconnected with an FDR Infiniband interconnect in a fat tree topology (1:2 oversubscription).
References
Meneses E, Kal LV (2015) Camel: collective-aware message logging. J Supercomput 71(7):2516–2538. doi:10.1007/s11227-015-1402-3
Ferreira KB, Bridges P, Brightwell R (2008) Characterizing application sensitivity to OS interference using kernel-level noise injection. In: Proceedings of the 2008 ACM/IEEE conference on supercomputing (SC’08). IEEE Press, Piscataway, pp 19:1–19:12
Faraj A, Patarasuk P, Yuan X (2008) A study of process arrival patterns for MPI collective operations. Int J Parallel Program 36(6):571–591
Huang C, Lawlor O, Kale LV (2004) Adaptive MPI. In: Languages and compilers for parallel computing. Springer, New York, pp 306–322
Mamidala A, Liu J, Panda DK (2004) Efficient barrier and allreduce on infiniband clusters using multicast and adaptive algorithms. In: Proceedings of the 2004 IEEE international conference on cluster computing (CLUSTER’04). IEEE Computer Society, Washington, DC, pp 135–144
Patarasuk P, Yuan X (2008) Efficient MPI bcast across different process arrival patterns. Parallel Distrib Process Symp Int 0:1–11. http://doi.ieeecomputersociety.org/10.1109/IPDPS.2008.4536308
Qian Y (2010) Design and evaluation of efficient collective communications on modern interconnects and multi-core clusters. Ph.D. thesis, Queen’s University, Kingston
Message Passing Interface Forum, \({\sf MPI}\) (2016) A Message-Passing Interface Standard. Version 3.1. http://www.mpi-forum.org/docs/mpi-3.1/. Accessed 4 June 2015
Karp RM, Sahay A, Santos EE, Schauser KE (1993) Optimal broadcast and summation in the LogP model. In: Proceedings of the fifth annual ACM symposium on parallel algorithms and architectures. ACM, New York, pp 142–153
Louis-Claude Canon GA (2012) Scheduling associative reductions with homogenous costs when overlapping communications and computations. Tech. Rep. 7898, Inria
Rabenseifner R (2004) Optimization of collective reduction operations. In: Procs. of int. conf. on computational science (ICCS), pp 1–9
Rabenseifner R, Trff JL (2004) More efficient reduction algorithms for non-power-of-two number of processors in message-passing parallel systems. In: EuroPVM/MPI, pp 36–46
Patarasuk P, Yuan X (2009) Bandwidth optimal all-reduce algorithms for clusters of workstations. J Parallel Distrib Comput 69(2):117–124
Jain N, Sabharwal Y (2010) Optimal bucket algorithms for large MPI collectives on torus interconnects. In: Proceedings of the 24th ACM international conference on supercomputing. ACM, New York, pp 27–36
Chan E, Heimlich M, Purkayastha A, van de Geijn R (2007) Collective communication: theory, practice, and experience. Concurr Comput Pract Exp 19(13):1749–1783
Peterka T, Goodell D, Ross R, Shen H-W, Thakur R (2009) A configurable algorithm for parallel image-compositing applications. In: Proceedings of the conference on high performance computing networking, storage and analysis (SC’09). ACM, New York, pp 4:1–4:10. doi:10.1145/1654059.1654064
Kendall W, Peterka T, Huang J, Shen H-W, Ross R (2010) Accelerating and benchmarking Radix-\(k\) image compositing at large scale. In: Proceedings of the 10th eurographics conference on parallel graphics and visualization (EG PGV’10). Eurographics Association, Aire-la-Ville, pp 101–110. doi:10.2312/EGPGV/EGPGV10/101-110
Pjesivac-Grbovic J, Angskun T, Bosilca G, Fagg GE, Dongarra GJJ (2005) Performance analysis of MPI collective operations. In: IEEE international parallel and distributed processing symposium
Sanders P, Speck J, Trff JL (2009) Two-tree algorithms for full bandwidth broadcast, reduction and scan. Parallel Comput 35(12):581–594. (Selected papers from the 14th European PVM/MPI users group meeting)
Thakur R, Rabenseifner R, Gropp W (2005) Optimization of collective communication operations in MPICH. Int J High Perform Comput Appl 19(1):49–66
Hoefler T, Moor D (2014) Energy, memory, and runtime tradeoffs for implementing collective communication operations. J Supercomput Front Innov 1(2):58–75
Fabrizio Petrini SP, Kerbyson Darren J (2003) The case of the missing supercomputer performance: achieving optimal performance on the 8,192 processors of ASCI Q. In: Proceedings of the 2003 ACM/IEEE conference on supercomputing (SC’03), p 55
Agarwal S, Garg R, Vishnoi NK (2005) The impact of noise on the scaling of collectives: a theoretical approach. In: Proceedings of the 12th international conference on high performance computing (HiPC’05). Springer, Berlin, pp 280–289. doi:10.1007/11602569_31
Hoefler T, Schneider T, Lumsdaine A (2010) Characterizing the influence of system noise on large-scale applications by simulation. In: Proceedings of the 2010 ACM/IEEE international conference for high performance computing, networking, storage and analysis (SC’10). IEEE Computer Society, Washington, DC, pp 1–11. doi:10.1109/SC.2010.12
Ghysels P, Ashby TJ, Meerbergen K, Vanroose W (2013) Hiding global communication latency in the gmres algorithm on massively parallel machines. SIAM J Sci Comput 35(1):C48–C71
