
Abstract
It is a remarkable fact that images are related to objects constituting them. In this paper, we propose to represent images by using objects appearing in them. We introduce the novel concept of object bank (OB), a high-level image representation encoding object appearance and spatial location information in images. OB represents an image based on its response to a large number of pre-trained object detectors, or ‘object filters’, blind to the testing dataset and visual recognition task. Our OB representation demonstrates promising potential in high level image recognition tasks. It significantly outperforms traditional low level image representations in image classification on various benchmark image datasets by using simple, off-the-shelf classification algorithms such as linear SVM and logistic regression. In this paper, we analyze OB in detail, explaining our design choice of OB for achieving its best potential on different types of datasets. We demonstrate that object bank is a high level representation, from which we can easily discover semantic information of unknown images. We provide guidelines for effectively applying OB to high level image recognition tasks where it could be easily compressed for efficient computation in practice and is very robust to various classifiers.
























Similar content being viewed by others



Notes
We also evaluate the classification performance of using the detected object location and its detection score of each object detector as the image representation. The classification performance of this representation is 62.0, 48.3, 25.1 and 54 % on the 15 scene, LabelMe, UIUC-Sports and MIT-Indoor datasets respectively.
The results of these four algorithms are on par with our best result \(84.54\,\%\) achieved by using customized OB (Fig. 19).
Fig. 5 
(Best viewed in colors and magnification) Comparison of classification performance of different features (GIST vs. BOW vs. SPM vs. object bank) and classifiers (SVM vs. LR) on (left to right) 15 scene, LabelMe, UIUC-Sports and MIT-Indoor datasets. In the LabelMe dataset, the ‘ideal’ classification accuracy is \(90\,\%\), where we use the human ground-truth object identities to predict the labels of the scene classes. Performance of previous related algorithms of the original dataset are displayed by using the green bars
The difference is not significant (\(1\,\%\)). One possible reason for this is that there is not much view variance in most of the object detector training data from ImageNet. Majority of the training images are front shots of the objects.
Fig. 8 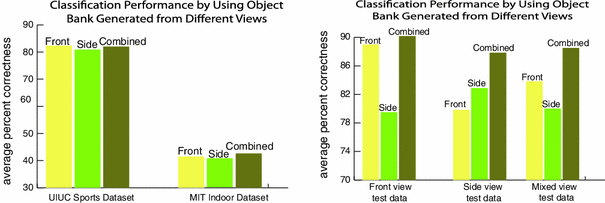
Left Classification performance of object bank generated from detectors trained on images with different view points on the UIUC sports dataset and the MIT Indoor dataset. Right Classification performance of object bank generated from different views on images with different view points
We use Gaussian kernel for smoothing the score.
Fig. 12 
Left Heat map of possible locations estimated from classification performance of Object Bank representation generated from different spatial locations. Right Example images with the possible location map overlaid on the original image
The candidates are ‘sky’, ‘snow’, ‘water’, ‘building’, ‘rock’, ‘mountain’, ‘car’, ‘racquet’, ‘sail-boat’, ‘horse’, ‘human’, ‘boat’, ‘frame’, ‘snowboard’, ‘net’, ‘oar’, ‘wicket’, ‘helmet’, ‘mallet’, ‘window’, ‘cloud’, ‘court’, ‘tree’, ‘grass’, and ‘sand’.
racquet, helmet, window
The fastest feature extraction time of the available code evaluated is 7 s.



