
Abstract
The replica strategy in traditional distributed file system, which creates a copy mainly from the perspective of internal resources while changes in external demand are ignored. However, this strategy is not suitable for deployment in a service-based, resource-rich internal storage “smart city” in cloud storage center. This paper proposes a replica strategy, which combines data security (the minimum amount of copies) together with service needs (best copy volume). The strategy predicts file popularity based on access pattern mining algorithms. What’s more, the number of copies of the cloud adjusts itself dynamically according to the popularity of file and system resources. Mining algorithm is based on the analysis of the characteristics of spatio-temporal data in smart cities. The algorithm first maps the historical user access request to the spatio-temporal attribute domain. Then according to the geographical area grid and association rules, the correlation analysis and evolution rule identification of access requests are carried out in the domain of spatio-temporal attributes. Finally dig out the user access mode and predict the user’s access request, calculate the file popularity according to the request. The simulation results show that the popularity of the file calculated by the access pattern mining algorithm in this paper is simple and efficient, and the prediction accuracy of the popularity can reach 84%. The dynamic replica mechanism based on popularity has a significant advantage in coping with sudden large-scale concurrent accesses. Meanwhile, compared with the conventional dynamic replicas based on access frequency, the proposed strategy consumes less storage resources.






Similar content being viewed by others

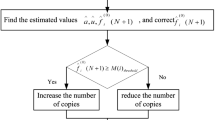
References
Li, J., Chen, S., & WU, C.-z. (2006). Model of data replication strategy based on security in grid. Computer Applications (Chinese), 26(10), 2282–2284.
Hou, M.-S., Wang, X.-B., & Lu, X. (2006). A novel dynamic replication management mechanism. Computer Science, 33(9), 50–51.
Ranganathan, K., & Foster, I. (2003). Identifying dynamie replieation strategies for a high performanee data grid. In Proceeding of the Seeond International workshop on Grid Computing (pp. 75–86), Denver, November 2003.
Tiantian, L., Li Chao, H., & Qingcheng, Z. G. (2011). Multiple-replicas management in the cloud environment. Journal of Computer Research and Development, 48(Supply), 254–260.
Allcock, B., Bester, J., Bresnahan, J., et al. (2001). Secure, efficient data transport and replica management for high performance data-intensive computing. In Proceedings of 18th IEEE symposium on the mass storage systems and technologies.
Wang, X., Yang, S., & Wang, S. (2010). An application based adaptive replica consistency for cloud storage. In Proceedings of the 9th international conference on grid and cloud computing (pp. 13–17), Piscataway, NJ, IEEE.
Carman, M., Zini, F., Serafini, L.,et al. (2002). Towards an economy-based optimisation of file access and replication on a data grid. In Proceedings of 2nd IEEE/ACM international symposium on cluster computing and the grid (CCGrid’2002) (pp. 340–345), Berlin.
Allcock, B., Bester, J., & Bresnahan, J., et al. Secure, efficient data transport and eplica management for high performance data-intensive computing. In Proceedings of eighteenth IEEE symposium on the mass storage systems and technologies.
Xiong, R., Luo, J., Song, A., & Jin, J. (2001). QoS preference-aware replica selection strategy in cloud computing. Journal on Communications (Chinese), 32(7), 93–102.
Wang, X., Yang, S., & Wang, S. (2010). An application-based adaptive replica consistency for cloud storage. In Proceedings of the 9th international conference on grid and cloud computing (pp. 13–17), Piscataway, NJ. IEEE.
Pallis, G., Vakali, A., & Pokorny, J. (2008). A clustering-based prefetching scheme on a Web cache environment. Computers & Electrical Engineering, 34(4), 309–323.
Wan, M., Jönsson, A., Wang, C., et al. (2011). Web user clustering and Web prefetching using Random Indexing with weight functions. Knowledge and Information Systems, 33(1), 89–115.
Cadez, I., Heckerman, D., Meek, C., et al. (2003). Model-based clustering and visualization of navigation patterns on a web site. Data Mining and Knowledge Discovery, 7(4), 399–424.
