
Abstract
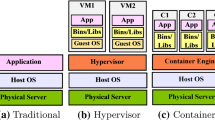
In contrast to the hypervisor-based virtualization method, the container-based scheme does not incur the overhead required by virtual machines since it requires neither a fully abstract hardware stack nor separate guest operating systems (OSes). In this virtualization method, the host OS controls the accesses of the containers to hardware resources. One container can thus be provided with resources such as CPU, memory and network, expectedly isolated from the others. However, due to the lack of architectural support, the last-level cache (LLC) is not utilized in an isolated manner, and thus, it is shared by all containers in the same cloud infrastructure. If a workload of a container leads to cache pollution, it negatively affects the performance of other workloads. To address this problem, we propose an efficient LLC management scheme. By monitoring the memory access pattern, the indirect LLC usage pattern of a container can be figured out. Then, our proposed scheme makes two groups at runtime without using any offline profiling data on containers. The first group is made up of cache-thrashing containers, which fill up the LLC without any temporal locality of data, and the second one consists of normal ones. For isolation, the two separate groups use different partitions of the LLC by the OS-based page coloring method. Our experimental study suggests that the performance of a normal container can be improved by up to 40% in the case of using our proposed scheme.

















Similar content being viewed by others


References
Cgroup Kernel Description (2008) https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt
Cho S, Jin L (2006) Managing Distributed, Shared L2 Caches Through OS-Level Page Allocation. In: Proceedings of the 39th Annual IEEE/ACM International Symposium on Microarchitecture, IEEE Computer Society, Washington, DC, USA, MICRO 39, pp 455–468
Chung MT, Quang-Hung N, Nguyen MT, Thoai N (2016) Using Docker in high performance computing applications. In: 2016 IEEE Sixth International Conference on Communications and Electronics (ICCE), pp 52–57
CoreOS is building a container runtime, rkt (2014) https://coreos.com/blog/rocket/
Cucinotta T, Giani D, Faggioli D, Checconi F (2011) Providing performance guarantees to virtual machines using real-time scheduling. Springer, Berlin, pp 657–664
Datar M, Gionis A, Indyk P, Motwani R (2002) Maintaining stream statistics over sliding windows. In: Proceedings of the Thirteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, SODA ’02, pp 635–644. http://dl.acm.org/citation.cfm?id=545381.545466
Ding X, Wang K, Zhang X (2011) Ulcc: A user-level facility for optimizing shared cache performance on multicores. In: Proceedings of the 16th ACM Symposium on Principles and Practice of Parallel Programming, ACM, New York, NY, USA, PPoPP ’11, pp 103–112
Docker (2013) https://www.docker.com
Funaro L, Ben-Yehuda OA, Schuster A (2016) Ginseng: Market-Driven LLC Allocation. 2016 USENIX Annual Technical Conference (USENIX ATC 16). USENIX Association, Denver, CO, pp 295–308
Guo R, Liao X, Jin H, Yue J, Tan G (2015) Nightwatch: Integrating lightweight and transparent cache pollution control into dynamic memory allocation systems. 2015 USENIX Annual Technical Conference (USENIX ATC 15). USENIX Association, Santa Clara, CA, pp 307–318
Gupta D, Cherkasova L, Gardner R, Vahdat A (2006) Enforcing performance isolation across virtual machines in xen. In: Proceedings of the ACM/IFIP/USENIX 2006 International Conference on Middleware, Springer-Verlag New York, Inc., New York, NY, USA, Middleware ’06, pp 342–362
Gupta S, Zhou H (2015) Spatial locality-aware cache partitioning for effective cache sharing. In: 2015 44th International Conference on Parallel Processing, pp 150–159