Ferreira KB, Bridges PG, Brightwell R, Pedretti KT (2013) The impact of system design parameters on application noise sensitivity. Clust Comput 16(1):117–129
Eichenberger AE, Abraham SG (1995) Impact of load imbalance on the design of software barriers. In: Proceedings of the 1995 international conference on parallel processing, pp 63–72
Marendic P, Lemeire J, Haber T, Vucinic D, Schelkens P (2012) An investigation into the performance of reduction algorithms under load imbalance. In: Kaklamanis C, Papatheodorou T, Spirakis P (eds) Euro-Par 2012 parallel processing. Lecture notes in computer science, vol 7484. Springer, Berlin, pp 439–450. doi:10.1007/978-3-642-32820-6_44
Chan EW, Heimlich MF, Purkayastha A, Van De Geijn RA (2004) On optimizing collective communication. In: 2004 IEEE international conference on cluster computing. IEEE, pp 145–155
Träff JL, Ripke A (2008) Optimal broadcast for fully connected processor-node networks. J Parallel Distrib Comput 68(7):887–901
Lastovetsky A, Rychkov V, OFlynn M, Mpiblib (2008) Benchmarking MPI communications for parallel computing on homogeneous and heterogeneous clusters. In: Recent advances in parallel virtual machine and message passing interface. Springer, New York, pp 227–238
Hockney RW (1994) The communication challenge for MPP: Intel Paragon and Meiko CS-2. Parallel Comput 20(3):389–398. doi:10.1016/S0167-8191(06)80021-9
Fredman ML, Sedgewick R, Sleator DD, Tarjan RE (1986) The pairing heap: a new form of self-adjusting heap. Algorithmica 1(1–4):111–129
Pettie S (2005) Towards a final analysis of pairing heaps. In: 46th annual IEEE symposium on foundations of computer science (FOCS’05). IEEE, pp 174–183
Ma K-L, Painter JS, Hansen CD, Krogh MF (1994) Parallel volume rendering using binary-swap compositing. Comput Graph Appl IEEE 14(4):59–68
Yang D-L, Yu J-C, Chung Y-C (2001) Efficient compositing methods for the sort-last-sparse parallel volume rendering system on distributed memory multicomputers. J Supercomput 18(2):201–220. doi:10.1023/A:1008165001515
Gropp W, Lusk E (1999) Reproducible measurements of MPI performance characteristics. Springer, New York, pp 11–18
Corporation I (2013) Intel MPI benchmarks 4.1. https://software.intel.com/en-us/articles/intel-mpi-benchmarks. Accessed 1 April 2016
Hoefler T, Schneider T, Lumsdaine A (2010) Accurately measuring overhead, communication time and progression of blocking and nonblocking collective operations at massive scale. Int J Parallel Emerg Distrib Syst 25(4):241–258. doi:10.1080/17445760902894688
Hoefler TST, Lumsdaine A (2010) Accurately measuring overhead, communication time and progression of blocking and nonblocking collective operations at massive scale. Int J Parallel Emerg Distrib Syst 25(4):241–258
Gropp W, Lusk E (1999) Reproducible measurements of mpi performance characteristics. In: Recent advances in parallel virtual machine and message passing interface. Springer, New York, pp 11–18
Reussner R, Sanders P, Träff JL, Skampi (2002) A comprehensive benchmark for public benchmarking of MPI. Sci Program 10(1):55–65
Grove DA, Coddington PD (2005) Communication benchmarking and performance modelling of mpi programs on cluster computers. J Supercomput 34(2):201–217
Träff JL (2012) Mpicroscope: towards an MPI benchmark tool for performance guideline verification. In: Recent advances in the message passing interface—proceedings of 19th European MPI users’ group meeting (EuroMPI’12), Austria, pp 100–109. doi:10.1007/978-3-642-33518-1_15
Hunold S, Carpen-Amarie A, Träff JL (2014) Reproducible MPI micro-benchmarking isn’t as easy as you think. In: Proceedings of the 21st European MPI users’ group meeting. ACM, New York, p 69
NIST/SEMATECH (2012) E-handbook of statistical methods. http://www.itl.nist.gov/div898/handbook/. Accessed June 2015
Buranapanichkit D, Deligiannis N, Andreopoulos Y (2015) Convergence of desynchronization primitives in wireless sensor networks: stochastic modeling approach. CoRR. arXiv:1411.2862
Deligiannis N, Mota JF, Smart G, Andreopoulos Y (2015) Fast desynchronization for decentralized multichannel medium access control. IEEE Trans Commun 63(9):3336–3349
Acknowledgments
This work is funded by Intel, the Institute for the Promotion of Innovation through Science and Technology in Flanders (IWT) and by the iMinds institute. Some of the data necessary for the experiments in this paper was produced at the ExaScience Life Lab, Leuven, Belgium. We acknowledge PRACE for awarding us access to resource CURIE based in France at CEA/TGCC-GENCI. Peter Schelkens has received funding from the European Research Council under the European Unions Seventh Framework Programme (FP7/2007-2013)/ERC Grant Agreement No. 617779 (INTERFERE).
Author information
Authors and Affiliations
Corresponding author
Additional information
P. Schelkens: Research director at iMinds.
Appendices
Appendix 1: Algorithm definitions