References
Bo, L., Ren, X., & Fox, D. (2011, December). Hierarchical matching pursuit for image classification: Architecture and fast algorithms. In Advances in neural information processing systems.
Bosch, A., Zisserman, A., & Munoz, X. (2006). Scene classification via pLSA. Proceedings of ECCV, 4, 517–530.
Bourdev, L., & Malik, J. (2009). Poselets: Body part detectors trained using 3D human pose annotations. In ICCV.
Csurka, G., Bray, C., Dance, C., & Fan, L. (2004). Visual categorization with bags of keypoints. In ECCV: Workshop on Statistical Learning in Computer Vision (pp. 1–22).
Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Vol. 1, p. 886).
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). ImageNet: A large-scale hierarchical image database. In CVPR09 (p. 9).
Desai, C., Ramanan, D., & Fowlkes, C. (2009). Discriminative models for multi-class object layout. In IEEE 12th International Conference on Computer Vision (pp. 229–236). New York: IEEE.
Dixit, M., Rasiwasia, N., & Vasconcelos, N. (2011). Adapted Gaussian models for image classification. In CVPR.
Edition, B., & Sampler, BNC. British National Corpus.
Farhadi, A., Endres, I., & Hoiem, D. (2010). Attribute-centric recognition for cross-category generalization. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 2352–2359). New York: IEEE.
Fei-Fei, L., & Perona, P. (2005). A Bayesian hierarchy model for learning natural scene categories. In Computer Vision and Pattern Recognition.
Fei-Fei, L., Fergus, R., & Perona, P. (2006). One-shot learning of object categories. In IEEE Transactions on Pattern Analysis and Machine Intelligence.
Fei-Fei, L., Fergus, R., & Torralba, A. (2007). Recognizing and learning object categories. Short course CVPR. Retrieved from http://people.csail.mit.edu/torralba/shortCourseRLOC/index.html.
Felzenszwalb, P., Girshick, R., McAllester, D., & Ramanan, D. (2007). Object detection with discriminatively trained part based models. Journal of Artificial Intelligence Research, 29.
Ferrari, V., & Zisserman, A. (2007). Learning visual attributes. In NIPS.
Von Ahn, L. (2006). Games with a purpose. Computer, 39(6), 92–94.
Freeman, W. T., & Adelson, E. H. (1991). The design and use of steerable filters. IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(9), 891–906.
Gao, S., Tsang, I., & Chia, L. T. (2010). Kernel sparse representation for image classification and face recognition. In Computer Vision-ECCV (pp. 1–14). Berlin: Springer.
Gao, S., Chia, L. T., & Tsang, I. W. H. (2011). Multi-layer group sparse coding-for concurrent image classification and annotation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 2809–2816). New York: IEEE.
Gehler, P., & Nowozin, S. (2009). On feature combination for multiclass object classification. In IEEE 12th International Conference on Computer Vision (pp. 221–228). New York: IEEE.
Griffin, G., Holub, A., & Perona, P. (2007). Caltech-256 object category dataset.
Hauptmann, A., Yan, R., Lin, W., Christel, M., & Wactlar, H. (2007). Can high-level concepts fill the semantic gap in video retrieval? A case study with broadcast news. IEEE Transactions on Multimedia, 9(5), 958.
Hoiem, D., & Efros, A. A., & Hebert, M. (2006). Putting objects in perspective. In CVPR (p. 2)
Ide, N., & Macleod, C. (2001). The American National Corpus: A standardized resource of American English. In Proceedings of Corpus Linguistics 2001, Citeseer (pp. 274–280).
Jin, Y., & Geman, S. (2006). Context and hierarchy in a probabilistic image model. In CVPR.
Lampert, C. H., Nickisch, H., & Harmeling, S. (2009). Learning to detect unseen object classes by between-class attribute transfer. In CVPR.
Lazebnik, S., Schmid, C., & Ponce, J. (2006). Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. Urbana: Beckman Institute.
Leung, T., & Malik, J. (2001, June). Representing and recognizing the visual appearance of materials using three-dimensional textons. IJCV, 43(1), 29–44.
Li, L.-J., & Fei-Fei, L. (20007). What, where and who? Classifying events by scene and object recognition. In ICCV.
Li, L.-J., Socher, R., & Fei-Fei, L. (2009). Towards total scene understanding: Classification, annotation and segmentation in an automatic framework. In CVPR.
Li, L.-J., Su, H., Lim, Y., & Fei-Fei, L. (2010). Objects as attributes for scene classification. In (ECCV), Workshop on PaA.
Li, L.-J., Su, H., Xing, E., & Fei-Fei, L. (2010). Object bank: A high-level image representation for scene classification & semantic feature sparsification. In NIPS.
Lowe, D. (1999). Object recognition from local scale-invariant features. In ICCV.
Miller, G. A. (1995). WordNet: A lexical database for English. In Communications of the ACM.
Oliva, A., & Torralba, A. (2001). Modeling the shape of the scene: A holistic representation of the spatial envelope. In IJCV.
Pandey, M., & Lazebnik, S. (2011). Scene recognition and weakly supervised object localization with deformable part-based models. In IEEE International Conference on Computer Vision (ICCV) (pp. 1307–1314). New York: IEEE.
Perona, P., & Malik, J. (1990). Scale-space and edge detection using anisotropic diffusion. PAMI, 12(7), 629–639.
Perronnin, F., Sánchez, J., & Mensink, T. (2010). Improving the fisher kernel for large-scale image classification. Computer Vision-ECCV, 2010, 143–156.
Quattoni, A., & Torralba, A. (2009). Recognizing indoor scenes. In CVPR.
Russell, B. C., Torralba, A., Murphy, K. P., & Freeman, W. T. (2005). Labelme: A database and web-based tool for image, annotation.
Song, Z., Chen, Q., Huang, Z., Hua, Y., & Yan, S. (2011). Contextualizing object detection and classification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Sudderth, E., Torralba, A., Freeman, W. T., & Willsky, A. (2005). Learning hierarchical models of scenes, objects, and parts. In Proceedings of International Conference on Computer Vision.
Torresani, L., Szummer, M., & Fitzgibbon, A. (2010). Efficient object category recognition using classemes. In ECCV.
Tu, Z., Chen, X., Yuille, A. L., & Zhu, S. C. (2005). Image parsing: Unifying segmentation, detection, and recognition. International Journal of Computer Vision, 63(2), 113–140.
Varma, M., & Zisserman, A. (2003). Texture classification: Are filter banks necessary? In CVPR03 (Vol. II, pp. 691–698).
Vogel, J., & Schiele, B. (2004). A semantic typicality measure for natural scene categorization. In DAGM’04 Annual Pattern Recognition Symposium, Tuebingen, Germany.
Wang, J., Yang, J., Yu, K., Lv, F., Huang, T., & Gong, Y. (2010). Locality-constrained linear coding for image classification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3360–3367). New York: IEEE.
Zhu, L., Chen, Y., & Yuille, A. (2007). Unsupervised learning of a probabilistic grammar for object detection and parsing. Advances in neural information processing systems, 19, 1617.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Li, LJ., Su, H., Lim, Y. et al. Object Bank: An Object-Level Image Representation for High-Level Visual Recognition. Int J Comput Vis 107, 20–39 (2014). https://doi.org/10.1007/s11263-013-0660-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-013-0660-x