
Abstract
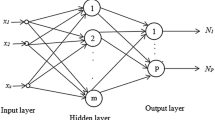
Let SF d and \( \Pi _{\phi ,n,d} = \left\{ {\sum\nolimits_{j = 1}^n {b_j \phi (\omega _j \cdot x + \theta _j ):b_j } ,\theta _j \in \mathbb{R},\omega _j \in \mathbb{R}^d } \right\} \) be the set of periodic and Lebesgue’s square-integrable functions and the set of feedforward neural network (FNN) functions, respectively. Denote by dist (SF d Πϕ,n,d ) the deviation of the set SF d from the set Πϕ,n,d . A main purpose of this paper is to estimate the deviation. In particular, based on the Fourier transforms and the theory of approximation, a lower estimation for dist (SF d Πϕ,n,d ) is proved. That is, dist(SF d Πϕ,n,d ) ⩾ \( \frac{C} {{(n\log _2 n)^{{1 \mathord{\left/ {\vphantom {1 2}} \right. \kern-\nulldelimiterspace} 2}} }} \). The obtained estimation depends only on the number of neuron in the hidden layer, and is independent of the approximated target functions and dimensional number of input. This estimation also reveals the relationship between the approximation rate of FNNs and the topology structure of hidden layer.
Similar content being viewed by others

References
Cybenko G. Approximation by superpositions of a single function. Math Control Sig Syst, 1989, 2: 303–314
Funahashi K. On the approximate realization of continuous mappings by neural networks. Neural Netw, 1989, 2: 183–192
Hornik K, Stinchombe M, White H. Multilayer feedforward networks are universal approximators. Neural Netw, 1989, 2: 359–366
Leshno M, Lin V Y, Pinkus A, et al. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw, 1993, 6: 861–867
Mhaskar H N, Micchelli C A. Approximation by superposition of sigmoidal and radial basis functions. Adv Appl Math, 1992, 13: 350–373
Yoshifusa I. Approximation of functions on a compact set by finite sums of sigmoid function without scaling. Neural Netw, 1991, 4: 817–826
Hornik H. Approximation capabilities of multilayer feedforward networks. Neural Netw, 1991, 4: 251–257
Chen T P, Chen H. Approximation capability to functions of several variables, nonlinear functionals, and operators by radial basis function neural networks. IEEE Trans Neural Netw, 1995, 6: 904–910
Chen T P, Chen H. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Trans Neural Netw, 1995, 6: 911–917
Chen T P. Approximation problems in system identification with neural networks (in Chinese). Sci China Ser A-Math, 1994, 24(1): 1–7
Mhaskar H N, Micchelli C A. Degree of approximation by neural and translation networks with a single hidden layer. Adv Appl Math, 1995, 16: 151–183
Mhaskar H N, Micchelli C A. Dimension independent bounds on the degree of approximation by neural networks. IBM J Res Develop, 1994, 38(3): 277–284
Chui C K, Li X. Approximation by ridge functions and neural networks with one hidden layer. J Approx Theory, 1992, 70: 131–141
Maiorov V, Meir R S. Approximation bounds for smooth functions in C(R d) by neural and mixture networks. IEEE Trans Neural Netw, 1998, 9: 969–978
Kåurkova V, Kainen P C, Kreinovich V. Estimates of the number of hidden units and variation with respect to half-space. Neural Netw, 1997, 10: 1068–1078
Kåurkova V, Sanguineti M. Bounds on rates of variable-basis and neural network approximation. IEEE Trans Inf Theory, 2001, 47(6): 2659–2665
Li X. Simultaneous approximation of multivariate function and their derivatives by neural networks with one hidden layer. Neurocomputing, 1996, 12: 327–343
Chen X H, White H. Improve rates and asymptotic normality for nonparametric neural network estimators. IEEE Trans Inf Theory, 1999, 45: 682–691
Suzuki S. Constructive function approximation by three-layer artificial neural networks. Neural Netw, 1998, 11: 1049–1058
Ritter G. Efficient estimation of neural weights by polynomial approximation. IEEE Trans Inf Theory, 1999, 45: 1541–1550
Maiorov V E. On best approximation by ridge function. J Approx Theory, 1999, 99: 68–94
Kåurkova V, Sanguineti M. Comparison of worst case errors in linear and neural networks approximation. IEEE Trans Inf Theory, 2002, 48: 264–275
Lavretsky E. On the geometric convergence of neural approximations. IEEE Trans Neural Netw, 2002, 13: 274–282
Barron A. Universal approximation bounds for superposition of a sigmoidal function. IEEE Trans Inf Theory, 1993, 39: 930–945
Xu Z B, Cao F L. The essential order of approximation for neural networks. Sci China Ser F-Inf Sci, 2004, 47(1): 97–112
Cao F L, Zhang Y Q, Zhang W G. Neural networks with single hidden layer and the best polynomial approximation (in Chinese). Acta Math Sin, 2007, 50(2): 385–392
Cao F L, Zhang Y Q. Interpolation and approximation by neural networks in distance space (in Chinese). Acta Math Sin, 2008, 51(1): 91–98
Cao F L, Xie T F, Xu Z B. The estimate of approximation error for neural networks: a constructive approach. Neurocomputing, 2008, 71: 626–630
Xu Z B, Cao F L. Simultaneous L p-approximation order for neural networks. Neural Netw, 2005, 18: 914–923
Ditzian Z, Totik V. Moduli of Smoothness. Berlin/New York: Springer-Verlag, 1987. 1–35
Xu Z B, Wang J J. The essential order of approximation for nearly exponential type neural networks. Sci China Ser F-Inf Sci, 2006, 49(4): 446–460
Xie T F, Zhou S P. Approximation Theory of Real Function (in Chinese). Hangzhou: Hangzhou University Press, 1998. 63–71
Author information
Authors and Affiliations
Corresponding author
Additional information
Supported by the National Natural Science Foundation of China (Grant No. 60873206), and the National Basic Research Program of China (Grant No. 2007CB311002)
Rights and permissions
About this article
Cite this article
Cao, F., Zhang, Y. & Xu, Z. Lower estimation of approximation rate for neural networks. Sci. China Ser. F-Inf. Sci. 52, 1321–1327 (2009). https://doi.org/10.1007/s11432-009-0027-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11432-009-0027-7