Appendix 2: Autocorrelograms of Helsim simulation image rendering time
See Fig. 14.

Autocorrelograms of the four principal clusters of image render times across the 100 iterations of the Helsim simulation, for \(P <24\). The data were gathered on the Lynx cluster with \(P =128\) and eight processes per node. In the autocorrelation plots, the green line indicates a \(P =0.95\) significance level, and the red line indicates a \(P =0.99\) significance level
Appendix 3: Radix-k reduction schedule illustration
See Fig. 15.

Example of Radix-k execution for \(P=12\), factored into two rounds \(R=\{4,3\}\). Reprinted from Peterka et al. [16]. Reprinted according to fair use
Appendix 4: Time series data for algorithm parallel ring
See Fig. 16.

Time series data of two independent samples of algorithm parallel ring. Blue color denotes sample 1 and red sample 2. Axis x denotes iteration number, while axis y denotes the observed algorithm runtime in seconds. a Parallel ring, \(I(x) = 1.75\times 10^{-1}\) ms. b Parallel ring, \(I(x) = 2\times 10^{-1}\) ms. c Parallel ring, \(I(x) = 2.25\times 10^{-1}\) ms. d Parallel ring, \(I(x) = 2.5\times 10^{-1}\) ms
Appendix 5: Autocorrelation of time series data for parallel ring
See Fig. 17.

Autocorrelation of time series data of two independent executions of algorithm parallel ring. Green line denotes the 95% confidence level, while the red denotes the 99 % confidence level. a Parallel ring, \(I(x) = 2.5\times 10^{-1}\) ms. Sample 1. b Parallel ring, \(I(x) = 2.5\times 10^{-1}\) ms. Sample 2
Rights and permissions
About this article

Cite this article
Marendic, P., Lemeire, J., Vucinic, D. et al. A novel MPI reduction algorithm resilient to imbalances in process arrival times. J Supercomput 72, 1973–2013 (2016). https://doi.org/10.1007/s11227-016-1707-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-016-1707-x