Hieu NT, Francesco MD, Jski AY (2014) A virtual machine placement algorithm for balanced resource utilization in cloud data centers. In: 2014 IEEE 7th International Conference on Cloud Computing, pp 474–481. https://doi.org/10.1109/CLOUD.2014.70
Jaleel A, Hasenplaugh W, Qureshi M, Sebot J, Steely S Jr, Emer J (2008) Adaptive insertion policies for managing shared caches. In: Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques, PACT ’08, pp 208–219
Jaleel A, Najaf-abadi HH, Subramaniam S, Steely SC, Emer J (2012) CRUISE: cache replacement and utility-aware scheduling. SIGARCH Comput Archit News 40(1):249–260
Jin H, Qin H, Wu S, Guo X (2015) Ccap: A cache contention-aware virtual machine placement approach for hpc cloud. Int J Parallel Progr 43(3):403–420. https://doi.org/10.1007/s10766-013-0286-1
Joyent URL (2011) https://www.joyent.com/
Kim D, Kim H, Kim NS, Huh J (2015) vcache: Architectural support for transparent and isolated virtual llcs in virtualized environments. In: Proceedings of the 48th International Symposium on Microarchitecture, ACM, New York, NY, USA, MICRO-48, pp 623–634
Kim H, Kandhalu A, Rajkumar R (2013) A coordinated approach for practical os-level cache management in multi-core real-time systems. In: 2013 25th Euromicro Conference on Real-Time Systems, pp 80–89. https://doi.org/10.1109/ECRTS.2013.19
Kim S, Chandra D, Solihin Y (2004) Fair cache sharing and partitioning in a chip multiprocessor architecture. In: Proceedings of the 13th International Conference on Parallel Architectures and Compilation Techniques, IEEE Computer Society, pp 111–122
Lin J, Lu Q, Ding X, Zhang Z, Zhang X, Sadayappan P (2008) Gaining insights into multicore cache partitioning: Bridging the gap between simulation and real systems. In: 2008 IEEE 14th International Symposium on High Performance Computer Architecture, pp 367–378
Lu Q, Lin J, Ding X, Zhang Z, Zhang X, Sadayappan P (2009) Soft-olp: Improving hardware cache performance through software-controlled object-level partitioning. In: 2009 18th International Conference on Parallel Architectures and Compilation Techniques, pp 246–257
LXC (2013) https://linuxcontainers.org/
Morabito R, Kjallman J, Komu M (2015) Hypervisors vs. Lightweight Virtualization: A Performance Comparison. In: 2015 IEEE International Conference on Cloud Engineering, IEEE, pp 386–393
Namespace Kernel Description (2002) http://man7.org/linux/man-pages/man7/namespaces.7.html
Nathuji R, Kansal A, Ghaffarkhah A (2010) Q-clouds: Managing performance interference effects for qos-aware clouds. In: Proceedings of the 5th European Conference on Computer Systems, ACM, New York, NY, USA, EuroSys ’10, pp 237–250
OpenVZ (1999) https://openvz.org
Pendse R, Katta H (1999) Selective prefetching: prefetching when only required. In: 42nd Midwest Symposium on Circuits and Systems (Cat. No.99CH36356), vol 2, pp 866–869
Qureshi MK, Patt YN (2006) Utility-Based Cache Partitioning: A Low-Overhead, High-Performance, Runtime Mechanism to Partition Shared Caches. In: Proceedings of the 39th Annual IEEE/ACM International Symposium on Microarchitecture, IEEE Computer Society, Washington, DC, USA, MICRO 39, pp 423–432
Ranganathan P, Adve S, Jouppi NP (2000) Reconfigurable caches and their application to media processing. SIGARCH Comput Archit News 28(2):214–224
Sandberg A, Eklöv D, Hagersten E (2010) Reducing cache pollution through detection and elimination of non-temporal memory accesses. In: Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Computer Society, Washington, DC, USA, SC ’10, pp 1–11
Seber GA, Lee AJ (2012) Linear regression analysis, vol 936. Wiley, Hoboken
Seshadri V, Mutlu O, Kozuch MA, Mowry TC (2012) The Evicted-address Filter: A Unified Mechanism to Address Both Cache Pollution and Thrashing. In: Proceedings of the 21st International Conference on Parallel Architectures and Compilation Techniques, ACM, New York, NY, USA, PACT ’12, pp 355–366
