
Abstract
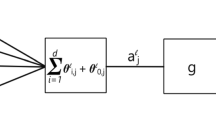
Textons refer to fundamental micro-structures in natural images (and videos) and are considered as the atoms of pre-attentive human visual perception (Julesz, 1981). Unfortunately, the word “texton” remains a vague concept in the literature for lack of a good mathematical model. In this article, we first present a three-level generative image model for learning textons from texture images. In this model, an image is a superposition of a number of image bases selected from an over-complete dictionary including various Gabor and Laplacian of Gaussian functions at various locations, scales, and orientations. These image bases are, in turn, generated by a smaller number of texton elements, selected from a dictionary of textons. By analogy to the waveform-phoneme-word hierarchy in speech, the pixel-base-texton hierarchy presents an increasingly abstract visual description and leads to dimension reduction and variable decoupling. By fitting the generative model to observed images, we can learn the texton dictionary as parameters of the generative model. Then the paper proceeds to study the geometric, dynamic, and photometric structures of the texton representation by further extending the generative model to account for motion and illumination variations. (1) For the geometric structures, a texton consists of a number of image bases with deformable spatial configurations. The geometric structures are learned from static texture images. (2) For the dynamic structures, the motion of a texton is characterized by a Markov chain model in time which sometimes can switch geometric configurations during the movement. We call the moving textons as “motons”. The dynamic models are learned using the trajectories of the textons inferred from video sequence. (3) For photometric structures, a texton represents the set of images of a 3D surface element under varying illuminations and is called a “lighton” in this paper. We adopt an illumination-cone representation where a lighton is a texton triplet. For a given light source, a lighton image is generated as a linear sum of the three texton bases. We present a sequence of experiments for learning the geometric, dynamic, and photometric structures from images and videos, and we also present some comparison studies with K-mean clustering, sparse coding, independent component analysis, and transformed component analysis. We shall discuss how general textons can be learned from generic natural images.
Similar content being viewed by others


Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article
Cite this article
Zhu, SC., Guo, Ce., Wang, Y. et al. What are Textons?. Int J Comput Vision 62, 121–143 (2005). https://doi.org/10.1007/s11263-005-4638-1
Received:
Revised:
Accepted:
Issue Date:
DOI: https://doi.org/10.1007/s11263-005-4638-1