
Abstract
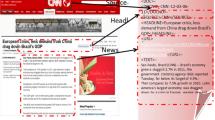
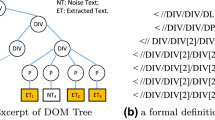
Contents, layout styles, and parse structures of web news pages differ greatly from one page to another. In addition, the layout style and the parse structure of a web news page may change from time to time. For these reasons, how to design features with excellent extraction performances for massive and heterogeneous web news pages is a challenging issue. Our extensive case studies indicate that there is potential relevancy between web content layouts and their tag paths. Inspired by the observation, we design a series of tag path extraction features to extract web news. Because each feature has its own strength, we fuse all those features with the DS (Dempster-Shafer) evidence theory, and then design a content extraction method CEDS. Experimental results on both CleanEval datasets and web news pages selected randomly from well-known websites show that the F 1-score with CEDS is 8.08% and 3.08% higher than existing popular content extraction methods CETR and CEPR-TPR respectively.
Similar content being viewed by others

References
Wu X, Wu G Q, Xie F, Zhu Z, Hu X G. News filtering and summarization on the web. IEEE Intell. Syst., 2010, 25(5): 68-76.
Xu G, Wu Z, Li G, Chen E. Improving contextual advertising matching by using Wikipedia thesaurus knowledge. Knowl. Inf. Syst., 2015, 43(3): 599-631.
Zhou T C, Lyu M R T, King I, Lou J. Learning to suggest questions in social media. Knowl. Inf. Syst., 2015, 43(2): 389-416.
Ferraraa E, De Meob P, Fiumarac G, Baumgartnerd R. Web data extraction, application and techniques: A survey. Knowledge Based Syst., 2014, 70: 301-323.
Adelberg B. NoDoSE — A tool for semi-automatically extracting semistructured data from text documents. In Proc. SIGMOD, June 1998, pp.283-294.
Liu L, Pu C, Han W. XWRAP: An XML-enabled wrapper construction system for web information sources. In Proc. ICDE, Feb. 29-March 3, 2000, pp.611-621.
Bar-Yossef Z, Rajagopalan S. Template detection via data mining and its applications. In Proc. the 11th WWW, May 2002, pp.580-591.
Lin S H, Ho J M. Discovering informative content blocks from web documents. In Proc. the 8th KDD, July 2002, pp.588-593.
Reis D C, Golgher P B, Silva A S, Laender A F. Automatic web news extraction using tree edit distance. In Proc. the 13th WWW, May 2004, pp.502-511.
Finn A, Kushmerick N, Smyth B. Fact or fiction: Content classification for digital libraries. In Proc. DELOS Workshop: Personalization and Recommender Systems in Digital Libraries, June 2001.
Gottron T. Content code blurring: A new approach to content extraction. In Proc. the 19th DEXA, Sept. 2008, pp.29-33.
Weninger T, Hsu W H, Han J. CETR: Content extraction via tag ratios. In Proc. WWW, Apr. 2010, pp.971-980.
Mantratzis C, Orgun M, Cassidy S. Separating XHTML content from navigation clutter using DOM-structure block analysis. In Proc. the 16th HYPEATEXT, Sept. 2005, pp.145-147.
Prasad J, Paepcke A. CoreEx: Content extraction from online news articles. In Proc. the 17th ACM CIKM, Oct. 2008, pp.1391-1392.
Debnath S, Mitra P, Giles C L. Automatic extraction of informative blocks from webpages. In Proc. SAC, Mar. 2005, pp.1722-1726.
Debnath S, Mitra P, Giles C L. Identifying content blocks from web documents. In Proc. the 15th ISMIS, May 2005, pp.285-293.
Cai D, Yu S, Wen J R, Ma W Y. Extracting content structure for web pages based on visual representation. In Proc. the 5th APWeb, Apr. 2003, pp.406-417.
Song D, Sun F, Liao L. A hybrid approach for content extraction with text density and visual importance of DOM nodes. Knowl. Inf. Syst., 2015, 42(1): 75-96.
Beigbeder M, Géry M, Largeron C. Using proximity and tag weights for focused retrieval in structured documents. Knowl. Inf. Syst., 2015, 44(1): 51-76.
Wu G, Wu X. Extracting web news using tag path patterns. In Proc. IEEE/WIC/ACM WI-IAT, Dec. 2012, pp.588-595.
Wu G, Li L, Hu X, Wu X. Web news extraction via path ratios. In Proc. the 22nd CIKM, Aug. 2013, pp.2059-2068.
Furche T, Gottlob G, Grasso G, Schallhart C, Sellers A. OXPath: A language for scalable data extraction, automation, and crawling on the deep web. VLDB J., 2013, 22(1): 47-72.
Hong L, Lynch A. Recursive temporal-spatial information fusion with application to target identification. IEEE Trans. Aero. Elec. Syst., 1993, 29(2): 435-445.
Peters M E, Lecocq D. Content extraction using diverse feature sets. In Proc. the 22nd WWW, May 2013, pp.89-90.
Gibson D, Punera K, Tomkins A. The volume and evolution of web page templates. In Proc. WWW, May 2005, pp.830-839.
Shafer G. A Mathematical Theory of Evidence. Princeton University Press, 1976.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wu, GQ., Li, L., Li, L. et al. Web News Extraction via Tag Path Feature Fusion Using DS Theory. J. Comput. Sci. Technol. 31, 661–672 (2016). https://doi.org/10.1007/s11390-016-1655-1
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11390-016-1655-1