Sharma P, Kulkarni P, Shenoy P (2016) Per-vm page cache partitioning for cloud computing platforms. In: 2016 8th International Conference on Communication Systems and Networks (COMSNETS), pp 1–8. https://doi.org/10.1109/COMSNETS.2016.7439971
Soares L, Tam D, Stumm M (2008) Reducing the Harmful Effects of Last-level Cache Polluters with an OS-level, Software-only Pollute Buffer. In: Proceedings of the 41st Annual IEEE/ACM International Symposium on Microarchitecture, IEEE Computer Society, Washington, DC, USA, MICRO 41, pp 258–269
Suh GE, Devadas S, Rudolph L (2002) A New Memory Monitoring Scheme for Memory-Aware Scheduling and Partitioning. In: Proceedings of the 8th International Symposium on High-Performance Computer Architecture, IEEE Computer Society, Washington, DC, USA, HPCA ’02, p 117
Suh GE, Rudolph L, Devadas S (2004) Dynamic partitioning of shared cache memory. J Supercomput 28(1):7–26. https://doi.org/10.1023/B:SUPE.0000014800.27383.8f
Tam D, Azimi R, Soares L, Stumm M (2007) Managing shared L2 caches on multicore systems in software. In: Workshop on the Interaction between Operating Systems and Computer Architecture, Citeseer, pp 26–33
Vasić N, Novaković D, Miučin S, Kostić D, Bianchini R (2012) Dejavu: accelerating resource allocation in virtualized environments. SIGARCH Comput Archit News 40(1):423–436
Wolfe A (1994) Software-based cache partitioning for real-time applications. J Comput Softw Eng 2(3):315–327
Wu HY, Chen CC, Tsai HJ, Peng YC, Chen TF (2015) Lifetime-aware LRU promotion policy for last-level cache. In: VLSI Design, Automation and Test (VLSI-DAT), pp 1–4
Xiao Z, Song W, Chen Q (2013) Dynamic resource allocation using virtual machines for cloud computing environment. IEEE Trans Parallel Distrib Syst 24:1107–1117
Ye Y, West R, Cheng Z, Li Y (2014) COLORIS: A Dynamic Cache Partitioning System Using Page Coloring. In: Proceedings of the 23rd International Conference on Parallel Architectures and Compilation, ACM, New York, NY, USA, PACT ’14, pp 381–392
Zhang X, Dwarkadas S, Shen K (2009) Towards Practical Page Coloring-based Multicore Cache Management. In: Proceedings of the 4th ACM European Conference on Computer Systems, ACM, New York, NY, USA, EuroSys ’09, pp 89–102
Zhuravlev S, Blagodurov S, Fedorova A (2010) Addressing shared resource contention in multicore processors via scheduling. SIGPLAN Not, pp 129–142
Acknowledgements
This research was supported by (1) the DMC center at Samsung Electronics and by the National Research Foundation (NRF) Grant NRF-2013R1A1A2064629. It was also partly supported by (2) Institute for Information and Communications Technology Promotion (IITP) Grant funded by the Korea government (MSIP) (R0190-16-2012, High-Performance Big Data Analytics Platform Performance Acceleration Technologies Development) and partly supported by (3) the National Research Foundation (NRF) Grant (NRF-2016M3C4A7952587, PF Class Heterogeneous High-Performance Computer Development). In addition, this work was partly supported by (4) BK21 Plus for Pioneers in Innovative Computing (Dept. of Computer Science and Engineering, SNU) funded by National Research Foundation of Korea (NRF) (21A20151113068), and this research was supported by (5) the Korea government (MSIP) (NRF-2017R1A2B4004513, Optimizing GPGPU virtualization in multi-GPGPU environments through kernels concurrent execution-aware scheduling (National Research Foundation of Korea (NRF) Grant funded by the Korea government (MSIP)). At last, this work was supported by (6) Institute for Information and Communications Technology promotion (IITP) Grant funded by the Korea government (MSIP) (2017-0-01733, General Purpose Secure Database Platform Using a Private Blockchain).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sung, H., Kim, M., Min, J. et al. OLM: online LLC management for container-based cloud service. J Supercomput 74, 637–664 (2018). https://doi.org/10.1007/s11227-017-2181-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-017-2181-9