Perkowitz, M., & Etzioni, O. (1998). Adaptive web sites: Automatically synthesizing web pages. In Proceeding of AAAI-98 (American Association for Artificial Intelligence), (pp. 727–732).
Perkowitz, M., & Etzioni, O. (2000). Adaptive Web sites. Communications of the ACM, 43(10), 152–158.
Mobasher, B., Dai, H., Luo, T., et al. (2001). Effective personalization based on association rule discovery from web usage data. In Proceedings of international workshop on web information & data management.
Matthews, S. G., Gongora, M. A., & Hopgood A. A., et al. (2012). Temporal fuzzy association rule mining with 2-tuple linguistic representation. In IEEE international conference on fuzzy systems (pp. 1–8).
Matthews, S. G., Gongora, M. A., Hopgood, A. A., et al. (2013). Web usage mining with evolutionary extraction of temporal fuzzy association rules. Knowledge-Based Systems, 54(4), 66–72.
Khosravi, M., & Tarokh, M. J. (2010). Dynamic mining of users interest navigation patterns using naive Bayesian method. In: IEEE international conference on intelligent computer communication and processing (pp. 119–122).
Jalali, M., Mustapha, N., Mamat, A., et al. (2008). Web user navigation pattern mining approach based on graph partitioning algorithm. Journal of Theoretical & Applied Information Technology, 33(11), 49–56.
Shahabi, C., & Banaei-Kashani, F. (2001). A framework for efficient and anonymous web usage mining based on client-side tracking. Lecture Notes in Computer Science, 2356, 113–144.
Mobasher, B. (2007). Data mining for web personalization. In P. Brusilovsky, A. Kobsa, & W. Nejdl (Eds.), The adaptive web (pp. 90–135). Berlin: Springer.
Joshi, A., & Krishnapuram, R. (2000). On mining web access logs. In ACM SIGMOD workshop on research issues in data mining & knowledge discovery (pp. 63–69).
Shrivastava, M. V., & Gupta, M. N. (2013). Performance improvement of web usage mining by using learning based k-mean clustering. International Journal of Computer Science and Its Applications, 31(4), 2250–3765.
Wang, T. Z. (2012). The development of web log mining based on improve-K-means clustering analysis. In D. Jin & S. Lin (Eds.), Advances in computer science and information engineering (pp. 613–618). Berlin: Springer.
Calheiros, R. N., Ranjan, R., et al. (2011). CloudSim: a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Software: Practice and experience, 41(1), 23–50.
Che, H., Wang, Z., & Tung, Y. (2001). Analysis and design of hierarchical web caching systems. In Proceedings of the 20th annual joint conference of the IEEE computer and communications societies (INFOCOM 2001) (pp. 1416–1424). Anchorage: IEEE Computer Society.
Tang, X., & Chanson, S. T. (2003). Coordinated management of cascaded caches for efficient content distribution. In Proceedings of the 19th international conference on data engineering (ICDE 2003) (pp. 37–48). Bangalore: IEEE Computer Society.
Tang, X., & Chanson, S. T. (2002). Coordinated en-route web caching. IEEE Transactions on Computers, 51(6), 595–607.
Liu, X., Zhihua, H., & Pan, S. (2016). Control strategy for the number of replica in smart city cloud stroage system. Geomatics and Information Science of Wuhan University (Chinese), 41(9), 1205–1210.
Acknowledgements
This work was supported by the Natural Science Fund of Hubei Province (2018, research on small file merging strategy for massive spatio-temporal data in smart city), The Doctoral Scientific Fund Project of Huanggang Normal University (Grant No. 2013031103). The humanities and social science research project of the Ministry of Education, special project of science and technology personnel research project (No: 13JDGC020); Hubei Provincial Higher Education Research Project (No: 2012376).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, X., Lian, X. Study on Replica Strategy Based on Access Pattern Mining in Smart City Cloud Storage System. Wireless Pers Commun 103, 519–534 (2018). https://doi.org/10.1007/s11277-018-5458-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-018-5458-2